









转载自 InsideMySQL 公众号,微信公众号不好被搜索引擎收录,所以转载一份备看。
原文地址: https://mp.weixin.qq.com/s/vt7YjxaikJh14pnY2FAWvg 写作时间 2015-07-23
正文
Inside君发现很少有人能够完成讲明白 MySQL 的 Join类型与算法,网上流传着的要提升Join性能,加大变量 join_buffer_size(me:这是个陷阱,一旦全局加大后果可能比较。。)的谬论更是随处可见。当然,也有一些无知的Xxxx(me:减少社区口水,打了马赛克) 攻击MySQL不支持 Hash Join,所以不适合一些分析类的操作。MySQL的确不支持 Hash Join,也不支持 Sort Merge Join,但是MySQL在Join上也有自己的独特的优化与处理,此外,分支版本MariaDB已支持Hash Join,因此拿MySQL来做一些“简单”的分析查询也是完全能够接受的。当然,如果数据量真的上去了,那么即使支持Hash Join的传统MPP架构的关系型数据库可能也是不合适的,这类分析查询或许应该交给更为专业的 Hadoop 集群来计算。
Join 的成本
在讲述MySQL的Join类型与算法前,看看两张表的Join的过程:
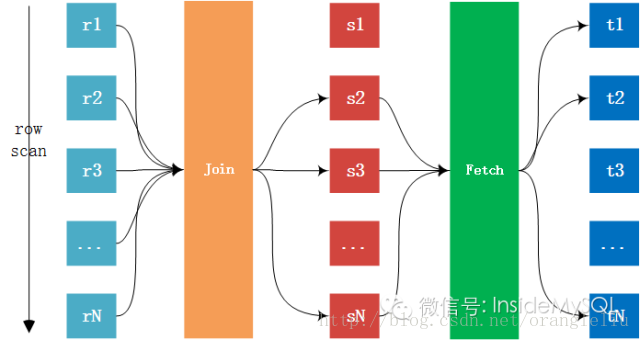
上图的Fetch阶段是指当内表关联的列是辅助索引时,但是需要访问表中的数据,那么这时就需要再访问主键索引才能得到数据的过程,不论表的存储引擎是InnoDB存储引擎还是MyISAM,这都是无法避免的,只是MyISAM的回表速度要快点,因为其辅助索引存放的就是指向记录的指针,而InnoDB存储引擎是索引组织表,需要再次通过索引查找才能定位数据。
Fetch阶段也不是必须存在的,如果是聚集索引链接,那么直接就能得到数据,无需回表,也就没有Fetch这个阶段。另外,上述给出了两张表之间的Join过程,多张表的Join就是继续上述这个过程。
接着计算两张表Join的成本,这里有下列几种概念:
- 外表的扫描次数,记为O。通常外表的扫描次数都是1,即Join时扫描一次驱动表的数据即可
- 内表的扫描次数,记为I。根据不同Join算法,内表的扫描次数不同
- 读取表的记录数,记为R。根据不同Join算法,读取记录的数量可能不同
- Join的比较次数,记为M。根据不同Join算法,比较次数不同
回表的读取记录的数,记为F。若Join的是辅助索引,可能需要回表取得最终的数据
评判一个Join算法是否优劣,就是查看上述这些操作的开销是否比较小。当然,这还要考虑I/O的访问方式,顺序还是随机,总之Join的调优也是门艺术,并非想象的那么简单。
Simple Nested-Loop Join
网上大部分说MySQL只支持Nested-Loop Join,故性能差。但是Nested-Loop join 一定差吗?Hash Join 比 Nested-Loop Join 强?Inside君感觉这样的理解都是片面的,Hash Join可能仅是Nested-Loop Join的一种变种。所以 Inside 君打算从算法的角度来分析 MySQL 支持的 Join ,并以此分析对于 Join 语句的优化。
首先来看 Simple Nested-Loop Join(以下简称SNLJ),也就是最朴素的 Nested-Loop Join,其算法伪代码如下所示:
For each row r in R do
Foreach row s in S do
If r and s satisfy the join condition
Then output the tuple <r,s>(me: 的确很朴素,平时这种for循环嵌套写多了,看起来还挺亲切的)
下图能更好地显示整个SNLJ的过程:

SNLJ的算法相当简单、直接。即外表(驱动表)中的每一条记录与内表中的记录进行判断。但是这个算法也是相当粗暴的,粗暴的原因在于这个算法的开销其实非常大。假设外表的记录数为R,内表的记录数位S,根据上一节Inside君对于Join算法的评判标准来看,SNLJ的开销如下表所示:
| 开销统计 | SNLJ |
|---|---|
| 外表扫描次数:O | 1 |
| 内表扫描次数:I | R |
| 读取记录数:R | R + S*R |
| Join比较次数:M | S*R |
| 回表读取记录次数:F | 0 |
可以看到读取记录数的成本和比较次数的成本都是 S*R ,也就是笛卡儿积。假设外表内表都是1万条记录,那么其读取的记录数量和Join的比较次数都需要上亿。这样的算法开销,Inside君也只能:呵呵。
Index Nested-Loop Join
SNLJ算法虽然简单明了,但是也是相当的粗暴。因此,在Join的优化时候,通常都会建议在内表建立索引,以此降低Nested-Loop Join算法的开销,MySQL数据库中使用较多的就是这种算法,以下称为INLJ。来看这种算法的伪代码:
For each row r in R do
lookupr in S index
if found s == r
Then output the tuple <r,s>由于内表上有索引,所以比较的时候不再需要一条条记录进行比较,而可以通过索引来减少比较,从而加速查询。整个过程如下图所示:
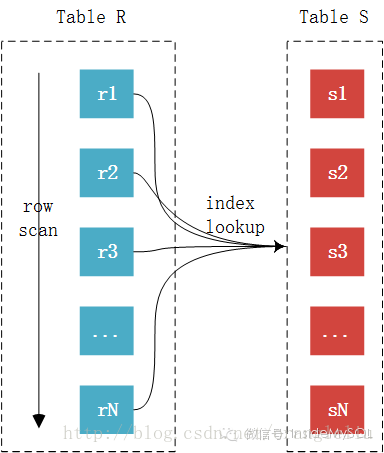
可以看到外表中的每条记录通过内表的索引进行访问,因为索引查询的成本是比较固定的,故优化器都倾向于使用记录数少的表作为外表(这里是否又会存在潜在的问题呢?, 后文有介绍)。故INLJ的算法成本如下表所示:
| 开销统计 | SNLJ | INLJ |
|---|---|---|
| 外表扫描次数:O | 1 | 1 |
| 内表扫描次数:I | R | 0 |
| 读取记录数:R | R + S*R | R + Smatch |
| 比较次数:M | S*R | R * IndexHeight |
| 回表读取记录次数:F | 0 | Smatch (if possible) |
上表 Smatch 表示通过索引找到匹配的记录数量。同时可以发现,通过索引可以大幅降低内表的Join的比较次数,每次比较1条外表的记录,其实就是一次 indexlookup(索引查找),而每次 index lookup的成本就是树的高度,即 IndexHeight
INLJ的算法并不复杂,也算简单易懂。但是效率是否能达到用户的预期呢?其实如果是通过表的主键索引进行Join,即使是大数据量的情况下,INLJ的效率亦是相当不错的。因为索引查找的开销非常小,并且访问模式也是顺序的(假设大多数聚集索引的访问都是比较顺序的)
大部分人诟病MySQL的INLJ慢,主要是因为在进行Join的时候可能用到的索引并不是主键的 聚集索引,而是 辅助索引,这时INLJ的过程又需要多一步Fetch的过程,而且这个过程开销会相当的大:
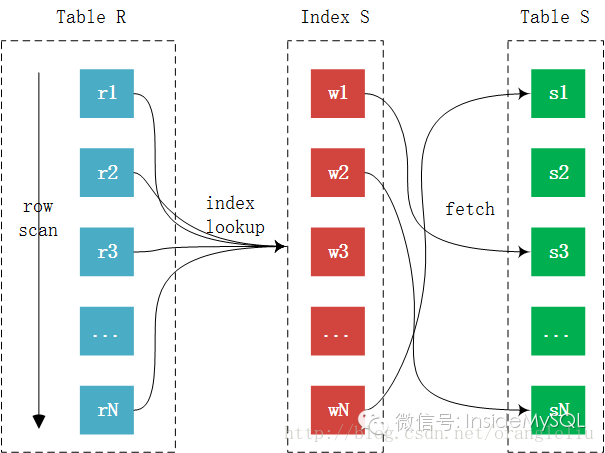
由于访问的是辅助索引,如果查询需要访问聚集索引上的列,那么必要需要进行 回表取数据 (me: 慢就慢在这里o),看似每条记录只是多了一次回表操作。
由于访问的是辅助索引,如果查询需要访问聚集索引上的列,那么必要需要进行回表取数据,看似每条记录只是多了一次回表操作,但这才是 INLJ算法最大的弊端。首先,辅助索引的index lookup是比较随机I/O访问操作。其次,根据index lookup再进行回表又是一个随机的I/O操作。所以说,INLJ最大的弊端是其 可能需要大量的离散操作 ,这在SSD出现之前是最大的瓶颈。而即使SSD的出现大幅提升了随机的访问性能,但是对比顺序I/O,其还是慢了很多,依然不在一个数量级上。例如下面的这个SQL语句:
SELECT COUNT(*) FROMpart, lineitem
WHERE
l_partkey = p_partkey
AND p_retailprice > 2050
