









本篇博客参考:python爬虫入门教程 http://blog.csdn.net/wxg694175346/article/category/1418998
Python爬虫爬取网页图片 http://www.cnblogs.com/abelsu/p/4540711.html
一、项目分析
为了给我的出于实验目的网上商城批量增加商品信息,我需要自动从网上获取大量的商品名称、价格、图片信息保存到本地,再传到我自己的web应用中,为后续实验使用。
看完上面的参考博客就基本可以上手了,需要注意的一点是网上很多案例是python 2.X版本的,而现在一般是python 3.X版本的环境,有些地方代码需要调整,引用的包也有不同。
整个项目没使用
scrapy、bs4,比较原生简单,最大的难点应该在于对网页源代码分析,通过正则表达式获取url,这里可能会出现两种和预期不同的错误场景:一是匹配不到,二是匹配过多,需要对正则表达式好好检查。
我选择爬取的是苏宁易购里面的大聚惠类似于聚划算,起点是 https://ju.suning.com/,分析源代码很简易找到各分类的URL
<!--商品列表一级导航栏 [[ -->
<div class="ju-nav-wrapper">
<div class="ju-nav">
<table>
<tr>
<td class="active"><a name="columnId" id="0" value="1"
href="/pc/new/home.html" name1="mps_index_qbsp_qb">全部商品</a>
</td>
<td><a name="categCode"
href="/pc/column/products-1-0.html#refresh"
value="1"
name1="mps_index_qbsp_spml1">大家电</a></td>
<td><a name="categCode"
href="/pc/column/products-2-0.html#refresh"
value="2"
name1="mps_index_qbsp_spml2">电脑数码</a></td>
<td><a name="categCode"
href="/pc/column/products-17-0.html#refresh"
value="17"
name1="mps_index_qbsp_spml3">生活家电</a></td>
<td><a name="categCode"
href="/pc/column/products-733-0.html#refresh"
value="733"
name1="mps_index_qbsp_spml4">手机</a></td>
<td><a name="categCode"
href="/pc/column/products-81-0.html#refresh"
value="81"
name1="mps_index_qbsp_spml5">车品</a></td>
<td><a name="categCode"
href="/pc/column/products-11-0.html#refresh"
value="11"
name1="mps_index_qbsp_spml6">居家日用</a></td>
<td><a name="categCode"
href="/pc/column/products-10-0.html#refresh"
value="10"
name1="mps_index_qbsp_spml7">食品</a></td>
<td><a name="categCode"
href="/pc/column/products-8-0.html#refresh"
value="8"
name1="mps_index_qbsp_spml8">美妆</a></td>
<td><a name="categCode"
href="/pc/column/products-9-0.html#refresh"
value="9"
name1="mps_index_qbsp_spml9">母婴</a></td>
<td><a name="categCode"
href="/pc/column/products-464-0.html#refresh"
value="464"
name1="mps_index_qbsp_spml10">服饰鞋包</a></td>
<td><a name="categCode"
href="/pc/column/products-468-0.html#refresh"
value="468"
name1="mps_index_qbsp_spml11">纸品洗护</a></td>
<td><a name="categCode"
href="/pc/column/products-125-0.html#refresh"
value="125"
name1="mps_index_qbsp_spml12">家装</a></td>
</tr>
</table>
</div>
</div>https://ju.suning.com/pc/column/products-1-0.html 就是大家电分类的显示页面,然后再对其进行源码分析
<a href="/pc/column/products-1-0.html#refresh" value="0" class="active" name1="mps_1_qbsp_ejqb">全 部</a>
<input type="hidden" value="P" id="secCategCodeBrand"/>
<a href="/pc/column/products-1-.html#P" value="P" class="floor" name1="mps_1_qbsp_ejml1">精选品牌</a>
<a href="/pc/column/products-1-139.html#139" value="139" class="floor" name1="mps_1_qbsp_ejml1">厨卫</a>
<a href="/pc/column/products-1-137.html#137" value="137" class="floor" name1="mps_1_qbsp_ejml2">冰箱</a>
<a href="/pc/column/products-1-191.html#191" value="191" class="floor" name1="mps_1_qbsp_ejml3">彩电影音</a>
<a href="/pc/column/products-1-138.html#138" value="138" class="floor" name1="mps_1_qbsp_ejml4">空调</a>
<a href="/pc/column/products-1-410.html#410" value="410" class="floor" name1="mps_1_qbsp_ejml5">热水器</a>
<a href="/pc/column/products-1-409.html#409" value="409" class="floor" name1="mps_1_qbsp_ejml6">洗衣机</a>
