







昨天介绍了视频编解码的原理,内容实属困难啊!脑细胞死一片。。。今天来点简单的,写完就去吃午饭!
- 主流的视频编码算法
- MPEG-4和H.264区别
- H.264特点
- 视频解码的原理及主流解码器
- 解码原理
- 专用芯片型和可编程型特点
- 开源的视频编解码器(CODEC)
主流视频编码算法
编码算法具有高计算量和受实现平台的影响等特点,所以技术一直在不断地完善,主流是MPEG-4和H.264。而且市场需求量也是很大的,但出现一个问题:就是每个领域都有几家特别牛逼的几家公司在哪里,人家大而不倒,你想跻身进入500强,没有强悍的身板(高质量的技术),你怕站不住啊!
MPEG-4和H.264区别
MPEG-4是ISO组织制定的音视频编解码算法,主要针对网络、视频会议和可视电话等低码率传输应用;
H.264是ITU-T和ISO联合组织JVT制定的视频编解码标准,在MPEG-4中是Part-10,称为AVC(Advanceel Video Ccoding),在ITU中称为H.264。
H.264特点
H.264算法还是基于块的混合编码技术,编码过程基本与以前的编码标准相同,只是每个功能模块都进行了技术更新,帧内预测、帧间预测、整数DCT变换、环路滤波、熵编码等模块都做了技术提升。
(1)NAL与VCL
网络适配层NAL(Network Abstraction Layer)是H.264为适应网络传输应用而制定的一层数据打包操作。传统的视频编码算法编完的视频码流在任何应用领域下(无论用于存储、传输等)都是统一的码流模式,视频码流仅有视频编码层VCL(Video Coding Layer)。而H.264可根据不同应用增加不同的NAL片头,以适应不同的网络应用环境,减少码流的传输差错。
(2)帧内预测
H.264为能进一步利用图像的空间相关性,H.264引入了多模式的帧内预测以提高压缩效率。简单地说,帧内预测编码就是用周围邻近的像素值来预测当前的像素值,然后对预测误差进行编码。预测是基于块的,亮度分量(Luma)块的大小可以在16×16和4×4之间选择,16×16块有4种预测模式,4×4块有9种预测模式;色度分量
(Chroma)预测是对整个8×8块进行的,预测模式同亮度16×16的4种预测模式。
(3)帧间预测
帧间预测即传统的运动估计ME加运动补偿MC,H.264的运动估计更精准、快速,效果更好。
1)多变的宏块大小
传统的运动估计块大小是16×16,由于运动物体复杂多变,仅使用一种模式效果不好。H.264采用了7种方式对一个宏块进行分割,分别为16×16、16×8、8×16、8×8、8×4、4×8、4×4,每种方式下块的大小和形状都不相同,这就使编码器可以根据图像的内容选择最好的预测模式。实验表明,与仅使用16×16块进行预测相比,使用不同大小和形状的块可以使码率节省15%以上。
2)更精细的像素精度
在H.264算法中,Luma分量的运动矢量MV使用1/4像素精度。Chroma分量的MV由Luma MV导出,由于Chroma分辨率是Luma的一半(YUV4:2:0),所以其MV精度将为1/8。如此精细的预测精度较之整数精度可以使码率节省超过20%。
3)更多参考帧
H.264支持多参考帧预测(Multiple Reference Frames),即可以有多于1个(最多5个)的在当前帧之前解码重建的帧,作为参考帧产生对当前帧的预测(Motion-compensated Prediction)。这特别适用于视频序列中含有周期性运动的情况。
4)环路滤波
环路滤波(Loop Filter)的作用是,消除经反量化和反变换后重建图像中由于预测误差产生的块效应,从而一方面改善图像的主观质量,另一方面减少预测误差。与以往的Deblocking Filter不同的是,经过滤波后的图像将根据需要放在缓存中用于帧间预测,而不是仅仅在输出重建图像时用来改善主观质量,也就是说该滤波器位于解码环中,而非解码环的输出外,因而得名Loop Filter。