AND l_discount > 0.04;其中 p_partkey 是表part的主键,l_partkey 是表lineitem的一个辅助索引,由于表part数据较小,因此作为外表(驱动表)。但是内表Join完成后还需要判断条件 l_discount > 0.04,这个在聚集索引上,故需要回表进行读取。根据explain得到上述SQL的执行计划如下图所示:

Block Nested-Loop Join
算法说明
在有索引的情况下,MySQL会尝试去使用 Index Nested-Loop Join算法,在有些情况下,可能Join的列就是没有索引,那么这时MySQL 的选择绝对不会是最先介绍的 Simple Nested-Loop Join 算法,因为那个算法太粗暴,不忍直视。数据量大些的复杂SQL估计几年都可能跑不出结果,如果你不信,那就是 too young too simple。或者 Inside 君可以给你些SQL跑跑看。
Simple Nested-Loop Join算法的缺点在于其对于内表的扫描次数太多,从而导致扫描的记录太过庞大。Block Nested-Loop Join算法较 Simple Nested-Loop Join 的改进就在于可以减少内表的扫描次数,甚至可以和Hash Join算法一样,仅需扫描内表一次。
接着Inside君带你来看看Block Nested-Loop Join算法的伪代码:
For each tuple r in R do
store used columns as p from R in join buffer
For each tuple s in S do
If p and s satisfy the join condition
Then output the tuple <p,s>可以看到相比 Simple Nested-Loop Join 算法,Block Nested-LoopJoin 算法仅多了一个所谓的 Join Buffer ,然为什么这样就能减少内表的扫描次数呢?下图相比更好地解释了Block Nested-Loop Join算法的运行过程:
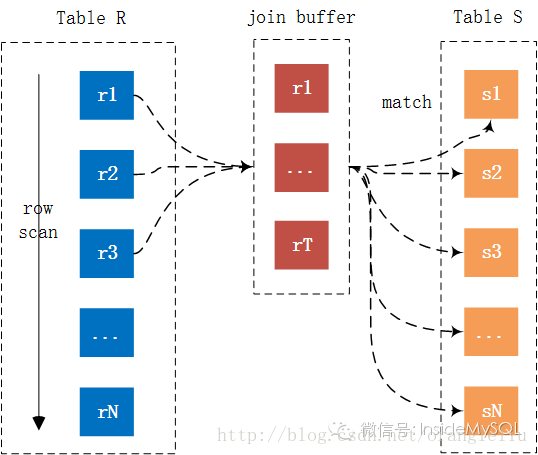
可以看到 Join Buffer 用以缓存链接需要的列,然后以 Join Buffer 批量的形式和内表中的数据进行链接比较。就上图来看,记录 r1,r2 … rT 的链接仅需扫内表一次,如果 join buffer 可以缓存所有的外表列,那么链接仅需扫描内外表各一次,从而大幅提升 Join 的性能。
Join Buffer
变量 join_buffer_size
从上一节中可以发现Join Buffer是用来减少内表扫描次数的一种优化,但Join Buffer又没那么简单,在上一节中Inside君故意忽略了一些实现。
首先变量 join_buffer_size 用来控制Join Buffer的大小,调大后可以避免多次的内表扫描,从而提高性能。也就是说,当MySQL的 Join 有使用到 Block Nested-Loop Join,那么调大变量join_buffer_size 才是有意义的。而前面的 Index Nested-Loop Join如果仅使用索引进行Join,那么调大这个变量则毫无意义。
变量 join_buffer_size 的默认值是256K,显然对于稍复杂的SQL是不够用的。好在这个是会话级别的变量,可以在执行前进行扩展。Inside君建议在会话级别进行设置,而不是全局设置,因为很难给一个通用值去衡量。另外,这个内存是会话级别分配的(me: 这里是有坑的,需要进一步) ,如果设置不好容易导致因无法分配内存而导致的宕机问题。
需要特别注意的是,变量 join_buffer_size 的最大值在MySQL 5.1.22 版本前是 4G,而之后的版本才能在64位操作系统下申请大于 4G 的Join Buffer空间。
Join Buffer缓存的对象
Join Buffer缓存的对象是什么,这个问题相当关键和重要。然在MySQL的官方手册中是这样记录的:
Only columns of interest to the join are stored in the join buffer, not whole rows.
