







动态规划(DP)是指,当给出一个具体的环境模型已知的马尔科夫决定过程(MDP),可以用于计算其最佳策略的算法集合。经典DP算法在强化学习中的实用性有限,因为他们假定了一个具体的模型,并且还受限于它们的计算cost很高,但它在理论上仍然很重要。
策略迭代
通用策略迭代是:
1. 先从一个策略
π0
开始,
2. 策略评估(Policy Evaluation) - 得到策略
π0
的价值
vπ0
3. 策略改善(Policy Improvement) - 根据价值
vπ0
,优化策略
π0
。
4. 迭代上面的步骤2和3,直到找到最优价值
v∗
,因此可以得到最优策略
π∗
(终止条件:得到了稳定的策略
π
和策略价值
vπ
)。
这个被称为通用策略迭代(Generalized Policy Iteration)。
数学表示如下:
因此,我们需要关心两个问题:如何计算策略的价值,以及如何根据策略价值获得一个优化的策略。即策略评估和策略优化。
总体框架如下图:

下面分别讲解策略评估(Policy Evaluation)和策略改善(Policy Improvement)。
策略评估
策略评估是通过状态值函数来实现的,值函数定义为(
S+比S多了一个终止状态
):
此时,s状态的值函数是由其他所有状态在策略 π 下的值函数确定,这是无法计算的。所以DP通过当前的策略 π 计算下一时刻的状态值函数。在多次迭代后( k→∞ ), vk≈vπ

策略优化
可以证明,最大化动作状态值函数的同时也会最大化状态值函数(P83)。所以策略优化通过最大化动作状态值函数实现。
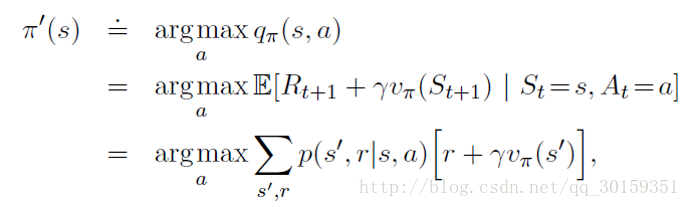
由此可以得到前面策略迭代的流程框图。
价值迭代
价值迭代方法是对上面所描述的方法的一种简化:
在策略评估过程中,对于每个状态s,只找最优(价值是最大的)行动a。这样可以减少空间的使用。步骤如下:
1. 初始化 - 所有状态的价值(比如:都设为0)。
2. 初始化 - 一个等概率随机策略
π0
(the equiprobable random policy)
3. 策略评估
对于每个状态s,只找最优(价值是最大的)行动a。即:
价值迭代不需要优化过程,最后输出的策略直接选取最大的值函数即可:















 6578
6578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









