







Naive Bayes(朴素贝叶斯)算法
什么是Navi Bayesian?
朴素贝叶斯是基于贝叶斯定理并假设预测变量之间具有独立性的最简单,最强大的分类算法之一。
举例
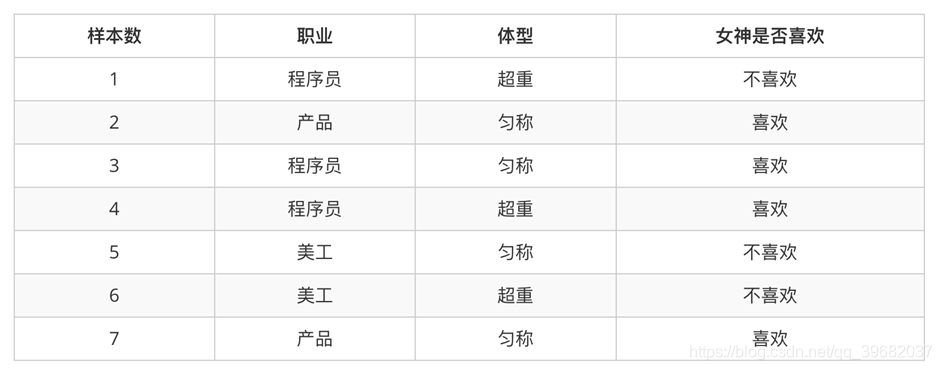
1、女神喜欢的概率? 4/7
2、职业是程序员并且体型匀称的概率? (3/7) * (4/7)=12/49
3、在女神喜欢的条件下,职业是程序员的概率? 1/2
4、在女神喜欢的条件下,职业是产品,体重是超重的概率? (1/2)*(1/4)=1/8
对于这几个问题,读者朋友的答案是否正确呢。如果不知道或者错了,不必灰心,请继续往下阅读。
联合概率和条件概率
联合概率:包含多个条件,且所有条件同时成立的概率
记作:𝑃(𝐴,𝐵)
条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率
记作:𝑃(𝐴|𝐵)
特性:P(A1,A2|B) = P(A1|B)P(A2|B)
注意:此条件概率的成立,是由于A1,A2相互独立的结果
由此我们可以看出,朴素贝叶斯的最佳使用场景是特征独立时,多用于文档分类。
朴素贝叶斯-贝叶斯公式
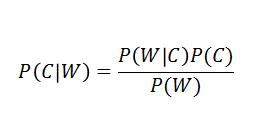
注:w为给定文档的特征值(频数统计,预测文档提供),c为文档类别
公式可以理解为:
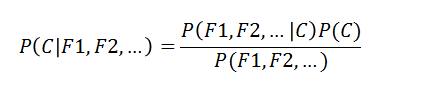
- 𝑃(𝐶):每个文档类别的概率(某文档类别词数/总文档词数)
- 𝑃(𝑊│𝐶):给定类别下特征(被预测文档中出现的词)的概率
计算方法:𝑃(𝐹1│𝐶)=𝑁𝑖/𝑁 (训练文档中去计算)
𝑁𝑖为该𝐹1词在C类别所有文档中出现的次数
N为所属类别C下的文档所有词出现的次数和
- 𝑃(𝐹1,𝐹2,…) 预测文档中每个词的概率
其中c可以是不同类别。
举例
从诸多文档中统计出重要的词的列表

现有一篇被预测文档:出现了影院,支付宝,云计算,计算属于科技、娱乐的类别概率?
科技:𝑃(影院,支付宝,云计算 │科技)∗P(科技)=8/100∗20/100∗63/100∗(100/221) =0.00456109
娱乐:𝑃(影院,支付宝,云计算│娱乐)∗P(娱乐)=56/121∗15/121∗0/121∗(121/221)=0
存在一个类别的概率为0,这样合理吗?
解决方法:采用拉普达斯平滑系数

知识储备:
sklearn朴素贝叶斯实现API
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
- alpha:拉普拉斯平滑系数
代码演示
一个简单的新闻分类流程
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfVectorizer
def navibayes():
'''
朴素贝叶斯文本分类
:return: None
'''
news = fetch_20newsgroups(subset='all')
#进行数据分割
x_train, x_test, y_train, y_test = train_test_split(news.data,news.target,test_size=0.25)
#对数据集进行特征抽取
tf = TfidfVectorizer()
#以训练集中的词的列表进行重要性统计
x_train = tf.fit_transform(x_train)
print(tf.get_feature_names())
x_test = tf.transform(x_test)
#进行朴素贝叶斯算法预测
mlt = MultinomialNB(alpha=1.0)
print(x_train)
mlt.fit(x_train,y_train)
y_predict = mlt.predict(x_test)
print("预测的文章类别为:",y_predict)
#得出准确率
print("准确率为:",mlt.score(x_test,y_test))
return None
if __name__ == "__main__":
navibayes()














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









