







引言
在这篇文章中,我会介绍一些PCA背后的数学概念,然后我们用Wine数据集作为实例,一步一步地实现PCA。最后,我们用更加强大的scikit-learn方便快速地实现PCA,并用逻辑回归来拟合用PCA转换后的数据集。为了让大家更好地理解PCA,整篇文章都贯穿着实例,现在,让我们享受这篇文章吧。
标准差(Standard Deviation)
在引入标准差之前,我先介绍一下平均值,假设我们有个样本集X,其中的样本为 X=[1,2,3,4,5,6] ,求平均值的公式如下:
- X¯ :平均值
- n :样本的个数
- Xi :第 i 个样本
X的平均值为:
求平均值的Python代码如下:
import numpy as np
X=np.array([1,2,3,4,5,6])
np.mean(X)
- 1
- 2
- 3

- 1
- 2
- 3
不幸的是平均值并没有告诉我们关于样本集的很多信息。比如[0,8,12,20]和[8,9,11,12]的平均值都是10,但是它们的数据分散程度有着明显的不同。因此,我们并不满足于仅仅求出一个小小的平均值,它只是一个我们到达伟大目标的一个垫脚石。下面让我们引入标准差,它度量着数据的分散程度。它的公式如下:
上面的公式测量着样本到样本均值的平均距离。你可能会想,分母为什么不是 n 而是 n−1 ?
比如说:你想调查整个人类的生活水平,但是你的能力和精力都是有限的,你不可能调查到世界上的每一个人,因此,你只能找出一部分人来评估整个人类的生活水平。也就是说,你的样本集是现实世界的子集。在这样的情况下,你应该用 n−1 ,它被证明是更加接近标准差的。然而,如果你的样本集是调查了全部的人口,那么你应该用 n 而不是 n−1 。这个解释给你一种直观的感觉,如果你想要看更多的细节,请参考http://mathcentral.uregina.ca/RR/database/RR.09.95/weston2.html
求标准差的python代码如下:
import numpy as np
X=np.array([1,2,3,4,5,6])
np.std(X)
- 1
- 2
- 3