<a href="/pc/column/products-1-552.html#552" value="552" class="floor" name1="mps_1_qbsp_ejml7">净水设备</a>
<a href="/pc/column/products-1-617.html#617" value="617" class="floor" name1="mps_1_qbsp_ejml8">爆款预订</a>
https://ju.suning.com/pc/column/products-1-.html就是精选品牌显示页面,然后再对其进行源码分析
<!-- 精选品牌列表 -->
<h5 id ="P" class="ju-prodlist-head"><span>精选品牌</span></h5>
<ul class="ju-prodlist-floor1 ju-prodlist-lazyBrand clearfix">
<li class="ju-brandlist-item" name="brandCollect" value="100036641">
<a href="/pc/brandComm-100036641-1.html" title="帅康(sacon)" expotype="2" expo="mps_1_qbsp_jxpp1:帅康(sacon)" name1="mps_1_qbsp_jxpp1" target="_blank" shape="" class="brand-link"></a>
<img orig-src-type="1-4" orig-src="//image3.suning.cn/uimg/nmps/PPZT/1000592621751_2_390x195.jpg" width="390" height="195" class="brand-pic lazy-loading" alt="帅康(sacon)">
<div class="sale clearfix">
<span class="brand-countdown ju-timer" data-time-now="" name="dateNow" data-time-end="2017-09-06 23:59:57.0">
</span>
<span class="brand-buynum" id="100036641"></span>
</div>
<div class="border"></div>
</li>
<li class="ju-brandlist-item" name="brandCollect" value="100036910">
<a href="/pc/brandComm-100036910-1.html" title="富士通(FUJITSU)" expotype="2" expo="mps_1_qbsp_jxpp2:富士通(FUJITSU)" name1="mps_1_qbsp_jxpp2" target="_blank" shape="" class="brand-link"></a>
<img orig-src-type="1-4" orig-src="//image1.suning.cn/uimg/nmps/PPZT/1000601630663_2_390x195.jpg" width="390" height="195" class="brand-pic lazy-loading" alt="富士通(FUJITSU)">
<div class="sale clearfix">
<span class="brand-countdown ju-timer" data-time-now="" name="dateNow" data-time-end="2017-09-06 23:59:55.0">
</span>
<span class="brand-buynum" id="100036910"></span>
</div>
<div class="border"></div>
</li>https://ju.suning.com/pc/brandComm-100036641-1.html
就是帅康品牌的所有商品的显示页面,然后再对其进行源码分析
<li class="ju-prodlist-item" id="6494577">
<div class="item-wrap">
<a title="帅康(sacon)烟灶套餐TE6789W+35C欧式不锈钢油烟机灶具套餐" expotype="1" expo="mpsblist_100036641_ppsp_mrsp1:0070068619|126962539" name1="mpsblist_100036641_ppsp_mrsp1" href="/pc/jusp/product-00010641eb93529d.html" target="_blank" shape="" class="prd-link">
</a>
<img class="prd-pic lazy-loading" orig-src-type="0-1" orig-src="//image4.suning.cn/uimg/nmps/ZJYDP/100059262126962539picA_1_392x294.jpg" width="390" height="292">
<div class="detail">
<p class="prd-name fixed-height-name">帅康(sacon)烟灶套餐TE6789W+35C欧式不锈钢油烟机灶具套餐</p>
<p class="prd-desp-items fixed-height-desp">
<span>17大吸力</span>
<span>销量TOP</span>
<span>一级能效</span>
<span>限时抢烤箱!</span>
</p>
</div>
<div class="sale clearfix">
<div class="prd-price clearfix">
<div class="sn-price"></div>
<div class="discount">
<p class="full-price"></p>
</div>
</div>
<div class="prd-sale">
<p class="prd-quan" id="000000000126962539-0070068619">
</p>
<p class="sale-amount">
</p>
</div>
</div>
</div>
<div class="border"></div>
</li>https://ju.suning.com/pc/jusp/product-00010641eb93529d.html
就是帅康(sacon)烟灶套餐TE6789W+35C欧式不锈钢油烟机灶具套餐商品的显示页面,然后再对其进行源码分析就可以提取出商品的信息了,下面讲代码实现。
二、项目实现
我最开始完全按照我分析网页源代码的思路一层一级调用实现
import urllib
import urllib.parse
import urllib.request
import re
import threading
import queue
import time
q = queue.Queue()
r = re.compile(r'href="(http://ju\.suning\.com/pc/jusp/product.+?)"')
