






基础概念:
1. Spark Streaming 是什么?
Spark streaming是Spark核心API的一个扩展,它对实时流式数据的处理具有可扩展性、高吞吐量、可容错性等特点。我们可以从kafka、flume、Twitter、 ZeroMQ、Kinesis等源获取数据,也可以通过由高阶函数map、reduce、join、window等组成的复杂算法计算出数据。最后,处理后的数据可以推送到文件系统、数据库、实时仪表盘中。事实上,你可以将处理后的数据应用到Spark的
机器学习算法、
图处理算法中去。
Spark Streaming接收实时的输入数据流,然后将这些数据切分为批数据供Spark引擎处理,Spark引擎将数据生成最终的结果数据。
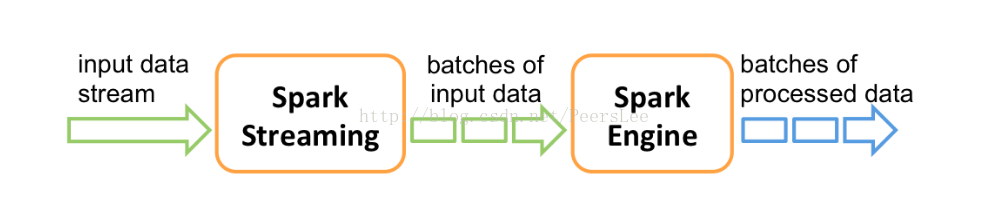
Spark Streaming支持一个高层的抽象,叫做离散流(discretized stream)或者DStream,它代表连续的数据流。DStream既可以利用从Kafka, Flume和Kinesis等源获取的输入数据流创建,也可以在其他DStream的基础上通过高阶函数获得。在内部,DStream是由一系列RDDs组成。
2. DStream 的转换操作
DStream转换操作包括无状态转换和有状态转换。
无状态转换:每个批次的处理不依赖于之前批次的数据。
有状态转换:当前批次的处理需要使用之前批次的数据或者中间结果。有状态转换包括基于滑动窗口的转换和追踪状态变化的转换(updateStateByKey)。
无状态转换:每个批次的处理不依赖于之前批次的数据。
有状态转换:当前批次的处理需要使用之前批次的数据或者中间结果。有状态转换包括基于滑动窗口的转换和追踪状态变化的转换(updateStateByKey)。
Window 操作
Spark Streaming也支持窗口计算,它允许你在一个滑动窗口数据上应用transformation算子。下图阐明了这个滑动窗口。
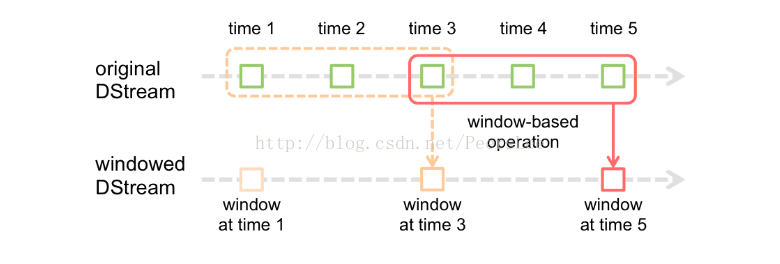
如上图显示,窗口在源DStream上滑动,合并和操作落入窗内的源RDDs,产生窗口化的DStream的RDDs。在这个具体的例子中,程序在三个时间单元的数据上进行窗口操作,并且每两个时间单元滑动一次。 这说明,任何一个窗口操作都需要指定两个参数:
- 窗口长度:窗口的持续时间
- 滑动的时间间隔:窗口操作执行的时间间隔

reduceByWindow 和 reduceByKeyAndWindow 接受一个归约函数,并且还有一种特殊功能,可以接受一个归约函数的逆函数,用来处理要离开窗口的数据(数据块的重复)
updateStateByKey:提供了对一个状态变量的访问,例如,跟踪某个用户最近访问的10个页面
3. DStream 的output 操作
输出操作允许DStream的操作推到如数据库、文件系统等外部系统中。因为输出操作实际上是允许外部系统消费转换后的数据,它们触发的实际操作是DStream转换。目前,定义了下面几种输出操作:

4. Checkpointing
一个流应用程序必须全天候运行,所有必须能够解决应用程序逻辑无关的故障(如系统错误,JVM崩溃等)。为了使这成为可能,Spark Streaming需要checkpoint足够的信息到容错存储系统中, 以使系统从故障中恢复。
- Metadata checkpointing:保存流计算的定义信息到容错存储系统如HDFS中。这用来恢复应用程序中运行worker的节点的故障。元数据包括
- Configuration :创建Spark Streaming应用程序的配置信息
- DStream operations :定义Streaming应用程序的操作集合
- Incomplete batches:操作存在队列中的未完成的批
- Data checkpointing :保存生成的RDD到可靠的存储系统中,这在有状态transformation(如结合跨多个批次的数据)中是必须的。在这样一个transformation中,生成的RDD依赖于之前 批的RDD,随着时间的推移,这个依赖链的长度会持续增长。在恢复的过程中,为了避免这种无限增长。有状态的transformation的中间RDD将会定时地存储到可靠存储系统中,以截断这个依赖链。
何时checkpoint
应用程序在下面两种情况下必须开启checkpoint
- 使用有状态的transformation。如果在应用程序中用到了updateStateByKey或者reduceByKeyAndWindow,checkpoint目录必需提供用以定期checkpoint RDD。
- 从运行应用程序的driver的故障中恢复过来。使用元数据checkpoint恢复处理信息。
怎样配置Checkpointing
在容错、可靠的文件系统(HDFS、s3等)中设置一个目录用于保存checkpoint信息。着可以通过streamingContext.checkpoint(checkpointDirectory)方法来做。这运行你用之前介绍的 有状态transformation。另外,如果你想从driver故障中恢复,你应该以下面的方式重写你的Streaming应用程序。
- 当应用程序是第一次启动,新建一个StreamingContext,启动所有Stream,然后调用start()方法
- 当应用程序因为故障重新启动,它将会从checkpoint目录checkpoint数据重新创建StreamingContext
// Function to create and setup a new StreamingContext
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(...) // new context
val lines = ssc.socketTextStream(...) // create DStreams
...
ssc.checkpoint(checkpointDirectory) // set checkpoint directory
ssc
}
// Get StreamingContext from checkpoint data or create a new one
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
// Do additional setup on context that needs to be done,
// irrespective of whether it is being started or restarted
context. ...
// Start the context
context.start()
context.awaitTermination()注意,RDD的checkpointing有存储成本。这会导致批数据(包含的RDD被checkpoint)的处理时间增加。因此,需要小心的设置批处理的时间间隔。在最小的批容量(包含1秒的数据)情况下,checkpoint每批数据会显著的减少 操作的吞吐量。相反,checkpointing太少会导致谱系以及任务大小增大,这会产生有害的影响。因为有状态的transformation需要RDD checkpoint。默认的间隔时间是批间隔时间的倍数,最少10秒。它可以通过dstream.checkpoint 来设置。典型的情况下,设置checkpoint间隔是DStream的滑动间隔的5-10大小是一个好的尝试。
Kafka 简介
kafka的架构
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为brokerTopic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)Partition
Parition是物理上的概念,每个Topic包含一个或多个Partition.Producer
负责发布消息到Kafka brokerConsumer
消息消费者,向Kafka broker读取消息的客户端。Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。Kafka拓扑结构

如上图所示,一个典型的Kafka集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
Topic & Partition
Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。每条消息都有一个当前Partition下唯一的64字节的offset,它指明了这条消息的起始位置。
如何使用KafkaUtils.createDirectStream 从kafka 中读取DStream?
import org.apache.spark.streaming.kafka._
val directKafkaStream = KafkaUtils.createDirectStream[
[key class], [value class], [key decoder class], [value decoder class] ](
streamingContext, [map of Kafka parameters], [set of topics to consume])TopN 实例(根据日志求危险ip)
import kafka.api.OffsetRequest
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka.KafkaUtils
import scala.util.matching.Regex
/**
* Created by peerslee on 17-3-26.
*/
object DangerIp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("DangerIp").setMaster("local[*]")
// 10秒批间隔时间
val ssc = new StreamingContext(conf, Seconds(10))
// kafka集群中的一台或多台服务器统称为broker
val brokers = "localhost:9092,localhost:9093,localhost:9094"
// kafka 处理的消息源
val topics = "aboutyunlog"
val groupID = "consumer"
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, String](
"metadata.broker.list" -> brokers,
"group.id" -> groupID,
// 说明每次程序启动,从kafka中最开始的第一条消息开始读取
"auto.offset.reset" -> OffsetRequest.SmallestTimeString
)
// url
val ipPat = new Regex("((\\d{1,3}\\.){3}\\d{1,3})")
// msg 是个DStream
val msg = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
/*
返回值它包含的数据类型是二元组(String, String),
因此,可以调用(_._2)得到二元组第二个元素
*/
ssc, kafkaParams, topicsSet).map(_._2).filter(_ != "").map(line => {
(ipPat.findFirstIn(line), 1L)
}).reduceByKey(_+_).map(i => (i._2, i._1)).foreachRDD{
rdd => {
val sort = rdd.sortByKey(false) take 3
for (s <- sort) {
println(s)
}
}
}
ssc.start()
ssc.awaitTermination()
}
}
环境整合:
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











