并行计算在处处都有大数据 的今天已经不是一个新鲜的词汇了,现在已经有单机多核甚至多机集群并行计算,注意,这里说的是并行,而不是并发。严格的将,并行是指系统内有多个任务同时执行 ,而并发是指系统内有多个任务同时存在 ,不同的任务按时间分片的方式切换执行,由于切换的时间很短,给人的感觉好像是在同时执行。 Java 在JDK7之后加入了并行计算的框架Fork/Join,可以解决我们系统中大数据计算的性能问题。Fork/Join采用的是分治法,Fork是将一个大任务拆分成若干个子任务,子任务分别去计算,而Join是获取到子任务的计算结果,然后合并,这个是递归的过程。子任务被分配到不同的核上执行时,效率最高。伪代码如下:
Result solve(Problem problem) {
if (problem is small)
directly solve problem
else {
split problem into independent parts
fork new subtasks to solve each part
join all subtasks
compose result from subresults
}
}
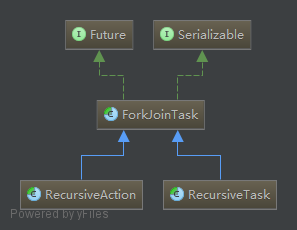
Fork/Join框架的核心类是ForkJoinPool ,它能够接收一个ForkJoinTask ,并得到计算结果。ForkJoinTask有两个子类,RecursiveTask (有返回值)和RecursiveAction (无返回结果),我们自己定义任务时,只需选择这两个类继承即可。类图如下:
import java.util.Arrays;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class SumTask extends RecursiveTask<Integer> {
private static final long serialVersionUID = -6196480027075657316 L;
private static final int THRESHOLD = 500000 ;
private long [] array;
private int low;
private int high;
public SumTask (long [] array, int low, int high) {
this .array = array;
this .low = low;
this .high = high;
}
@Override
protected Integer compute () {
int sum = 0 ;
if (high - low <= THRESHOLD) {
for (int i = low; i < high; i++) {
sum += array[i];
}
} else {
int mid = (low + high) >>> 1 ;
SumTask left = new SumTask(array, low, mid);
SumTask right = new SumTask(array, mid + 1 , high);
left.fork();
right.fork();
sum = left.join () + right.join ();
}
return sum;
}
public static void main (String[] args) throws ExecutionException, InterruptedException {
long [] array = genArray(1000000 );
System.out .println(Arrays.toString(array));
SumTask sumTask = new SumTask(array, 0 , array.length - 1 );
long begin = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
forkJoinPool.submit(sumTask);
Integer result = sumTask.get ();
long end = System.currentTimeMillis();
System.out .println(String.format("结果 %s 耗时 %sms" , result, end - begin));
}
private static long [] genArray (int size) {
long [] array = new long [size];
for (int i = 0 ; i < size; i++) {
array[i] = new Random().nextLong();
}
return array;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 我们通过调整阈值(THRESHOLD),可以发现耗时是不一样的。实际应用中,如果需要分割的任务大小是固定的,可以经过测试 ,得到最佳阈值;如果大小不是固定的,就需要设计一个可伸缩的算法 ,来动态计算出阈值。如果子任务很多,效率并不一定会高。
参考资料
http://gee.cs.oswego.edu/dl/papers/fj.pdf https://docs.oracle.com/javase/tutorial/essential/concurrency/forkjoin.html https://www.ibm.com/developerworks/cn/java/j-lo-forkjoin/ http://www.ibm.com/developerworks/cn/java/j-jtp11137.html

























 421
421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









