







 本文介绍了主成分分析(PCA)作为一种无监督方法,用于高维数据的降维和可视化,强调了PCA在保留数据结构特征方面的优势。同时,文章探讨了隐变量模型,包括隐变量分类和变分贝叶斯方法,解释了如何在数据中引入隐变量以进行近似推理。
本文介绍了主成分分析(PCA)作为一种无监督方法,用于高维数据的降维和可视化,强调了PCA在保留数据结构特征方面的优势。同时,文章探讨了隐变量模型,包括隐变量分类和变分贝叶斯方法,解释了如何在数据中引入隐变量以进行近似推理。
用于聚类的无监督方法——将数据对象分割成有限数目的不相关组,使得同组中的数据对象具有某些相似性。现在引入第二类无监督方法,这种方法通常被归类于投影技术
用于处理高维的数据集,以及如何通过将数据集投影到低维空间对数据进行可视化或者特征选择。这些技术用于处理更大规模的隐变量模型
参数的数量随着维度M的增加而增加,我们将M维数据投影到D维的同时,希望在某种程度上保留感兴趣的属性
方差——感兴结构的代表
对数据进行投影操作时,我们希望尽可能保留数据中感兴趣的结构
数据在每个一维空间的方差可以通过下式计算:
σ2=1N∑Nn=1(xn−μx)2
如果想要表达数据的聚类结构,在使方差最大的方向上对数据进行投影更能保留这一结构特征
基于这个原因,当考虑投影方向时,方差是一个很好的最大化度量标准。因此在大多流行的投影技术中,如主成分分析,使用方差作为最大化度量的标准。
主成分分析
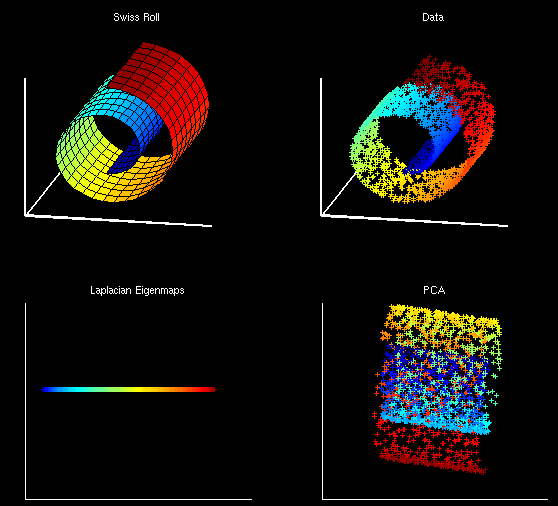
主成分分析(PCA)可能是目前应用最为广泛的一种统计技术,用于将高维数据投影到低维空间。在机器学习中,该技术大多应用于数据可视化和特征选择。PCA定义了一组线性投影:每个投影维度都是原始数据维度的一个线性组合
为了简化模型,我们构造 y¯=1N∑Nn=1yn=0
从投影D=1维开始。
xn=wTyn
σ2x=1N∑Nn=1(xn−x¯)2
得到:
σ2x=wTCw
C是样本协方差矩阵,定义为
C=1N∑Nn=1(yn−y¯)(yn−y¯)T
结合条件 wTw=1 ,利用拉格朗日方法
最大化: L=wTCw−λ(w
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









