









原文地址 http://blog.csdn.net/qq_25806863/article/details/67637567
在上一篇文章tess_two Android图片文字识别中,使用tess_two完成了简单的文字识别。
简书地址
但是发现一个很明显的问题是,默认的识别速度比较慢。识别四个很明显的字需要将近两秒。
DemoGitHub可以试试。

tess_two用的是tesseract ocr引擎
查看用到的官方提供的中文识别库chi_sim.traineddata文件有52M。里面肯定是包含了很多的训练和文字的。
我用不了那么多字,然后就按官方和网上的资料自己做了一个识别库,这个库只能识别训练过的文字。速度生成的文件应该跟训练的字数有关的,我实验了几个字,只有100多k。
看看速度,快了很多。

下面大致记录一下制作训练识别库的方法。相对比较简单。
安装tesseract ocr引擎和jTessBoxEditor
在官网上可以找到Window和Mac的安装方法,window的有专门的额客户端。我的是Mac,所以选的是Homebrew安装。
Homebrew 是一个包管理器,如果没装的话,在终端执行ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"就会自动装好。
单纯的安装tesseract ocr引擎是可以直接用官网的命令brew install tesseract
但是,我后面要用到训练样本的命令,所以我们要用到的安装命令是brew install --with-training-tools tesseract,否则后面一些命令会找不到。
如果初次安装用了第一个,那么可以先用brew uninstall tesseract卸载掉,然后执行brew install --with-training-tools tesseract重新安装。
装好之后,找到在上篇文章中下载的chi_sim.traineddata。
然后复制到/usr/local/Cellar/tesseract/3.05.00/share/tessdata中备用。里面已经自带了eng.traineddata。 这不不是必须的。
安装jTessBoxEditor
这里提供了很多第三方的训练工具,我选第一个jTessBoxEditor。
jTessBoxEditor是基于java的,多以可以跨平台,下载下来在Mac和Windows上都能运行。
下载下来是这样的
启动jTessBoxEditor.jar就能打开客户端。
