







 本文详细解析Spark Standalone模式的执行流程,包括Master、Worker和App的角色,资源分配逻辑,以及Task的启动与管理。阐述了Spark在资源层面和任务调度层面的分层设计,展示了其在集群中的高效运作机制。
本文详细解析Spark Standalone模式的执行流程,包括Master、Worker和App的角色,资源分配逻辑,以及Task的启动与管理。阐述了Spark在资源层面和任务调度层面的分层设计,展示了其在集群中的高效运作机制。
背景
本文不打算从源码分析的角度看standalone如何实现,甚至有的模块和类在分析中都是忽略掉的。
本文目的是透过spark的standalone模式,看类似spark这种执行模式的系统,在设计和考虑与下次资源管理系统对接的时候,有什么值得参考和同通用的地方,比如说接口和类体系,比如说各个执行层次的划分:面向资源的部分 vs 面向摆放的部分;面向资源里面进程的部分 vs 线程的部分等。对这些部分谈谈体会。
执行流程
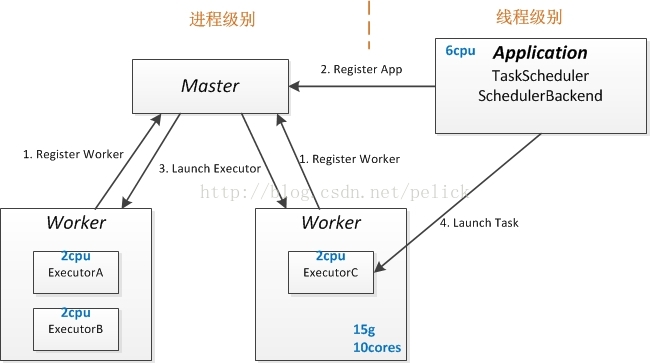
解释standalone执行原理可以抛开Driver和Client。
首先,简单说明下Master、Worker、App三种角色。
Application:带有自己需要的mem和cpu资源量,会在master里排队,最后被分发到worker上执行。app的启动是去各个worker遍历,获取可用的cpu,然后去各个worker launch executor。
Worker:每台slave起一个(也可以起多个),默认或被设置cpu和mem数,并在内存里做加减维护资源剩余量。Worker同时负责拉起本地的executor backend,即执行进程。
Master:接受Worker、app的注册
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