urls = []
#商品-四级分类
def save_products_from_url(contents):
category_products = re.findall('href="/pc/jusp/product.+?.html"',contents,re.S)
print('所有四级分类')
print(category_products)
for url_product in category_products:
url_product = url_product.replace("\"","")
url_product = url_product.replace("href=","")
url_product = url_product.replace("/pc","http://ju.suning.com/pc")
if url_product in urls:
continue
else:
html = download_page(url_product)
get_image(html)
#设置sleep否则网站会认为是恶意访问而终止访问
time.sleep(1)
return
#品牌-三级分类
def save_brand_from_url(contents):
category_brand = re.findall('href="/pc/brandComm.+?.html"',contents,re.S)
print('所有三级分类')
print(category_brand)
for url_brand in category_brand:
url_brand = url_brand.replace("\"","")
url_brand = url_brand.replace("href=","")
url_brand = url_brand.replace("/pc","http://ju.suning.com/pc")
if url_brand in urls:
continue
else:
urls.append(url_brand)
q.put(url_brand)
print('三级分类--:海信')
print(url_brand)
opener = urllib.request.urlopen(url_brand)
contents = opener.read()
contents = contents.decode("utf-8")
opener.close()
time.sleep(1)
save_products_from_url(contents)
def save_contents_from_url(contents):
#二级分类:空调
regx = r'href="/pc/column/products-[\d]{1,3}-[\d][\d][\d].html'
pattern = re.compile(regx)
category_two = re.findall(pattern,repr(contents))
print('所有二级分类')
print(category_two)
for url_two in category_two:
url_two = url_two.replace("\"","")
url_two = url_two.replace("href=","")
url_two = url_two.replace("/pc","http://ju.suning.com/pc")
if url_two in urls:
continue
else:
urls.append(url_two)
q.put(url_two)
print('二级分类--:空调')
print(url_two)
opener = urllib.request.urlopen(url_two)
contents = opener.read()
contents = contents.decode("utf-8")
opener.close()
time.sleep(1)
save_brand_from_url(contents)
def set_urls_from_contents(contents):
#一级分类:大家电
g = re.findall('href="/pc/column/products.+?.html#refresh"',contents,re.S)
print('所有一级分类')
print(g)
for url in g :
print('一级分类--:大家电')
print(url)
url = url.replace("\"","")
url = url.replace("#refresh","")
url = url.replace("href=","")
url = url.replace("/pc","http://ju.suning.com/pc")
print(url)
if url in urls:
continue
else:
urls.append(url)
q.put(url)
opener = urllib.request.urlopen(url)
contents = opener.read()
contents = contents.decode("utf-8")
opener.close()
time.sleep(1)
save_contents_from_url(contents)
def save_contents():
url = "https://ju.suning.com/"
opener = urllib.request.urlopen(url)
contents = opener.read()
contents = contents.decode("utf-8")
opener.close()
print('首页')
print(url)
set_urls_from_contents(contents)
def download_page(url):
request = urllib.request.Request(url)
response = urllib.request.urlopen(request)
data = response.read()
return data