(4)整数DCT变换
传统的DCT是由浮点算法定点实现,所以IDCT不是可逆的,容易造成解码图像的周围“拖尾”现象。H.264对帧内或帧间预测的残差(Residual)进行整数DCT变换编码。新标准对DCT的定义做了修改,使得变换仅用整数加减法和移位操作即可实现,这样在不考虑量化影响的情况下,解码端的输出可以准确地恢复编码端的输入。此外,该变换是针对4×4块进行的,这也有助于减少块效应。为了进一步利用图像的空间相关性,在对色度(Chroma)的预测残差和16×16帧内预测的预测残差进
行上述整数DCT变换之后,标准还将每个4×4变换系数块中的DC系数组成2×2或4×4大小的块,进一步做哈达玛(Hadamard)变换。
(5)熵编码
对于预测残差,H.264有两种熵编码的方式:基于上下文的自适应变长码
CAVLC(Context-based Adaptive Variable Length Coding)和基于上下文的自适应二进制算术编码CABAC(Context-based Adaptive Binary Arithmetic Coding);如果待编码的数据不是预测残差这一类型,则H.264采用Exp-Golomb码或CABAC来编码,具体选用哪种编码类型视编码器的设置而定。
1)CAVLC
可变字长编码VLC的基本思想就是,对出现频率大的符号使用较短的码字,而出现频率小的符号采用较长的码字,这样可以使平均码长最小。在CAVLC中,H.264采用若干VLC码表,不同的码表对应不同的概率模型。编码器能够根据上下文,如周围块的非零系数或系数的绝对值大小,在这些码表中自动地选择,最大可能地与当前数据的概率模型匹配,从而实现了上下文自适应的功能。
2)CABAC
算术编码是一种高效的熵编码方案,其每个符号所对应的码长被认为是分数。由于每一个符号的编码都与以前编码的结果有关,所以它考虑的是信源符号序列整体的概率特性,而不是单个符号的概率特性,因而它能够更大程度地逼近信源的极限熵,极大的降低码率。
视频解码的原理及主流解码器
根据编码的过程,解码就是编码的逆操作。但在编码的操作中已经有所体现,对于MPEG-4视频编解码算法来说,在图像或残差做DCT变换、量化后,接着是反量化、IDCT变换,然后将重建的数据补偿到编码图像中,从而保证解码时数据不会产生偏差。而实际的解码器只是增加了熵解码的操作,后续的处理与编码器中的图像帧重建是相同的。
解码原理
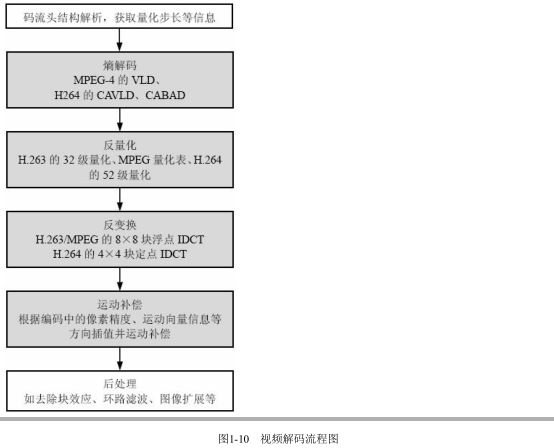
首先解析码流的头数据,获取编码图像的有关参数,包括帧编码类型(I/P)、图像宽度或高度等,后续就是以宏块为单位循环解码,图中的阴影框表示以宏块为处理单元循环执行。熵解码是可变长编码VLC的逆操作,即VLD。H.263/MPEG-1/2/4是Huffman熵解码,即通常意义上的VLD,而H.264则是采用了算术解码,又包括CAVLD、CABAD。另外,
对于帧间编码的宏块,解码器还要解析出当前宏块的运动向量。熵解码后是反量化操作,反量化就是量化结果乘以量化步长,对于不同的解码算法又有不同的反量化处理,H.263采用了32级的均匀量化,即宏块数据采取一个量化步长;MPEG-4除了支持H.263的均匀量化外,还增加了量化表的处理方式;H.264采用了52级的均匀量化方式。反量化处理后,进行反变换IDCT,对H.263/MPEG-1/2/4采取了8×8块的浮点式IDCT,H.264采取了4×4的整数ICT。运动补偿是解码器中的重点,占用了约60%以上的计算负荷,这是因为码流统计中帧间编码为主要的编码类型,而与之对
应的处理就是插值运动补偿,根据从码流中解析的运动向量信息,定位参考帧的确切位置,然后计算1/2、1/4像素精度的插值,最后把结果补偿(加)到重建帧中。解码器中的最后处理是可选的去除块效应(MPEG-4)、环路滤波(H.264)、图像扩展等。