这里我有一个疑问,别人电脑上都能双击这个文件打开,而我的电脑双击一闪就没了,只能用在终端里打开。。
开始制作box
准备好训练的图片:
什么格式应该没关系,反正都要转化成tif格式的。
将图片转为tif格式的样本图片
方法有很多,我用的在线转化。
下载下来的文件是
要手动吧后缀的.html去掉变成.tif文件,比较麻烦。所以不推荐用这个转换工具。。
改名后
合并样本图片
大家应该注意到有一个new文件夹,这个文件夹用来放之后生成的各种文件的,包括最终的traineddata文件。
打开jTessBoxEditor.jar,然后点菜单上的Tool->Merge TIFF
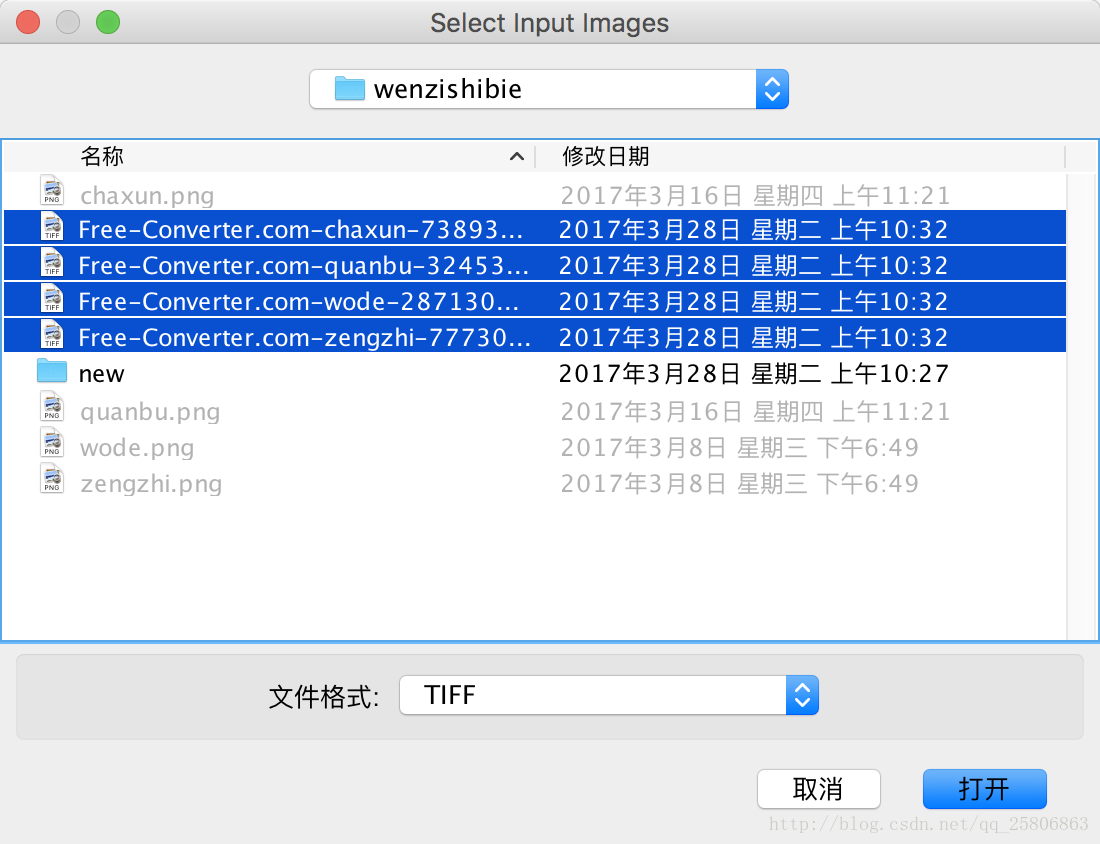
保存到new文件夹中,保存的时候注意名字sll.normal.exp0.tif
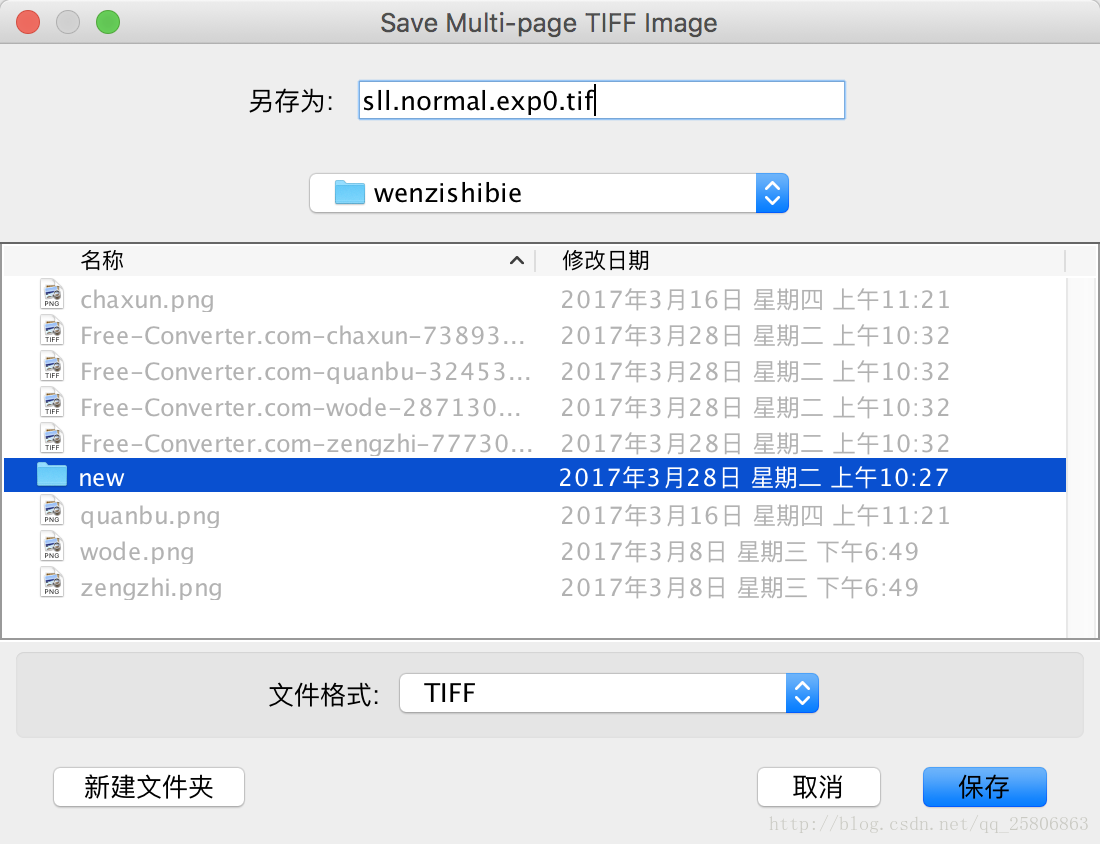
关于名字 sll.normal.exp0.tif
官网的写法是这样的
[lang].[fontname].exp[num].tif
[lang]是语言,随便起,这里的叫sll
[fontname]是字体,随便起,这里叫 normal
[num]我也不知道啥意思,写的是数字0
这两个都是自定义的,后面会用到,所以要记住。
