







 这篇博客介绍了EM算法和高斯混合模型,通过一个树林中树叶分类的例子阐述了模型的应用。文章指出了官方文档中的一些模糊和错误之处,并提供了Mathematica实现代码。通过EM算法,即使在未知类别归属和分布参数的情况下,也能逐步估计出数据的分类和分布参数。
这篇博客介绍了EM算法和高斯混合模型,通过一个树林中树叶分类的例子阐述了模型的应用。文章指出了官方文档中的一些模糊和错误之处,并提供了Mathematica实现代码。通过EM算法,即使在未知类别归属和分布参数的情况下,也能逐步估计出数据的分类和分布参数。
模式识别课程中已经学习了EM算法和高斯混合模型,但是听课的时候感觉十分茫然,课程中乃至的概率论等内容和数学中的内容有些脱节,直接套用数学中的内容甚至会导致前后矛盾。课后反复研究之后,发现是不正规的甚至是错误的数学语言的使用导致的公式晦涩难懂。因此在此做一些笔记,努力让公式简单一些。
高斯混合模型
从一个例子说起。
一片树林中有A、B、C三种树木,每种树木的叶子的面积与最大宽度分别服从联合高斯分布(具体参数未知)。如何通过收集一定量的树叶(不知道这些树叶属于哪种树木),试对这些树叶进行分类,并估算出三种树木的联合高斯分布的参数。
首先要对这个例子进行数学描述。每个叶子可以用一个二维向量表示: x=(x1,x2) ,其中的 x1,x2 分别为树叶的面积和最大宽度。叶子属于哪种树用三维向量表示: z=(z1,z2,z3) ,其中, z1,z2,z3 中有且仅有一个为1,其余两个为0. z1 为1表示该树叶属于树木A, z2,z3 与此含义相同。总共采集了 m=100 片叶子,则第 i 片叶子记为
例如,以下Mathematica代码实现了500个示例数据的生成(三种树木的概率分别为0.2,0.3,0.5):

图1
Mathematica代码,用于生成高斯混合模型的示例数据。
效果如图2所示:
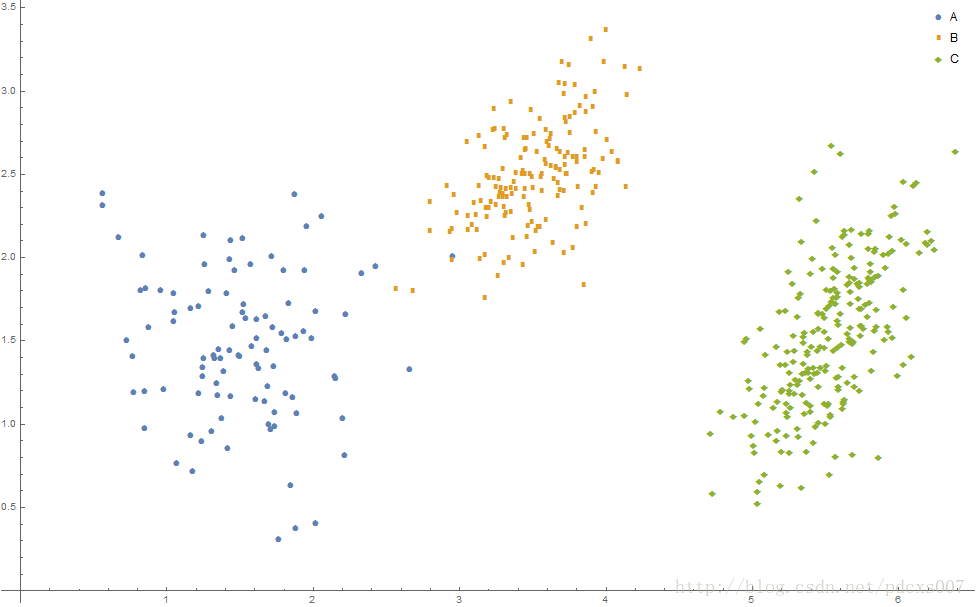
图2 高斯混合模型示例数据
在了解了实际例子后,展示一下“官方”的高斯混合模型的定义,并指明其含混和错误的地方。
Suppose that we are given a training set { x(1),…,x(m)} as usual. Since we are in the unsupervised learning setting, these points do net come with any labels.
We wish to model the data by specifying a joint distribution p(x(i),z(i))=p(x(i)|z(i))p(z(i)) . Here, z(i)∼Multinomial(ϕ) , (where ϕj≥0,∑kj=1ϕj=1 , and parameter ϕj gives p(z(i)=j) ,) and x(i)|z(i)∼N(μj,Σj) . We let k denote the number of values that the
z(i) ’s can take on. Thus our model posits that each x(i) was generated by randomly choosing z(i) from { 1,…,k} , and then x(i) was drawn from one of k Gaussians depending onz(i) . This is called the mixture of Gaussians model.
大体一看会有很多难以理解的地方,这里做一下说明。首先,训练集用的是小写字体加目标的形式,不符合常理。且不加粗会误认为是标题,因此改用上文的方式,训练集记为: {
x1,…,xm} ,第 k 个训练数据的各个分量记为
“官方文档”中的
式中, (na1,…,ak)=n!a1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1613
1613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