可以发现 Join Buffer 不是缓存外表的整行记录,但是columns of interest具体指的又是什么?Inside君的第一反应是Join的列。为此,Inside君又去查了下mysql internals,查询得到的说明如下所示:
We only store the used columns in the join buffer, not the whole rows.
used columns还是非常模糊。为此,Inside君询问了好友李海翔,也是官方MySQL优化器团队的成员,他答复我的结果是:“所有参与查询的列”都会保存到Join Buffer,而不是只有Join的列。最后,Inside君调试了MySQL,在 sql_join_buffer.cc文件中验证了这个结果。
比如下面的SQL语句,假设没有索引,需要使用到Join Buffer进行链接:
SELECT a.col3 FROM a,b
WHERE a.col1 = b.col2
AND a.col2 > …. AND b.col2 = …假设上述SQL语句的外表是a,内表是b,那么存放在Join Buffer中的列是所有参与查询的列,在这里就是(a.col1,a.col2,a.col3)
通过上面的介绍,我们现在可以得到内表的扫描次数为:
Scaninner_table = (Rn * used_column_size) / join_buffer_size + 1对于有经验的DBA就可以预估需要分配的Join Buffer大小,然后尽量使得内表的扫描次数尽可能的少,最优的情况是只扫描内表一次。
Join Buffer的分配
需要牢记的是,Join Buffer是在Join之前就进行分配,并且每次Join就需要分配一次Join Buffer,所以假设有N张表参与Join,每张表之间通过Block Nested-Loop Join,那么总共需要分配N-1个Join Buffer,这个内存容量是需要DBA进行考量的。
Join Buffer可分为以下两类:
- regular join buffer
- incremental join buffer
regular join buffer 是指 Join Buffer 缓存所有参与查询的列, 如果第一次使用 Join Buffer,必然使用的是 regular join buffer。
incremental join buffer 中的Join Buffer缓存的是当前使用的列,以及之前使用Join Buffer的指针。在多次进行Join的操作时,这样可以极大减少Join Buffer对于内存开销的需求。
此外,对于NULL类型的列,其实不需要存放在Join Buffer中,而对于VARCHAR类型的列,也是仅需最小的内存即可,而不是以CHAR类型在Join Buffer中保存。最后,从MySQL 5.6版本开始,对于Outer Join也可以使用Join Buffer。
Block Nested-Loop Join总结
Block Nested-Loop Join 极大的避免了内表的扫描次数,如果Join Buffer可以缓存外表的数据,那么内表的扫描仅需一次,这和Hash Join非常类似。但是Block Nested-Loop Join依然没有解决的是Join比较的次数,其仍然通过Join判断式进行比较。综上所述,到目前为止各Join算法的成本比较如下所示:
| 开销统计 | SNLJ | INLJ | BNLJ |
|---|---|---|---|
| 外表扫描次数:O | 1 | 1 | 1 |
| 内表扫描次数:I | R | 0 | R*used_column_size/join_buffer_size + 1 |
| 读取记录数:R | R + S*R | R + Smatch | R + S*I |
| Join比较次数:M | S*R | R * IndexHeight | S*R |
| 回表读取记录次数:F | 0 | Smatch (if possible) | 0 |
Batched Key Access Join
