







简介
有时候,我们天真无邪的使用urllib库或Scrapy下载HTML网页时会发现,我们要提取的网页元素并不在我们下载到的HTML之中,尽管它们在浏览器里看起来唾手可得。
这说明我们想要的元素是在我们的某些操作下通过js事件动态生成的。举个例子,我们在刷QQ空间或者微博评论的时候,一直往下刷,网页越来越长,内容越来越多,就是这个让人又爱又恨的动态加载。
爬取动态页面目前来说有两种方法
- 分析页面请求(这篇介绍这个)
- selenium模拟浏览器行为(霸王硬上弓,以后再说)
言归正传,下面介绍一下通过分析页面请求的方法爬取动态加载页面的思路。中心思想就是找到那个发请求的javascript文件所发的请求。
举两个例子,京东评论和上证股票。
后注:本文的两个例子都是get请求,可以显示的在浏览器中查看效果,如果是post请求,需要我们在程序中构造数据,构造方法可以参考我从前的一篇博文Scrapy定向爬虫教程(六)——分析表单并回帖。
京东评论
这是一个比较简单的例子。
首先我们随便找一个热卖的商品,评论比较多。
就这个吧威刚(ADATA) SU800 256G 3D NAND SATA3固态硬盘。
点进去看看这个页面现在的状况
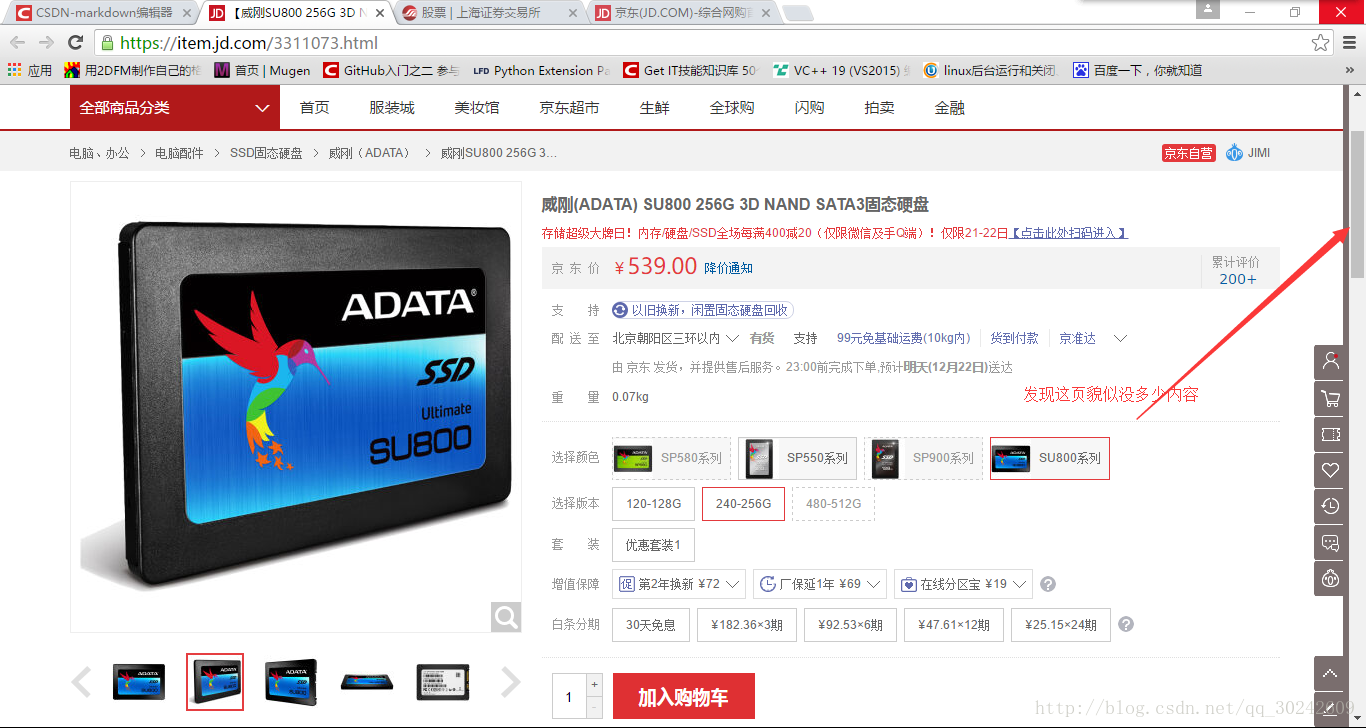
滚动条给的第一印象感觉这页仿佛没多少内容。
键盘F12打开开发者工具,选择Network选项卡,选择JS(3月12日补:除JS选项卡还有可能在XHR选项卡中,当然也可以通过其它抓包工具),如下图
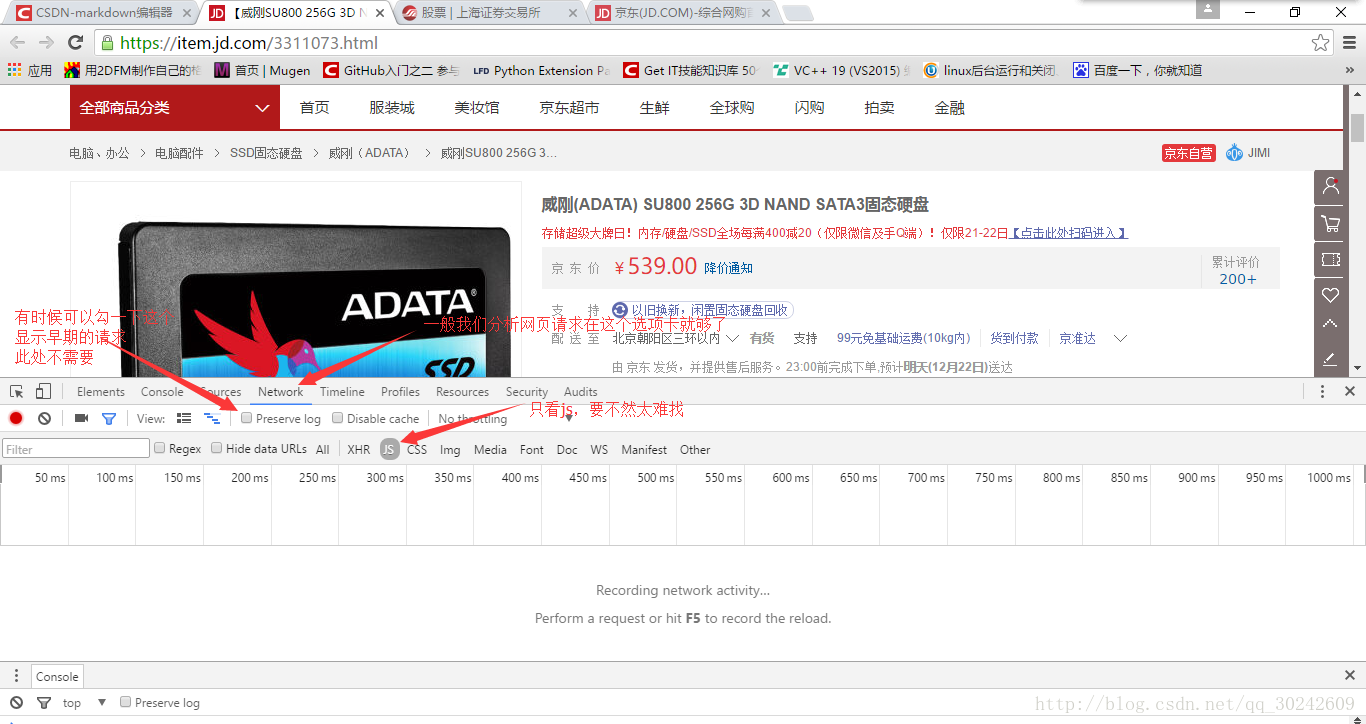
然后,我们来拖动右侧的滚动条,这时就会发现,开发者工具里出现了新的js请求(还挺多的),不过草草翻译一下,很容易就能看出来哪个是取评论的,如下图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