#下载图片
def get_image(html):
print('price')
regx = r'sn.gbPrice ="\d*?.\d*?";'
pattern = re.compile(regx)
get_price = re.findall(pattern,repr(html))
print(get_price)
for title in get_price:
myindex = title.index('"')
newprice = title[myindex+1:len(title)-2]
print(newprice)
print('title')
regx = r'<title>.*?苏宁大聚惠</title>'
pattern = re.compile(regx)
html = html.decode('utf-8')
get_title = re.findall(pattern,repr(html))
for title in get_title:
myindex = title.index('【')
newtitle = title[7:myindex]
print(newtitle)
regx = r'orig-src="//image[\d].suning.cn/uimg/nmps/ZJYDP/[\S]*\.jpg'
pattern = re.compile(regx)
get_img = re.findall(pattern,repr(html))
num = 1
for img in get_img:
img = img.replace("\"","")
img = img.replace("orig-src=","http:")
print(img)
index = img.index('picA')
item_id = img[index-18:index]
name = img[index-18:index]+'.jpg'
print(name)
image = download_page(img)
with open(name,'wb') as fp:
fp.write(image)
print('正在下载第%s张图片'%num)
num += 1
#将商品价格、名称、编号id写入文件
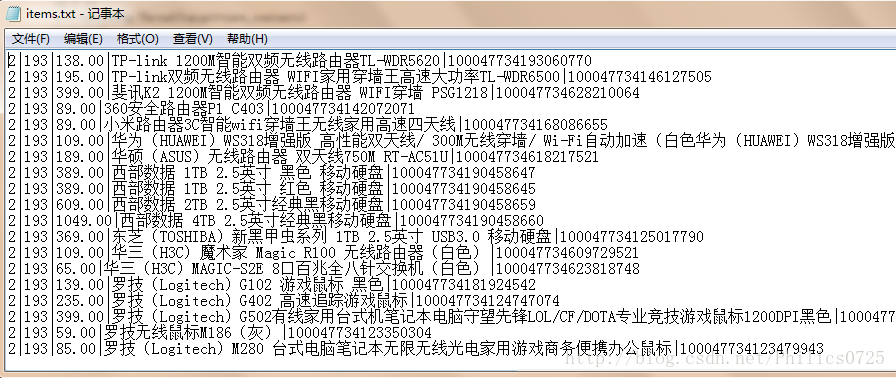
with open('items.txt','ab') as files:
items = '|'+ newprice +'|'+ newtitle +'|'+ item_id + '\r\n'
items = items.encode('utf-8')
files.write(items)
time.sleep(1)
return
q.put("https://ju.suning.com/")
ts = []
t = threading.Thread(target=save_contents)
t.start()
import urllib
import urllib.parse
import urllib.request
import re
import threading
import queue
import time
q = queue.Queue()
mylock = threading.RLock()
urls = []
level = 0
category = 0
categorysed = 0
#层级与正则表达式映射
def numbers_to_strings(argument):
switcher = {
1: regx_1,
2: regx_2,
3: regx_3,
4: regx_4,
}
return switcher.get(argument, "nothing")
def set_urls_from_contents(contents):
global level
global category
global categorysed
#一级分类
regx_1 = r'href="/pc/column/products.+?.html#refresh"'
#二级分类
regx_2 = r'href="/pc/column/products-[\d]{1,3}-[\d][\d][\d].html'
#三级分类:品牌
regx_3 = r'href="/pc/brandComm.+?.html"'
#四级分类:商品
regx_4 = r'href="/pc/jusp/product-.+?.html"'
pattern = re.compile(regx_4)
g = re.findall(pattern,repr(contents))
if len(g) >0:
level = 4
else:
level = 0
print('商品分类不匹配')
print(str(level)+':1')
if level == 0:
pattern = re.compile(regx_3)
g = re.findall(pattern,repr(contents))
if len(g) >0:
level = 3
else:
level = 0
print('品牌分类不匹配')
else:
print('品牌分类跳过')
print(str(level)+':2')
if level == 0:
pattern = re.compile(regx_2)
g = re.findall(pattern,repr(contents))
if len(g) >0:
level = 2
else:
level = 0
print('二级分类不匹配')
else:
print('二级分跳过')
print(str(level)+':3')
if level == 0:
pattern = re.compile(regx_1)
g = re.findall(pattern,repr(contents))
if len(g) >0:
level = 1
else:
level = 0
print('一级分类不匹配')
else:
print('一级分类跳过')
print(str(level)+':4')
print('所有分类明细')
print(g)
for url in g :