Index Nested-Loop Join 虽好,但是通过辅助索引进行链接后需要回表,这里需要大量的随机I/O操作。若能优化随机I/O,那么就能极大的提升Join的性能。为此,MySQL 5.6推出了 Batched Key Access Join,该算法通过常见的空间换时间,随机I/O转顺序I/O,以此来极大的提升Join的性能。
MRR
在说明Batched Key Access Join前,首先介绍下MySQL 5.6的新特性mrr——multi range read。这个特性根据rowid顺序地,批量地读取记录,从而提升数据库的整体性能。看下面的SQL语句的执行计划:
mysql> explain select * from orders
-> where o_orderdate >= '1993-08-01'
-> and o_orderdate < date_add( '1993-08-01' ,interval '3' month)\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: orders
partitions: NULL
type: range
possible_keys: i_o_orderdate
`key: i_o_orderdate`
key_len: 4
ref: NULL
rows: 143210
filtered: 100.00
`Extra: Using index condition`
1 row in set, 1 warning (0.00 sec)上述的SQL语句需要根据辅助索引 i_o_orderdate 进行查询,但是由于要求得到的是表中所有的列,因此需要回表进行读取。而这里就可能伴随着大量的随机I/O。这个过程如下图所示:
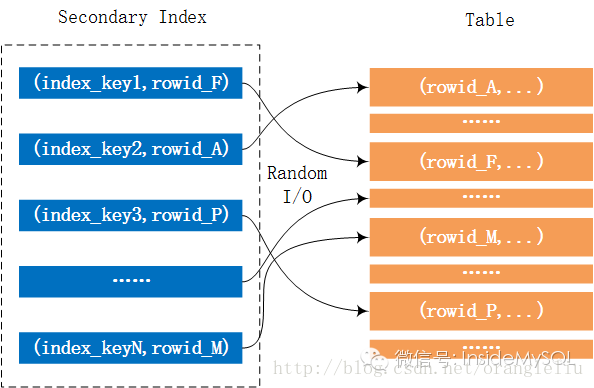
而mrr的优化在于,并不是每次通过辅助索引读取到数据就回表去取记录,而是将其 rowid 给缓存起来,然后对rowid进行排序后,再去访问记录,这样就能将随机I/O转化为顺序I/O,从而大幅地提升性能。这个过程如下所示:
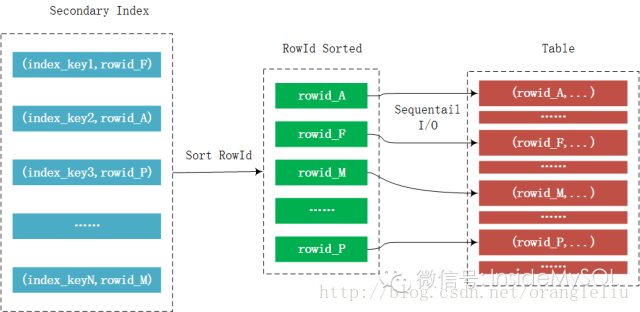
从上图可以发现mrr通过一个额外的内存来对rowid进行排序,然后再顺序地,批量地访问表。这个进行rowid排序的内存大小由参数read_rnd_buffer_size 控制,默认256K。
要开启mrr还有一个比较重的参数是在变量 optimizer_switch 中的 mrr 和 mrr_cost_based 选项。mrr选项默认为on,mrr_cost_based 选项默认为off。mrr_cost_based选项表示通过基于成本的算法来确定是否需要开启mrr特性。然而,在MySQL当前版本中,基于成本的算法过于保守,导致大部分情况下优化器都不会选择mrr特性。为了确保优化器使用mrr特性,请执行下面的SQL语句:
mysql>set optimizer_switch='mrr=on,mrr_cost_based=off';同样执行前面的SQL语句,可以发现这时优化的执行计划为:
mysql> explain select * from orders where
-> o_orderdate >= '1993-08-01'
-> and o_orderdate < date_add('1993-08-01' ,interval '3' month)\G
*************************** 1. row***************************
id: 1
select_type: SIMPLE
table: orders
partitions: NULL
type: range
possible_keys: i_o_orderdate
key: i_o_orderdate
key_len: 4
ref: NULL
rows: 143210
filtered: 100.00
Extra: Using index condition; `Using MRR`