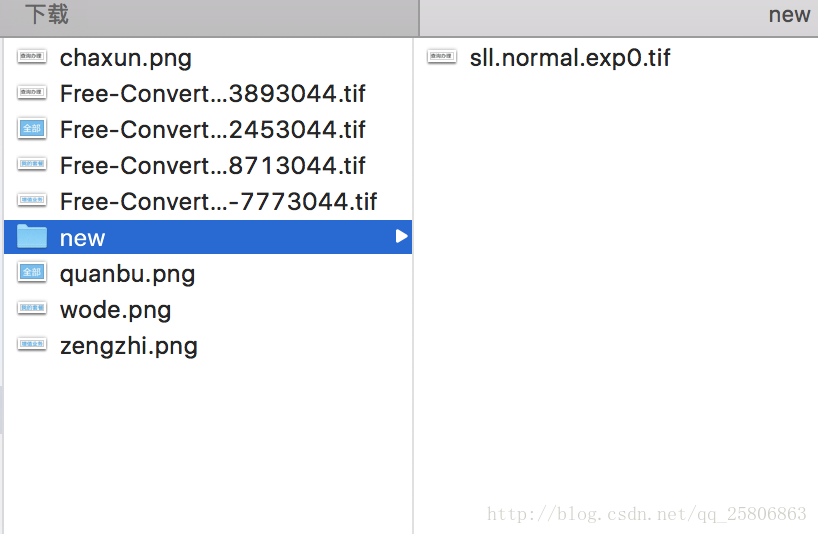
点击保存后,会在new文件夹中生成合并的sll.normal.exp0.tif文件
然后执行命令
tesseract sll.normal.exp0.tif sll.normal.exp0 -l chi_sim batch.nochop makebox没有复制chi_sim.traineddata,用下面的。用上面的后面有时候出了莫名其妙的错误
tesseract sll.normal.exp0.tif sll.normal.exp0 -l eng batch.nochop makebox会在当前文件夹下生成sll.normal.exp0.box文件

修改box文件
打开jTessBoxEditor.jar,点击Box Editor->open
然后选上一步的tif文件,会自动打开绑定的box文件。
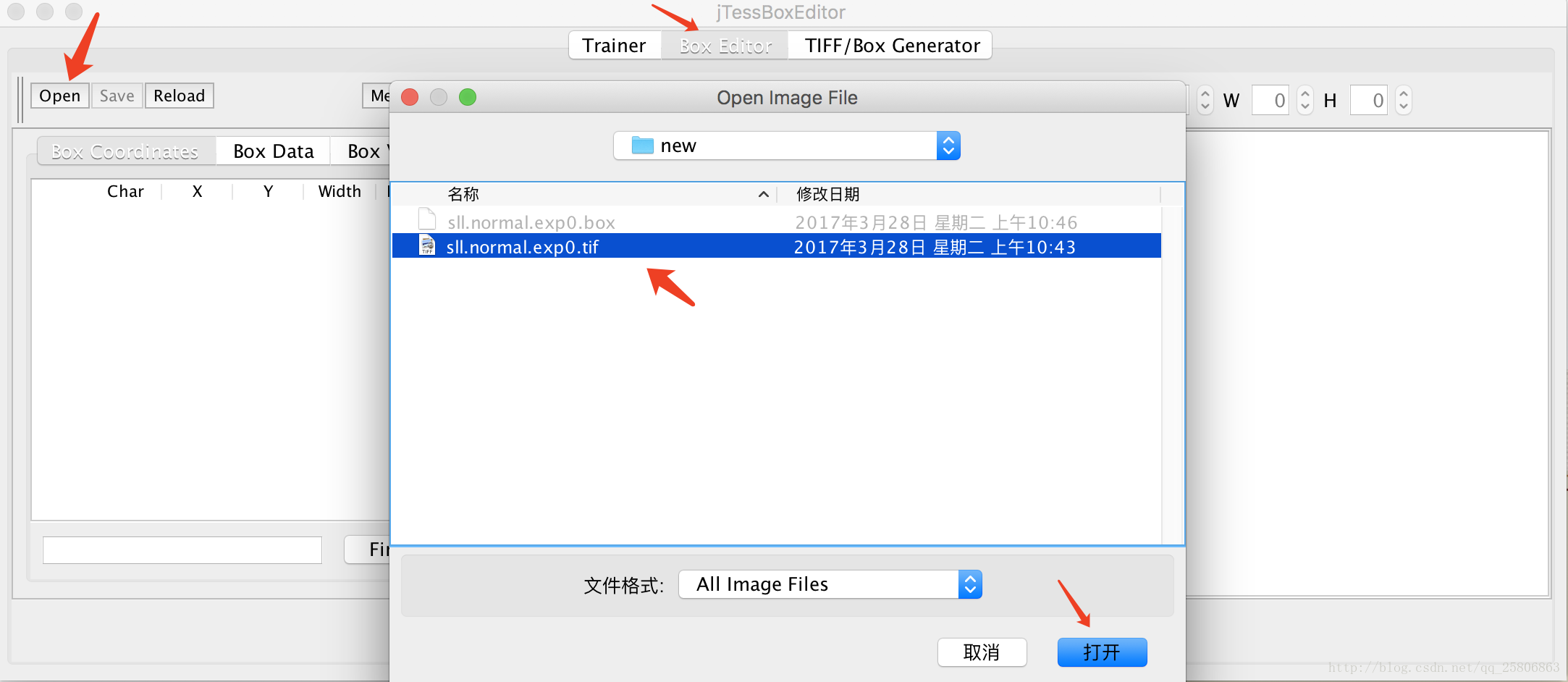
在里面可以对他的识别区域,识别结果进行一些修改,达到我们正确的识别目的
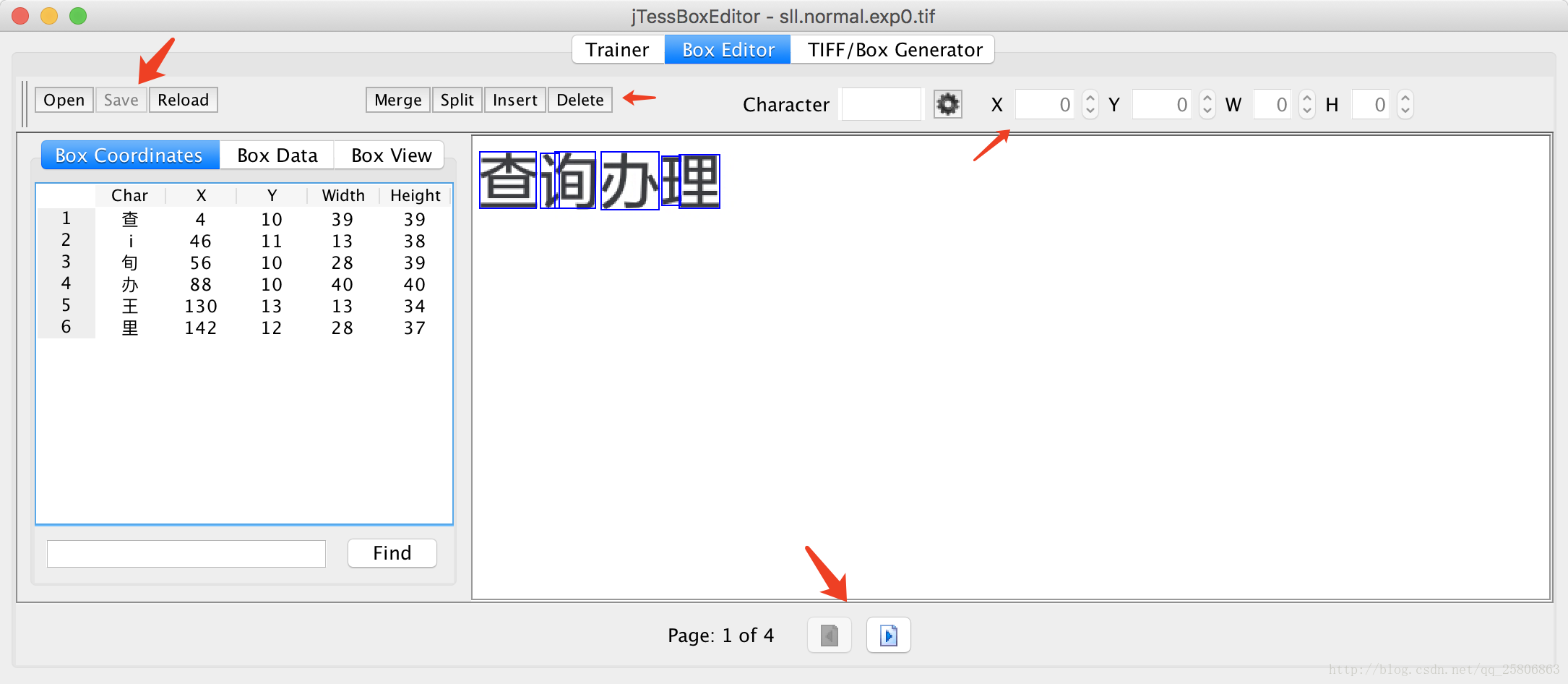
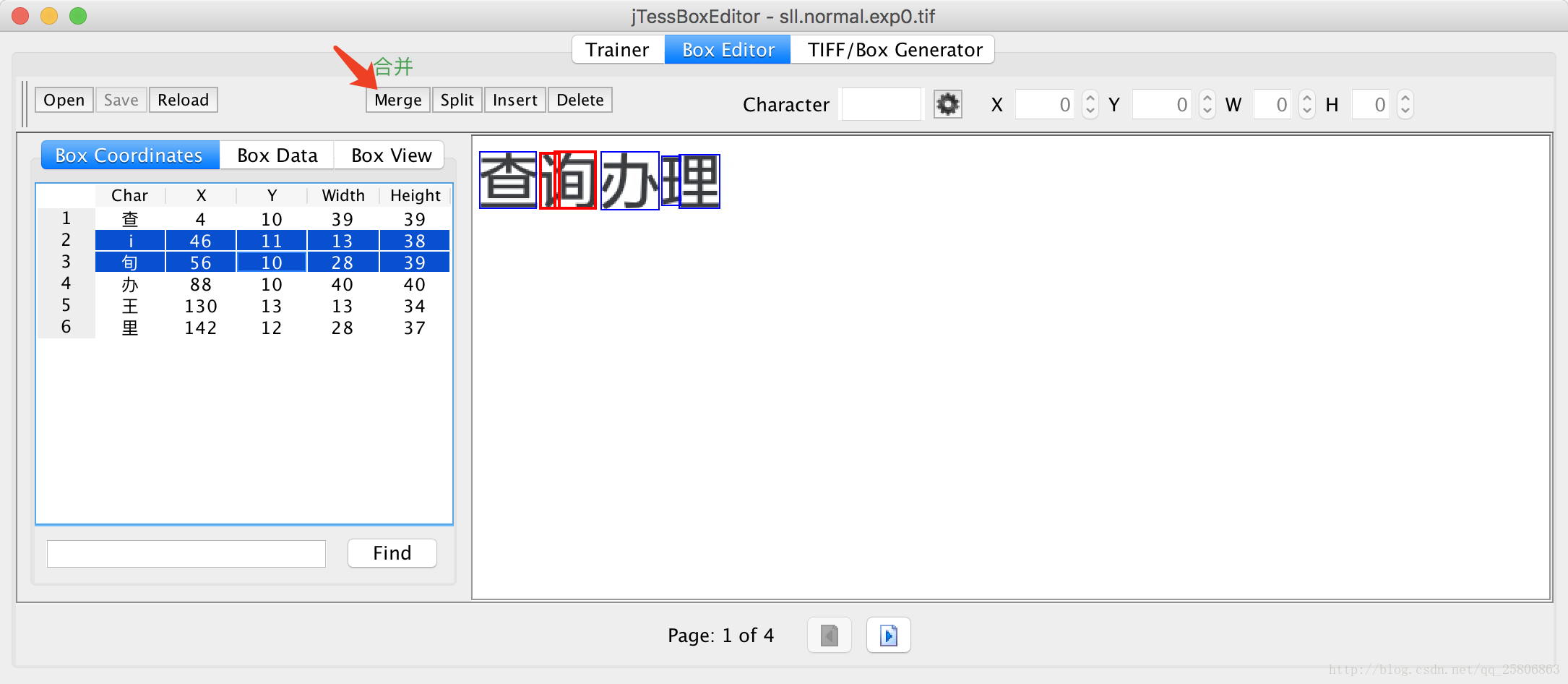
