







LR是很多分类算法的基础组件,它的好处是输出值自然地落在0到1之间,并且有概率意义。模型清晰,背后的概率学经得住推敲。它拟合出来的参数就代表了每一个特征(feature)对结果的影响。
Logistic回归分析:
优势比:
假设在m个独立自变量 x 1 , x 2 ⋯   , x m x _{1},x_{2}\cdots ,x _{m} x1,x2⋯,xm的作用下,记取1的概率是 p = P ( y = 1 ∣ X ) p=P(y=1|X) p=P(y=1∣X),取0概率是 1 − p 1-p 1−p,则概率之比为 p 1 − p \frac{p}{1-p} 1−pp,称为事件的优势比(odds),又称为OR。
Logistic函数:
对odds取自然对数即得Logistic变换
L
o
g
i
t
(
p
)
=
l
n
p
1
−
p
Logit(p)=ln\frac{p}{1-p}
Logit(p)=ln1−pp(又称为对数几率,log odds)令
L
o
g
i
t
(
p
)
=
l
n
p
1
−
p
=
z
Logit(p)=ln\frac{p}{1-p}=z
Logit(p)=ln1−pp=z,则
p
=
1
1
+
e
−
z
p=\frac{1}{1+e^{-z}}
p=1+e−z1 即为Logistic函数,也称为sigmoid函数,如图:
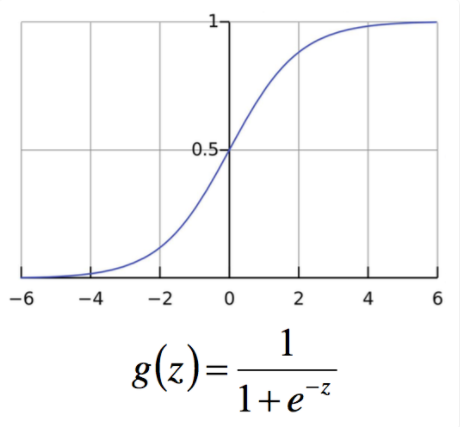
当p在(0,1)变化时,odds的取值范围是(0,+∞),则 l n p 1 − p ln\frac{p}{1-p} ln1−pp的取值范围为(-∞,+∞)
Logistic回归模型:
Logistic回归模型是建立在
l
n
p
1
−
p
ln\frac{p}{1-p}
ln1−pp与自变量的线性回归模型。
Logistic回归模型为:
因为
l
n
p
1
−
p
ln\frac{p}{1-p}
ln1−pp的取值范围为(-∞,+∞),所以
x
1
,
x
2
⋯
 
,
x
m
x _{1},x_{2}\cdots ,x _{m}
x1,x2⋯,xm可以在任意范围内取值。
记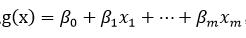
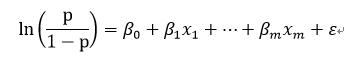
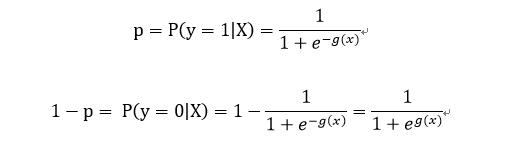
Logistic回归模型的解释:
-
β 0 \beta _{0} β0:在没有自变量,即 x 1 , x 2 ⋯   , x m x _{1},x_{2}\cdots ,x _{m} x1,x2⋯,xm全部取0, y = 1 y=1 y=1与 y = 0 y=0 y=0发生概率之比的自然对数;
β i \beta _{i} βi:某自变量 x i x _{i} xi变化时,即 y i = 1 y _{i}=1 yi=1与 y i = 1 y _{i}=1 yi=1相比,y=1优势比的对数值。 -
函数映射
线性函数的值越接近于正无穷大,概率值就越接近1;反之,其值越接近于负无穷,概率值就越接近0。这样的模型就是LR模型。LR本质上还是线性回归,知识特征到结果的映射过程中加了一层函数映射(即sigmoid函数),即先把特征线性求和,然后使用sigmoid函数将线性和约束至(0,1)之间,结果值用于二分或回归预测。
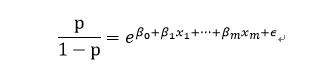
2. Logistic回归建模步骤
- 对已有数据进行特征筛选(逻辑回归本质上还是一种线性回归模型,筛选出来的变量说明与结果具有较强的线性相关性,被筛选掉的特征只能说明与结果之间没有线性关系)。
- 用ln(p/(1-p))与自变量列出回归方程,估计出模型的回归系数。
- 进行模型检验,最基本的检验方法是正确率,其次还有混淆矩阵,ROC曲线,KS值等。
特征筛选:
特征选取是机器学习领域非常重要的一个方向。
- 主要有两个功能:
(1)减少特征数量、降维,使模型泛化能力更强,减少过拟合
(2)增强特征和特征值之间的理解 - 主要方法:
(1)基本的方法方差检验(F值越大和P值越小)。
(2)递归特征消除(RFE)
(3)稳定性选择法(Stability Selection)
性能度量:
机器学习模型性能度量
LR与SVM
两种方法都是常见的分类算法,从目标函数来看,区别在于逻辑回归采用的是logistical loss,svm采用的是hinge loss。这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。两者的根本目的都是一样的。此外,根据需要,两个方法都可以增加不同的正则化项,如l1,l2等等。所以在很多实验中,两种算法的结果是很接近的。但是逻辑回归相对来说模型更简单,好理解,实现起来,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些。但是SVM的理论基础更加牢固,有一套结构化风险最小化的理论基础,虽然一般使用的人不太会去关注。还有很重要的一点,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算量。
两者对异常的敏感度也不一样。同样的线性分类情况下,如果异常点较多的话,无法剔除,首先LR,LR中每个样本都是有贡献的,最大似然后会自动压制异常的贡献,SVM+软间隔对异常还是比较敏感,因为其训练只需要支持向量,有效样本本来就不高,一旦被干扰,预测结果难以预料。
感谢(参考文献)
书籍:python数据分析与挖掘实战
Free Will 博客















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









