







一、摘要
贝叶斯分类是一类分类算法的总称,这类算法以贝叶斯定理为基础,所以统称为贝叶斯分类。
二、分类问题综述
已知集合:和
,确定映射规则
,使得任意
有且仅有一个
使得
成立。那么,C叫做类别集合,其中每一个元素是一个类别;I叫做项集合,其中每一个元素是待分类项;f是分类器。分类算法的任务就是构造分类器。
这里要着重强调,分类问题往往采用经验性方法构造映射规则,即一般情况下的分类问题缺少足够的信息来构造100%正确的映射规则,而是通过对经验数据的学习从而实现一定概率意义上正确的分类,因此所训练出的分类器并不是一定能将每个待分类项准确映射到其分类,分类器的质量与分类器构造方法、待分类数据的特性以及训练样本数量等诸多因素有关。
例如,医生对病人进行诊断就是一个典型的分类过程,任何一个医生都无法直接看到病人的病情,只能观察病人表现出的症状和各种化验检测数据来推断病情,这时医生就好比一个分类器,而这个医生诊断的准确率,与他当初受到的教育方式(构造方法)、病人的症状是否突出(待分类数据的特性)以及医生的经验多少(训练样本数量)都有密切关系。
三、贝叶斯分类基础——贝叶斯定理
每次提到贝叶斯定理,我心中的崇敬之情都油然而生,倒不是因为这个定理多高深,而是因为它特别有用。这个定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率:
P(A|B)表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:。
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。
下面不加证明地直接给出贝叶斯定理:
四、朴素贝叶斯分类
朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。(在黑人此项出现的情况下,判别此黑人是哪个国家类别的概率)为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。
朴素贝叶斯分类的正式定义如下:
1、设为一个待分类项,而每个a为x的一个特征属性。
2、有类别集合。
3、计算。
4、如果,则
。
那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。(找例子)
2、统计得到在各类别下各个特征属性的条件概率估计。即(各个类别事前由人工已经分类好了)。
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
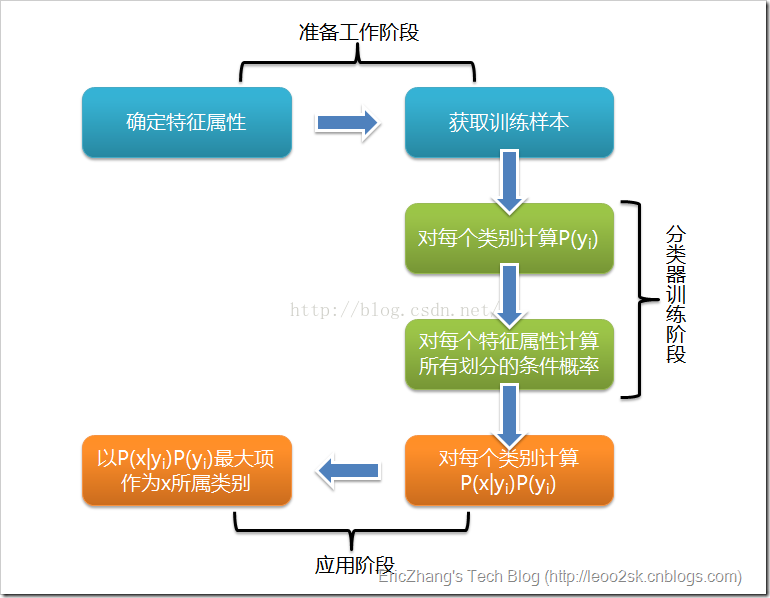
可以看到,整个朴素贝叶斯分类分为三个阶段:
第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
五、朴素贝叶斯分类实例:检测SNS社区中不真实账号
下面讨论一个使用朴素贝叶斯分类解决实际问题的例子,为了简单起见,对例子中的数据做了适当的简化。
这个问题是这样的,对于SNS社区来说,不真实账号(使用虚假身份或用户的小号)是一个普遍存在的问题,作为SNS社区的运营商,希望可以检测出这些不真实账号,从而在一些运营分析报告中避免这些账号的干扰,亦可以加强对SNS社区的了解与监管。
如果通过纯人工检测,需要耗费大量的人力,效率也十分低下,如能引入自动检测机制,必将大大提升工作效率。这个问题说白了,就是要将社区中所有账号在真实账号和不真实账号两个类别上进行分类,下面我们一步一步实现这个过程。
首先设C=0表示真实账号,C=1表示不真实账号。
1、确定特征属性及划分
这一步要找出可以帮助我们区分真实账号与不真实账号的特征属性,在实际应用中,特征属性的数量是很多的,划分也会比较细致,但这里为了简单起见,我们用少量的特征属性以及较粗的划分,并对数据做了修改。
我们选择三个特征属性:a1:日志数量/注册天数,a2:好友数量/注册天数,a3:是否使用真实头像。在SNS社区中这三项都是可以直接从数据库里得到或计算出来的。
下面给出划分:a1:{a<=0.05, 0.05<a<0.2, a>=0.2},a2:{a<=0.1, 0.1<a<0.8, a>=0.8},a3:{a3=0(不是),a3=1(是)}。
2、获取训练样本
这里使用运维人员曾经人工检测过的1万个账号作为训练样本。
3、计算训练样本中每个类别的频率
用训练样本中真实账号和不真实账号数量分别除以一万,得到:
4、计算每个类别条件下各个特征属性划分的频率
5、使用分类器进行鉴别
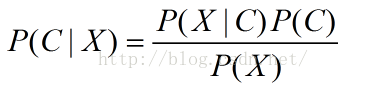
下面使用上面训练得到的分类器鉴别一个账号,这个账号使用非真实头像,日志数量与注册天数的比率为0.1,好友数与注册天数的比率为0.2。
可以看到,虽然这个用户没有使用真实头像,但是通过分类器的鉴别,更倾向于将此账号归入真实账号类别。这个例子也展示了当特征属性充分多时,朴素贝叶斯分类对个别属性的抗干扰性。
参考资料:朴素贝叶斯原理













 1804
1804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









