







读论文《Efficient Estimation of Word Representations in Vector Space》
原文地址:http://blog.csdn.net/qq_31456593/article/details/77513173
introduce
词的分布式表示(又称词嵌入,word embedding)因为这篇文章开始大火,原来的word embedding只是神经网络语言模型的副产物,而该论文的主要的目标是训练具有语义特征的word embedding。
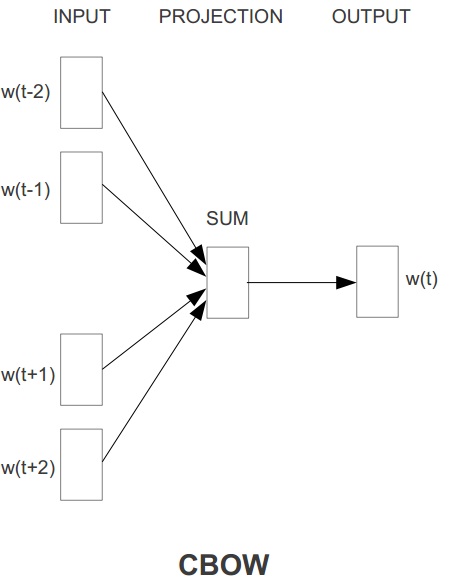
本文体提出了2个模型,一个是Continuous Bag-of-WordS Model(CBOW),一个是Continuous Skip-gram Model(Skip-gram)
其中CBOW是用上下文的词预测中间词,Skip-gram是用中间词预测上下文的词。
考虑到原来的神经语言模型算法复杂度高,训练时间长,本文的两个网络都去掉了非线性隐藏层,并在输出层使用哈夫曼树结构进行hierarchical softmax,使复杂度大大降低,一天的时间就可以训练16亿单词量的语料。且最终生成的词嵌入满足类似king-man+women=queen的语义关系。
method
论文的2个模型如下文所示
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 7198
7198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