1row in set, 1 warning (0.00 sec)最后来对比一下关闭和开启mrr特性后上述SQL的执行时间:
| – | 执行时间 | 性能提升 |
|---|---|---|
| 默认关闭mrr | 4.31秒 | – |
| 开启mrr | 1.24秒 | 247% |
BKA Join
在讲述完mrr特性后,再来看BKA Join就非常清晰明了了。通过mrr特性优化Join的回表操作,从而提升Join的性能。这时BKA Join的整个过程如下所示:
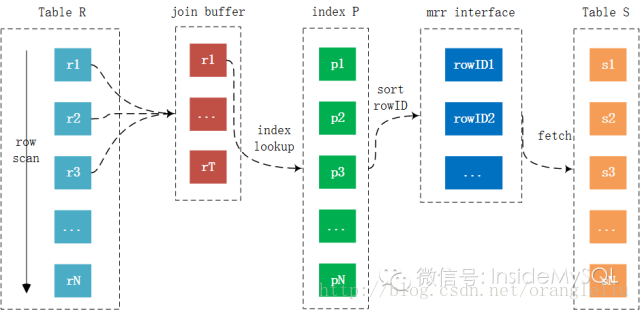
然而,这么好的特性,却是在MySQL中默认关闭的!!!这可能是导致用户认为MySQL Join性能比较差的一个原因。若要使用BKA Join,务必执行下列的SQL语句:
mysql> SET optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
Query OK, 0 rows affected (0.00 sec)若开启了BKA Join,则通过EXPLAIN命令,可以发现优化器的执行结果选项会有Using join buffer (Batched Key Access)的提示,如:
mysql> explain SELECT
-> COUNT(*)
-> FROM
-> part,
-> lineitem
-> WHERE
-> l_partkey, = p_partkey
-> AND p_retailprice > 2050 AND p_size < 100
-> AND l_discount > 0.04\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: part
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 196810
filtered: 11.11
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: lineitem
partitions: NULL
type: ref
possible_keys: i_l_suppkey_partkey,i_l_partkey
key: i_l_suppkey_partkey
key_len: 5
ref: dbt3_s1.part.p_partkey
rows: 28
filtered: 33.33
Extra: Using where; Using join buffer (Batched Key Access)
2 rows in set, 1 warning (0.00 sec)最后来看下执行速度,可以发现BKA的提升非常明显:
| - | 执行速度 | 性能提升 |
|---|---|---|
| 使用INLJ | 20分钟05秒 | – |
使用BKA Join join_buffer_size=256K | 8分钟38秒 | 132% |
使用BKA Join join_buffer_size=128M | 5分钟17秒 | 280% |
MariaDB Join
MySQL数据库虽然提供了BKA Join来优化传统的JOIN算法,的确在一定程度上可以提升JOIN的速度。但不可否认的是,仍然有许多用户对于Hash Join算法有着强烈的需求。Hash Join不需要任何的索引,通过扫描表就能快速地进行JOIN查询,通过利用磁盘的带宽带最大程度的解决大数据量下的JOIN问题。
MariaDB支持Classic Hash Join算法,该算法不同于Oracle的Grace Hash Join,但是也是通过Hash来进行连接,不需要索引,可充分利用磁盘的带宽。
Classic Hash Join