#url = url.groups()[0]
print(str(level)+'级分类:')
print(url)
if url.find('#refresh')>0:
eindex = url.index('.html')
print(eindex)
sindex = url.index('s-')
category = url[sindex+2:eindex-2]
print('一级分类id')
print(category)
elif url.find('products-')>0:
eindex = url.index('.html')
#sindex = url.index('s-')
categorysed = url[eindex-3:eindex]
print('二级分类id')
print(categorysed)
url = url.replace("\"","")
url = url.replace("#refresh","")
url = url.replace("href=","")
url = url.replace("/pc","http://ju.suning.com/pc")
print(url)
if url.find('product-') >0:
level =4
else:
level = level -1
if url in urls:
continue
else:
urls.append(url)
q.put(url)
if level == 4:
html = download_page(url)
get_image(html,category,categorysed)
else:
opener = urllib.request.urlopen(url)
contents = opener.read()
contents = contents.decode("utf-8")
opener.close()
time.sleep(0.1)
set_urls_from_contents(contents)
def save_contents():
url = "https://ju.suning.com/"
opener = urllib.request.urlopen(url)
contents = opener.read()
contents = contents.decode("utf-8")
opener.close()
print('首页')
print(url)
set_urls_from_contents(contents)
#下载具体一个商品页面中的信息
def download_page(url):
request = urllib.request.Request(url)
response = urllib.request.urlopen(request)
data = response.read()
return data
#下载图片
def get_image(html,category,categorysed):
print('price')
regx = r'sn.gbPrice ="\d*?.\d*?";'
pattern = re.compile(regx)
get_price = re.findall(pattern,repr(html))
print(get_price)
#print(html)
for title in get_price:
myindex = title.index('"')
newprice = title[myindex+1:len(title)-2]
print(newprice)
print('title')
regx = r'<title>.*?苏宁大聚惠</title>'
pattern = re.compile(regx)
html = html.decode('utf-8')
get_title = re.findall(pattern,repr(html))
#print(get_title)
for title in get_title:
myindex = title.index('【')
newtitle = title[7:myindex]
print(newtitle)
regx = r'orig-src="//image[\d].suning.cn/uimg/nmps/ZJYDP/[\S]*\.jpg'
pattern = re.compile(regx)
get_img = re.findall(pattern,repr(html))
num = 1
for img in get_img:
img = img.replace("\"","")
img = img.replace("orig-src=","http:")
print(img)
index = img.index('pic')
item_id = img[index-18:index]
name = img[index-18:index]+'.jpg'
print(name)
image = download_page(img)
with open(name,'wb') as fp:
fp.write(image)
print('正在下载第%s张图片'%num)
num += 1
with open('items.txt','ab') as files:
items = str(category)+'|'+str(categorysed)+'|'+ newprice +'|'+ newtitle +'|'+ item_id + '\r\n'
items = items.encode('utf-8')
files.write(items)
time.sleep(1)
return
#首页入口
q.put("https://ju.suning.com/")
ts = []
t = threading.Thread(target=save_contents)
t.start()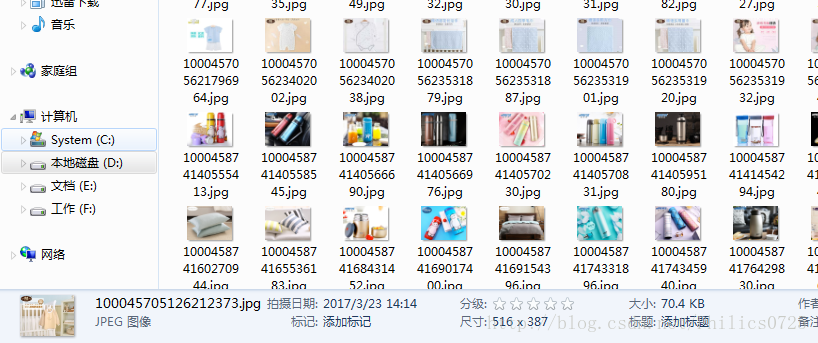















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