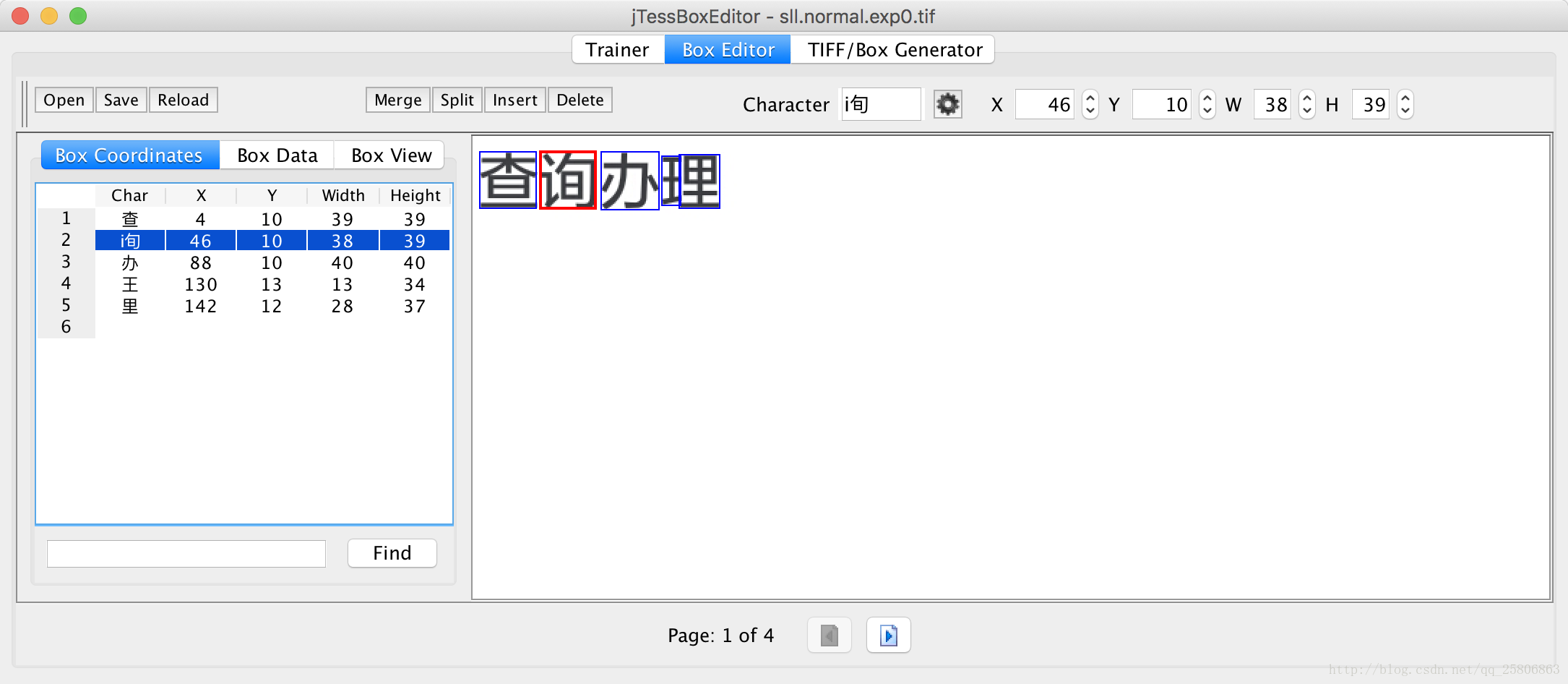
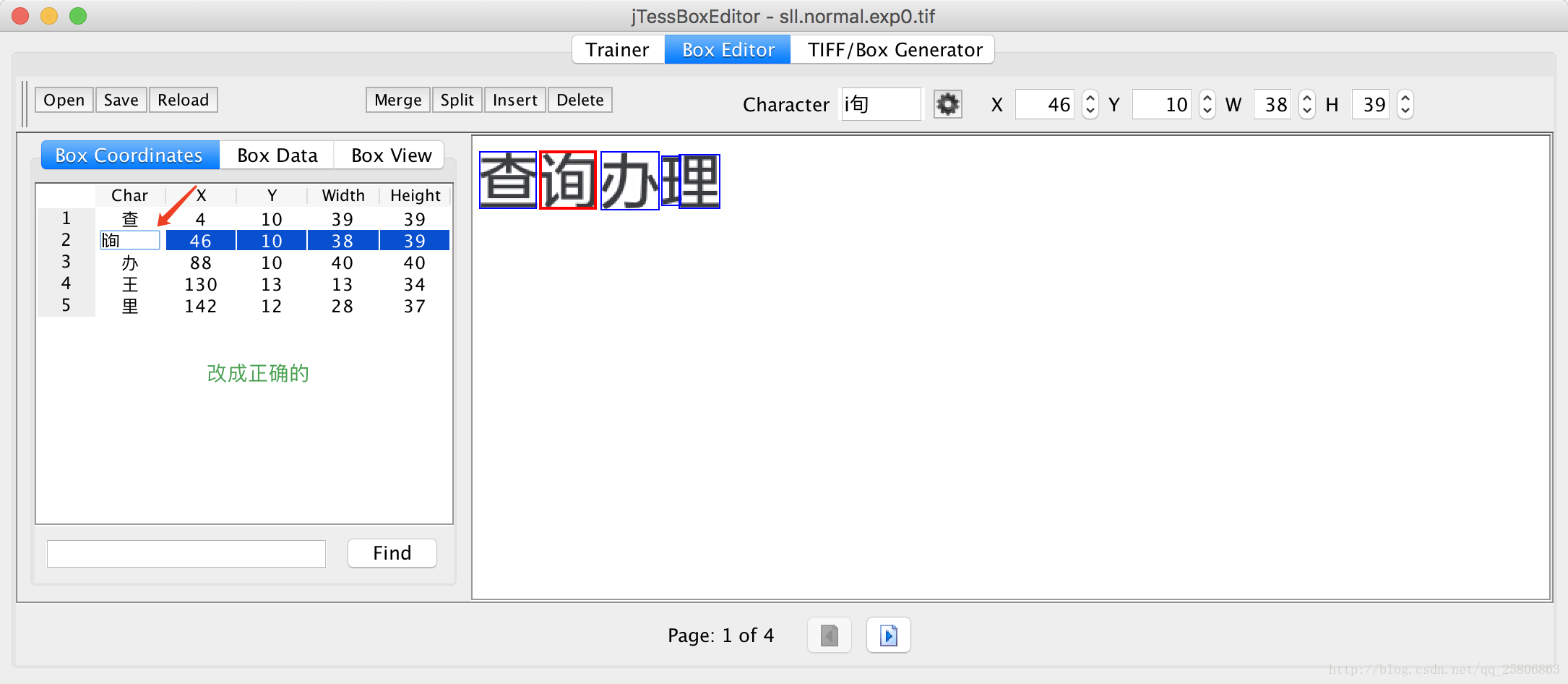
全部修改完后点击save。
用脚本生成
下面的步骤可以写一个脚本自动完成。生成box文件就一行代码,就不用写了。
比如,在new文件夹下创建一个gettraineddata.shell,里面写
#!/bin/sh
read -p "输入你语言:" lang
echo ${lang}
read -p "输入你的字体:" font
echo ${font}
echo "所以完整文件名为:"
echo ${lang}.${font}.exp0.tif
echo "开始。。。"
echo ${font} 0 0 0 0 0 >font_properties
tesseract ${lang}.${font}.exp0.tif ${lang}.${font}.exp0 nobatch box.train
unicharset_extractor ${lang}.${font}.exp0.box
shapeclustering -F font_properties -U unicharset ${lang}.${font}.exp0.tr