其实MariaDB的Classic Hash Join和Block Nested Loop Join算法非常类似(Classic Hash Join也成为Block Nested Loop Hash Join),但并不是直接通过进行JOIN的键值进行比较,而是根据JoinBuffer中的对象创建哈希表,内表通过哈希算法进行查找,从而在Block Nested Loop Join算法的基础上,又进一步减少了内表的比较次数,从而提升JOIN的查询性能。过程如下图所示:
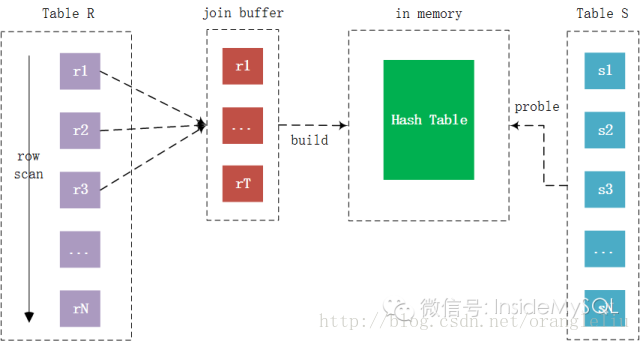
同样地,如果Join Buffer能够缓存所有驱动表(外表)的查询列,那么驱动表和内表的扫描次数都将只有1次,并且比较的次数也只是内表记录数(假设哈希算法冲突为0)。
Classic Hash Join 和 BKA Join 算法一样,需要强制开启,优化器无法做自动的选择,这点也是目前MariaDB和MySQL数据库都存在的问题。但是,MySQL团队已经在重构优化器模块,相信不久的将来,这些问题将很快得到解决。
最后,各JOIN算法成本之间的比较如下表所示:
| 开销统计 | SNLJ | INLJ | BNLJ | BNLJH |
|---|---|---|---|---|
| 外表扫描次数:O | 1 | 1 | 1 | 1 |
| 内表扫描次数:I | R | 0 | R*used_column_size/ join_buffer_size + 1 | R*used_column_size/ join_buffer_size + 1 |
| 读取记录数:R | R + S*R | R + Smatch | R + S*I | R + S*I |
| Join比较次数:M | S*R | R*IndexHeight | S*R | S/I |
| 回表读取记录次数:F | 0 | Smatch (if possible) | 0 | 0 |
Hash Join算法虽好,但是仅能用于等值连接,非等值连接的JOIN查询,其就显得无能为力了。另外,创建哈希表也是费时的工作,但是一旦建立完成后,其就能大幅提升JOIN的速度。所以通常情况下,大表之间的JOIN,Hash Join算法会比较有优势。小表通过索引查询,利用BKA Join就已经能很好的完成查询。
总结
本文介绍了MySQL数据库的各类JOIN算法,其中有Index Nested-Loop Join、Block Nested-Loop Join、Batched Key Access Join算法,最后还介绍了MariaDB的Classic HashJoin算法。通过本文,用户可以发现,虽然MySQL在JOIN算法的支持力度上远不如传统的Oracle、Microsoft SQL Server数据库,但是完成一般的JOIN查询任务是完全没有问题的。用户可能需要选对各种JOIN算法,然后根据不同算法进行参数调优,从而提升JOIN的速度。
不可否认的是MySQL的优化器现在还是存在缺陷的,如优化器无法直接选择Batched Key Access Join和Classic Hash Join。好在Oracle官方已经在重构MySQL优化器模块,相信一个更好的基于成本计算的优化器终将来临。
即使MySQL未来支持Hash Join,但是大数据的查询已经不是传统数据库适合解决的问题,未来这部分工作将越来越多地通过Hadoop这样的集群来解决。
参考文献
[1].https://dev.mysql.com/doc/refman/5.1/en/server-system-variables.html#sysvar_join_buffer_size
[2].https://dev.mysql.com/doc/refman/5.6/en/nested-loop-joins.html
[3].https://dev.mysql.com/doc/internals/en/join-buffer-size.html
[4].https://mariadb.com/kb/en/mariadb/block-based-join-algorithms/















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









