







 本文详细介绍了快速排序算法,包括其分治思想、如何划分、最佳和最坏情况分析,以及随机化策略。此外,还回顾了其他几种排序算法,如归并排序、插入排序、堆排序等,并探讨了线性时间排序,如计数排序、基数排序和桶排序。最后讨论了快速排序在平均情况下的高效性及其在实际应用中的优势。
本文详细介绍了快速排序算法,包括其分治思想、如何划分、最佳和最坏情况分析,以及随机化策略。此外,还回顾了其他几种排序算法,如归并排序、插入排序、堆排序等,并探讨了线性时间排序,如计数排序、基数排序和桶排序。最后讨论了快速排序在平均情况下的高效性及其在实际应用中的优势。
什么是快速排序
快速排序简介
快速排序(英文名:Quicksort,有时候也叫做划分交换排序)是一个高效的排序算法,由Tony Hoare在1959年发明(1961年公布)。当情况良好时,它可以比主要竞争对手的归并排序和堆排序快上大约两三倍。这是一个分治算法,而且它就在原地排序。
所谓原地排序,就是指在原来的数据区域内进行重排,就像插入排序一般。而归并排序就不一样,它需要额外的空间来进行归并排序操作。为了在线性时间与空间内归并,它不能在线性时间内实现就地排序,原地排序对它来说并不足够。而快速排序的优点就在于它是原地的,也就是说,它很节省内存。
引用一张来自维基百科的能够非常清晰表示快速排序的示意图如下:
快速排序的分治思想
由于快速排序采用了分治算法,所以:
一、分解:本质上快速排序把数据划分成几份,所以快速排序通过选取一个关键数据,再根据它的大小,把原数组分成两个子数组:第一个数组里的数都比这个主元数据小或等于,而另一个数组里的数都比这个主元数据要大或等于。
二、解决:用递归来处理两个子数组的排序。 (也就是说,递归地求上面图示中左半部分,以及递归地求上面图示中右半部分。)
三、合并:因为子数组都是原址排序,所以不需要合并操作,通过上面两步后数组已经排好序了。
所以快速排序的主要思想是递归与划分。
如何划分
当然最重要的是它的复杂度是线性的,也就是 Θ(n) 个划分的子程序。
Partition(A,p,q) // A[p,..q]
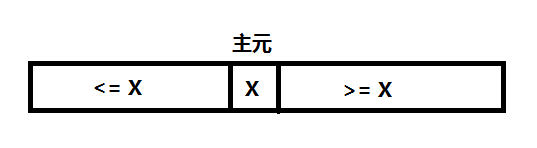
1 x=A[p] // pivot=A[p] 主元
2 i=p
3 for j=p+1 to q
4 do if A[j]<=x
5 then i=i+1
6 exch A[i]<->A[j]
7 exch A[p]<->A[i]
8 return i // i pivot 这就是划分的伪代码,基本的结构就是一个for循环语句,中间加上了一个if条件语句,它实现了对子数组 A[p...q] 的原址排序。
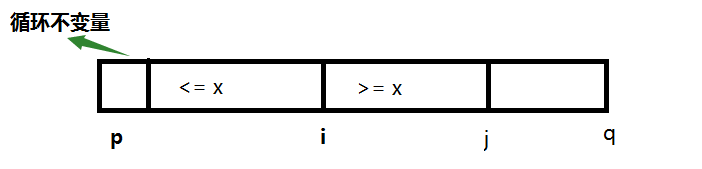
刚开始时 i 等于
那么这个算法在n个数据下的运行时间大约是 O(n) ,因为它几乎把每个数都比较了一遍,而每个步骤所需的时间都为 O(1) 。
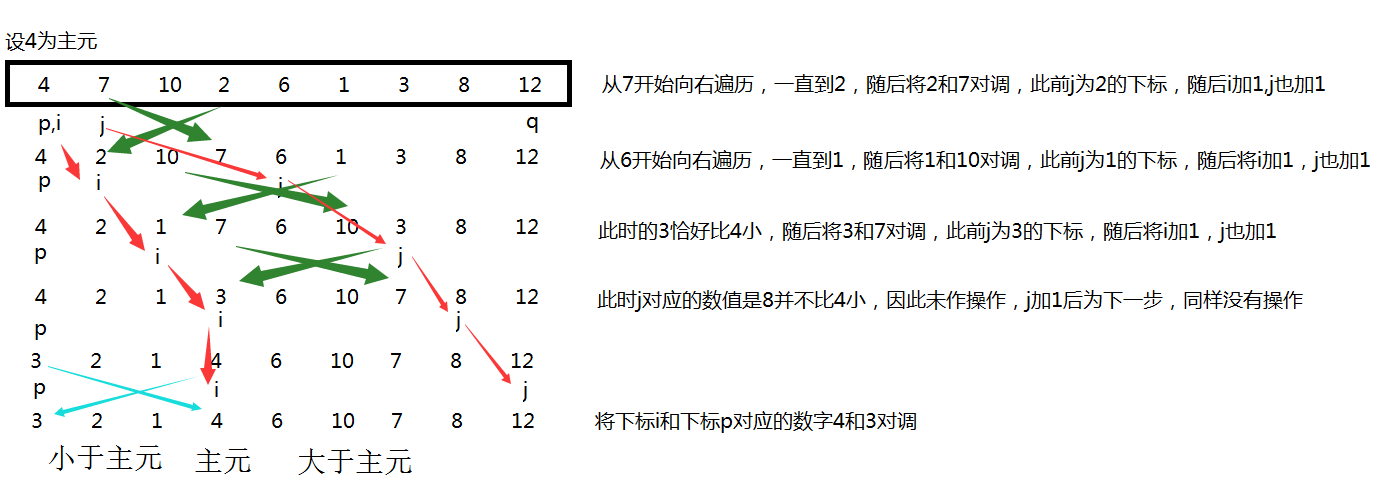
上面这幅图详细的描述了Partition过程,每一行后也加了注释。
将递归的思想作用于划分上