mftraining -F font_properties -U unicharset -O unicharset ${lang}.${font}.exp0.tr
cntraining ${lang}.${font}.exp0.tr
echo "开始重命名文件"
mv inttemp ${font}.inttemp
mv normproto ${font}.normproto
mv pffmtable ${font}.pffmtable
mv shapetable ${font}.shapetable
mv unicharset ${font}.unicharset
echo "生成最终文件"
combine_tessdata ${font}.
echo "完成"当然里面的东西可以改,要输入的语言和字体是根据tif文件的名字来的
比如我的文件是sll.normal.exp0.tif
所以就这样输入

如果不出错,就能看见new里面变成了这样

有了我们需要的normal.traineddata识别库。
生成font_properties
在new文件夹中执行下面命令,会生成一个font_properties文件,里面的内容是normal 0 0 0 0 0 。
echo normal 0 0 0 0 0 >font_properties
六个代表的东西是 fontname italic bold fixed serif fraktur
像第一个是字体名,前面我起的是normal。
后面的值是0或1,可以看一下默认的文件font_properties
生成
接下来就是一条条命令生成一个个文件了
训练
tesseract sll.normal.exp0.tif sll.normal.exp0 nobatch box.train
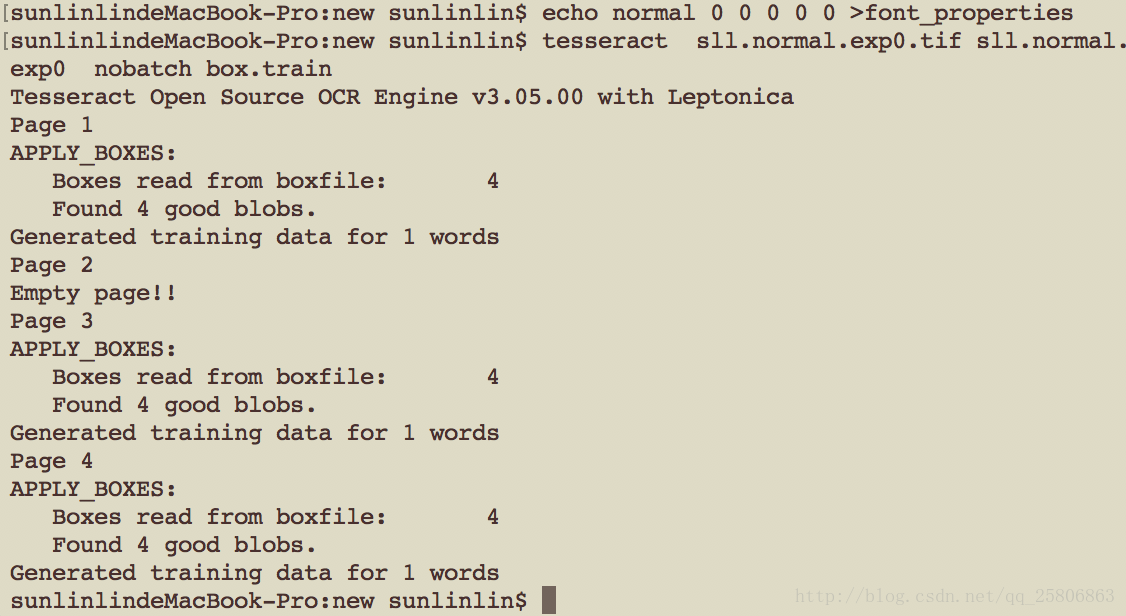
生成字符集文件
unicharset_extractor sll.normal.exp0.box

生成shape文件
shapeclustering -F font_properties -U unicharset sll.normal.exp0.tr

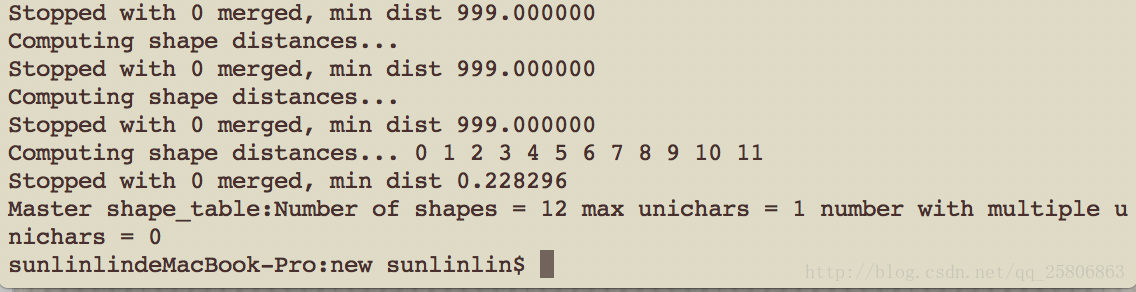
生成聚集字符特征文件
mftraining -F font_properties -U unicharset -O unicharset sll.normal.exp0.tr
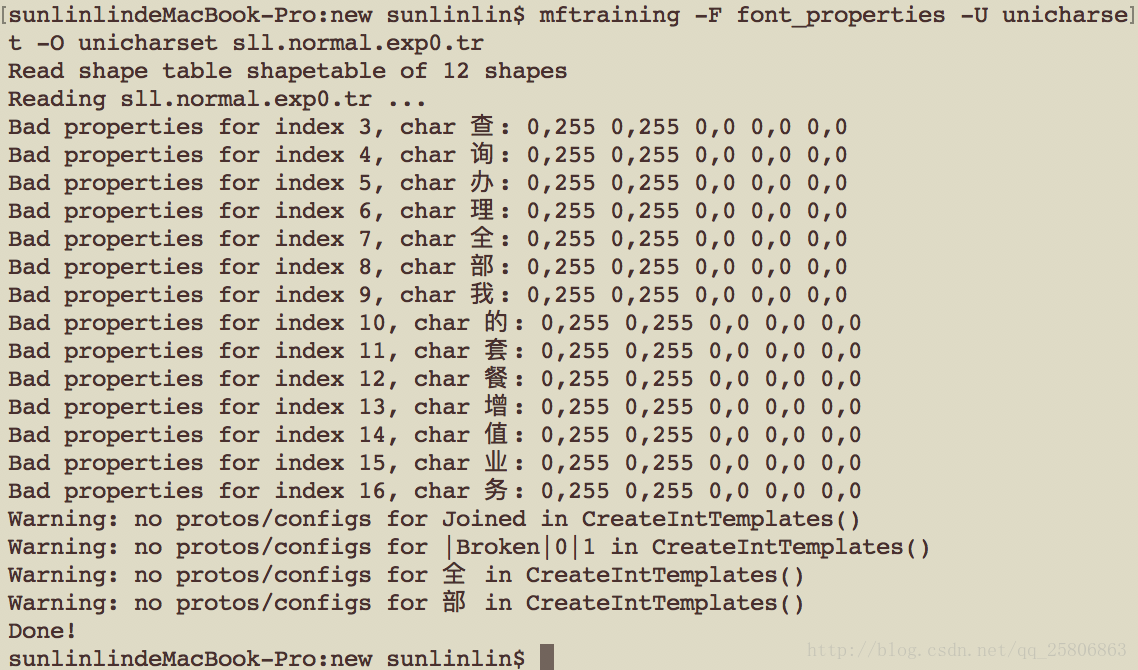
生成字符正常化特征文件