之前说过,MPEG-4/H.264标准协议给出的只是一个框架或码流的语义,并没有统一的标准对于如何实现编码器或者解码器。所以借助芯片,从实现平台或可升级等特点,主要有专用芯片型和可编程型。
ASIC(专业芯片)的特点
芯片制造商预先把编码系统用固化的专用硬件加以实现,保证上电即工作。开发用户只需对芯片作整体简单的初始化或对电阻电容的工作电压或电流的配置,输入视频,输出码流,因此编码芯片对开发者来说是黑盒
子。基于ASIC芯片的视频编解码系统的开发周期短,系统相对较稳定,易快速的批量生产。但是,系统不可升级,无论是功能增加升级或不稳定因素解除,其均无能为力。MPEG-4编码芯片有VW2010,H.264编码芯片有富士通的MB86H51,华为海思的Hi351x,美信MG2580/3500等。另外,芯片除了实现编解码外,还内嵌了ARM等处理器以侧重运行操作系统,如Hi351x、MG3500等芯片。
可编程性芯片特点
开发者利用高级或低级开发语言,根据视频算法功能开发出来的视频产品。通用的CPU(Intel/AMD)、GPU、DSP、FPGA等均为可编程芯片,跨平台的C语言或类似语言等基本都能基于这些芯片进行算法开发。
个人电脑PC的CPU功能强大,VC/VB等高级开发软件允许用户充分发挥个人的聪明才智,开发底层的数据处理算法或高层的人机用户应用程序。针对图像图形处理的GPU,强大的流水处理、单指令多数据SIMD操作、图像专用处理模块等极大增强了用户的图像开发能力。数字媒体的信号处理平台DSP以其独特的资源和功能配置结构,有针对性的数字媒体处理芯片等为开发者提供了便利而又强大的开发资源。数字媒体可编程处理器的最大特点是开发者能够掌握知识产权,易维护升级、功能定制。同时,独有的视频处理功能显著增加一般视频编码系统的附加值,形成自己特色的视频处理产品。
开源的视频编解码器(CODEC)
开发底层语言通常采用C语言编程,一般是基于视频编码协议,由专业的大神开发的快速且实用的算法工程。
ffdshow
一个支持多种音视频格式的基于DirectShow及VFW的CODEC集合,包
含:H.264、MPEG-4、MPEG-2、H.263、VP3、VP6、Theora、MJPEG、SVQ3、MP3、AC3、DTS、E-AC3、AAC和Vorbis。
ffmpeg
一个完整的跨平台音视频解决方案,能记录、转换和流处理音视频,
并包含领先的音视频CODEC库——libavcodec。
VLC
一个免费、开源的跨平台多媒体播放器和框架,能够播放大部分多媒体
文件,包括DVD、音频CD、VCD和各种流媒体。
Xvid
一个开源的MPEG-4视频编码和解码CODEC,实现了MPEG-4的
SP(Simple Profile)和ASP(Advanced Simple Profile)等档级。
T264
一个实现H.264视频编码和解码的开源算法,但是码流与H.264标准协议
略有不同,编程风格类似Xvid。
x264
一个免费的H.264视频编码开源算法,编码后的码流符合H.264/AVC格
式,很多H.264视频编码方案几乎都基于该蓝本。它与VLC同属于一个组织VideoLAN。
JM
JVT提供的H.264协议的参考校验模型,包括视频编码和解码两部分。目前,该模型的最新版本为JM17.2。MPEG-1和MPEG-2编解码源码从MPEG的主页上可直接获取。
小结
主流的视频编码算法基本是混合编解码技术,即包含预测、变换、量化和编码等步骤。帧间编码是视频编码压缩的主要方式,而帧间预测即运动估计算法是编码系统的核心。当下主流的视频编码算法主要有MPEG-4和H.264。个人觉得技术什么是很重要的,毕竟是程序员的饭碗,开发一个新技术或者在前人的基础上优化改进都一样有意义。博客内容均来自书籍,如有不足之处,敬请指出,我会积极采纳改进,我是Mr.小艾。














 2291
2291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