有了上面这些准备工作,再加上分治的思想实现快速排序的伪代码也是很简单的。
Quicksort(A,p,q)
1 if p<q
2 then r=Partition(A,p,q)
3 Quicksort(A,p,r-1)
4 Quicksort(A,r+1,q) 为了排序一个数组A的全部元素,初始调用时 Quicksort(A,1,A.length) 。
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int partition(vector<int> &a, int p, int q) {
int x = a[p];
int i = p;
for (int j = p + 1; j <= q; j++) {
if (a[j] <= x) {
i++;
swap(a[i], a[j]);
}
}
swap(a[i], a[p]);
return i;
}
void quick(vector<int> &a, int p, int q) {
if (p < q) {
int r = partition(a, p, q);
quick(a, p, r - 1);
quick(a, r + 1, q);
}
}快速排序的算法分析
相信通过前面的诸多实践,大家也发现了快速排序的运行时间依赖于Partition过程,也就是依赖于划分是否平衡,而归根结底这还是由于输入的元素决定的。
如果划分是平衡的,那么快速排序算法性能就和归并排序一样。
如果划分是不平衡的,那么快速排序的性能就接近于插入排序。
怎样是最坏的划分
1)输入的元素已经排序或逆向排序
2)每个划分的一边都没有元素
也就是说当划分产生的两个子问题分别包含了n-1个元素和0个元素时,快速排序的最坏情况就发生了。
T(n)=T(0)+T(n−1)+ \Theta(n) =Θ(1)+T(n−1)+Θ(n)=Θ(n−1)+Θ(n)=Θ(n2)
这是一个等差级数,就和插入排序一样。它并不比插入排序快,因为当同样是输入元素已经逆向排好序时,插入算法的运行时间为 Θ(n) 。但快速排序仍旧是一个优秀的算法,这是因为在平均情况下它已经很高效。
我们为最坏情况画一个递归树。
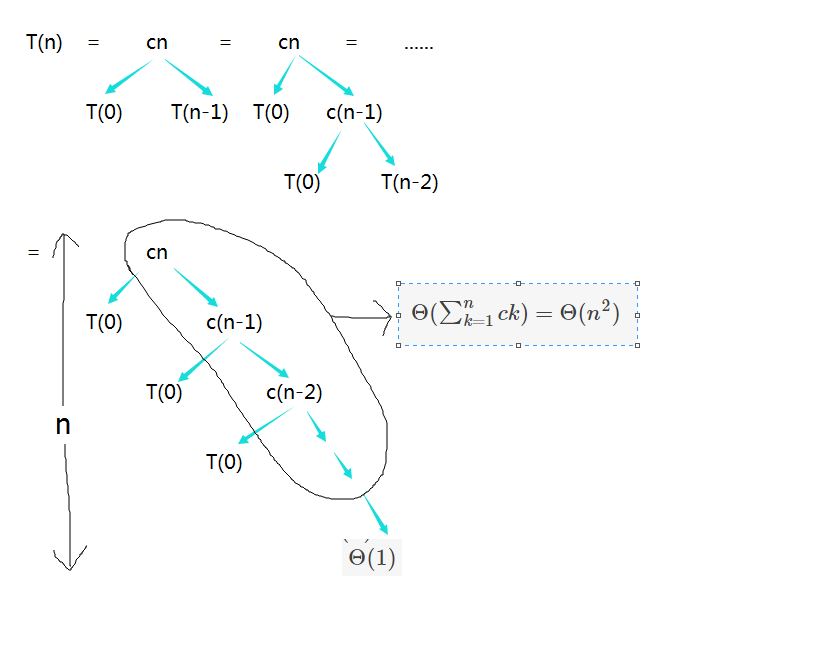
这是一课高度不平衡的递归树,图中左边的那些 T(0) 的运行时间都为 Θ(1) ,而总共有n个。
所以算法的中运行时间为:
T(n)=Θ(n)+Θ(n2)=Θ(n2)
最坏划分的算法分析
通过上面的图示我们知道了在最坏情况下快速排序的复杂度是 Θ(n2) ,但以图示的方式并不是一种严谨的证明方式,我们应该使用代入法来证明它。
当输入规模为n时,时间 T(n) 有如下递归式:
T(n)=max0≤r≤n−1(T(r)+T(n−r−1))+Θ(n)
除去主元后,在Partition函数中生成的两个子问题的规模的和为n-1,所以r的规模才是0到n-1。
假设 T(n)≤cn2 成立,其中c为常数这个大家都知道的。于是上面的递归式为:
T(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