cntraining sll.normal.exp0.tr

合成最终文件
改名
上面几步完成后,会看到下面五个文件
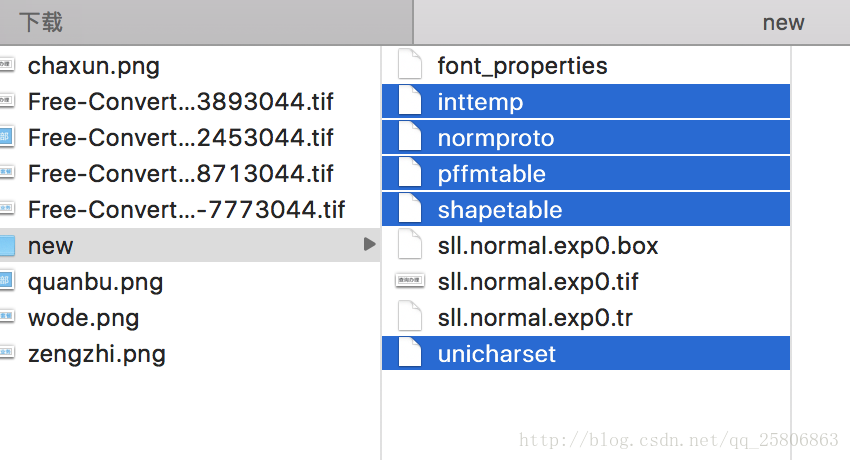
然后全部重命名,前面加上normal. 就是字体名,变成
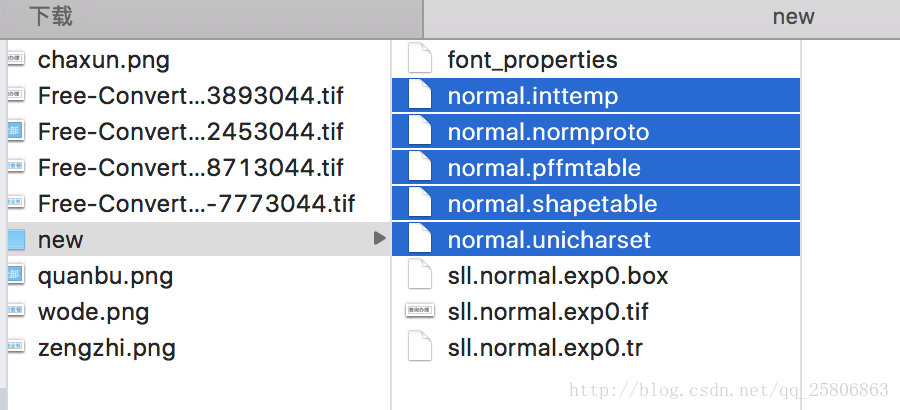
合并字库文件
combine_tessdata normal.
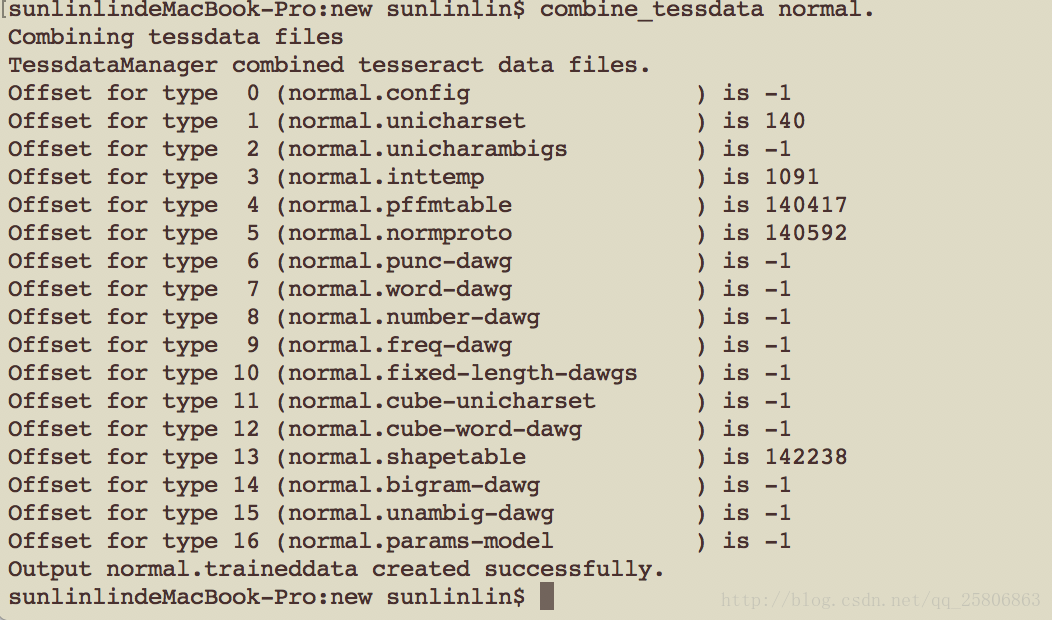
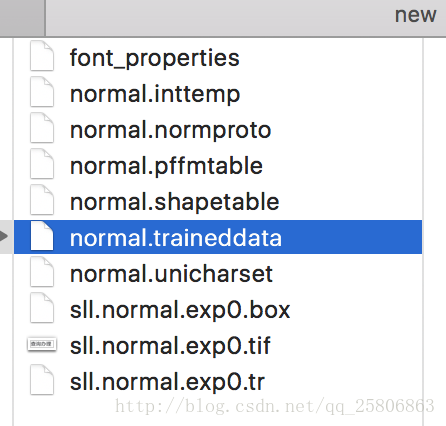
看 哇 拿到了我们需要的normal.traineddata文件。
必须确定的是第type 1、3、4、5的数据不是-1,才算成功。
然后按上一篇的方法用吧!
参考http://www.cnblogs.com/zhongtang/p/5555950.html?utm_source=tuicool&utm_medium=referral
参考http://www.cnblogs.com/wzben/p/5930538.html


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