- 1
- 2
- 3
方差(Variance)
方差和标准差一样,都是度量着数据的分散程度。它的公式就是标准差的平方,如下:
求方差的python代码如下:
import numpy as np
X=np.array([1,2,3,4,5,6])
np.var(X)
- 1
- 2
- 3
- 1
- 2
- 3
协方差(Covariance)
方差和标准差只能操作一维的数据集,但是在现实生活中,样本可能有很多的特征,也就是说你的数据集有可能是很多维的。但是,测量样本特征之间的关系很有必要,比如说:我们的样本有2个特征,一个是你的学习时间,一个是你的成绩,那么正常情况下,一定是你的学习时间越长,你的成绩越好。但是,方差和标准差不能度量这种特征之间的关系,而协方差可以。
假设我们有两个特征X,Y。计算它们之间的协方差公式为:
从上面的公式我们能看出 cov(X,Y)和cov(Y,X)的值是一样的。
协方差具体的大小并不重要,但是它的正负是重要的。如果它的值是正的,这表明两个特征之间同时增加或减小;如果它的值是负的,这表明两个特征之间有一个增加而另一个减小。如果它的值为0,则表明两个特征之间是独立的。
在实际应用中,我们样本的特征不可能只有2个,而是有更多的特征。在这种情况下我们用协方差矩阵表示。假设我们的样本有n个特征,这里我用 1,2,3,4,…,n 来表示每个特征。协方差矩阵如下所示:
上面 C 的维数是 n∗n ,我们可以看到对角线上红色的那个是特征与自己的协方差,因此它是方差。我们看到对角线两侧的协方差是对称的,因此协方差矩阵是一个关于对角线对称的方阵。
下面,我用上面那个学习时间(Time)和分数(Score)的例子来演示一下协方差,假设我们收集的数据如下:
| 时间(T) | 分数(S) |
|---|---|
| 9 | 39 |
| 15 | 56 |
| 25 | 93 |
| 14 | 61 |
| 10 | 50 |
| 18 | 75 |
| 0 | 32 |
| 16 | 85 |
| 5 | 42 |
| 19 | 70 |
| 16 | 66 |
| 20 | 80 |
求协方差的python代码如下:
import numpy as np
T=np.array([9,15,25,14,10,18,0,16,5,19,16,20])
S=np.array([39,56,93,61,50,75,32,85,42,70,66,80])
T=T[:,np.newaxis]
S=S[:,np.newaxis]
X=np.hstack((T,S))
np.cov(X.T)
# 协方差输出如下
array([[ 47.71969697, 122.9469697 ],
[ 122.9469697 , 370.08333333]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
从上面的输出我们看到, cov(T,S)=cov(S,T)=122.9469697 ,这是正数,因此说明你的学习时间越长,你的分数越高。
特征向量(Eigenvectors)与特征值(Eigenvalues)
特征向量是非零向量,当线性变换应用到特征向量时并不会改变它的方向。换句话说:如果 v 是一个非零向量,要想 v 是线性变换 T 的特征向量,则 T(v) 是一个标量值乖上 v ,它可以被写成如下形式:
如果线性变换 T 被表示成作为一个方阵 A 的变换,那么上面的等式可以写成如下形式:
举个例子:假设上面的方阵 A 为 (2231) ,那么,我可以写出如下等式:
上面的 (32) 为特征向量,4为特征值。
特征向量有下面几个属性:
1、只有方阵才能求出特征向量,但是,并不是每个方阵都有特征向量。假设我有一个n * n的矩阵,那么就有n个特征向量。
2、如果我在乖上特征向量之前缩放它,我依然会得到同一个特征值。比如:
3、一个矩阵中的所有特征向量都是相互垂直的,无论你的数据集中有多少特征。
4、向量的大小不能影响它是不是一个特征向量,但是,它的方向可以。因此,在我们找到特征向量以后要把它们单位化,使所有的特征向量都有相同的长度。
你可能会想,我应该怎么找到这些神秘的特征向量呢?不幸的是,我们只能找到相对较小的方阵的特征向量,如果对于大的方阵,我们只能用复杂的迭代方法来求出特征向量。我建议你去Google一些优秀的线性代数库来做这个事情。
主成分分析(Principal Components Analysis)
PCA是一种无监督线性转换技术,它主要应用在降维(dimensionality reduction)上。PCA基于数据特征之间的相关性帮我们找到数据中的模式。简而言之,PCA的目的是在高维数据中找到最大方差的方向,接着映射它到比最初维数小或相等的新的子空间。
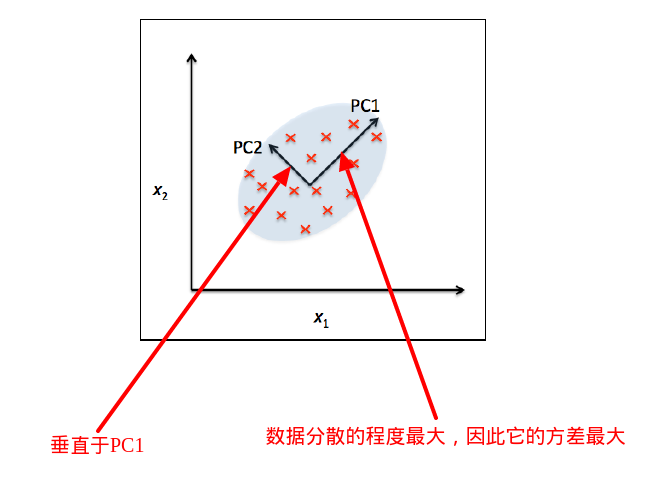
下面我介绍关于主成分分析技术的实现过程。并用葡萄酒(Wine)数据集实例,它的数据集描述可以在下面的链接中发现。
https://archive.ics.uci.edu/ml/datasets/Wine
数据标准化
PCA对数据缩放是相当敏感的,因此,在我们实现PCA的时候,如果数据特征在不同的范围上,我们首先要对数据集标准化。现在,我要用scikit-learn对数据进行标准化,代码如下:
import pandas as pd
df_wine = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data', header=None) # 加载葡萄酒数据集
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import StandardScaler
X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values # 把数据与标签拆分开来
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3, random_state=0) # 把整个数据集的70%分为训练集,30%为测试集
# 下面3行代码把数据集标准化为单位方差和0均值
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.fit_transform(X_test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
计算协方差矩阵
如果你看了上面数据集的描述,每个样本有13个属性(特征),因此协方差矩阵的维数应该是13 * 13
import numpy as np
cov_mat = np.cov(X_train_std.T)
cov_mat.shape # 输出为(13, 13)
- 1
- 2
- 3
- 1
- 2
- 3
计算协方差矩阵的特征向量和特征值
因为协方差矩阵是方阵,所以我们可以计算它的特征向量和特征值。
import numpy as np
eigen_vals, eigen_vecs = np.linalg.eig(cov_mat)
eigen_vecs.shape # 输出为(13, 13)
# 下面的输出为eigen_vals
array([ 4.8923083 , 2.46635032, 1.42809973, 1.01233462, 0.84906459,
0.60181514, 0.52251546, 0.08414846, 0.33051429, 0.29595018,
0.16831254, 0.21432212, 0.2399553 ])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
我们上面求得的特征向量都是单位特征向量,它们的长度为1,这对PCA很重要,幸运的是,一些流行的数学包都会给你这样的单位特征向量。下面这幅图的特征是2维的,因此它只有2个特征向量,但是我们的数据集的特征是13维的,我很难可视化出来。但是,你可以把我们求出的13维特征向量想像成彼此正交的坐标轴,每个方向都指向方差最大的方向。
由于我们的特征向量是单位向量,我们只知道它指向的方向,但是,我想知道哪个方向上保留的方差最多,这其实并不难,我们求出的特征值的意义就是特征向量的大小,因此我们只要找出最大特征值所对应的特征向量就可以知道哪个方向保留的方差最多。
下面,我要画出方差解释率(variance explained ratios),也就是每个特征值占所有特征值和的比例。
tot = sum(eigen_vals) # 求出特征值的和
var_exp = [(i / tot) for i in sorted(eigen_vals, reverse=True)] # 求出每个特征值占的比例(降序)
cum_var_exp = np.cumsum(var_exp) # 返回var_exp的累积和
import matplotlib.pyplot as plt
# 下面的代码都是绘图的,涉及的参数建议去查看官方文档
plt.bar(range(len(eigen_vals)), var_exp, width=1.0, bottom=0.0, alpha=0.5, label='individual explained variance')
plt.step(range(len(eigen_vals)), cum_var_exp, where='post', label='cumulative explained variance')
plt.ylabel('Explained variance ratio')
plt.xlabel('Principal components')
plt.legend(loc='best')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
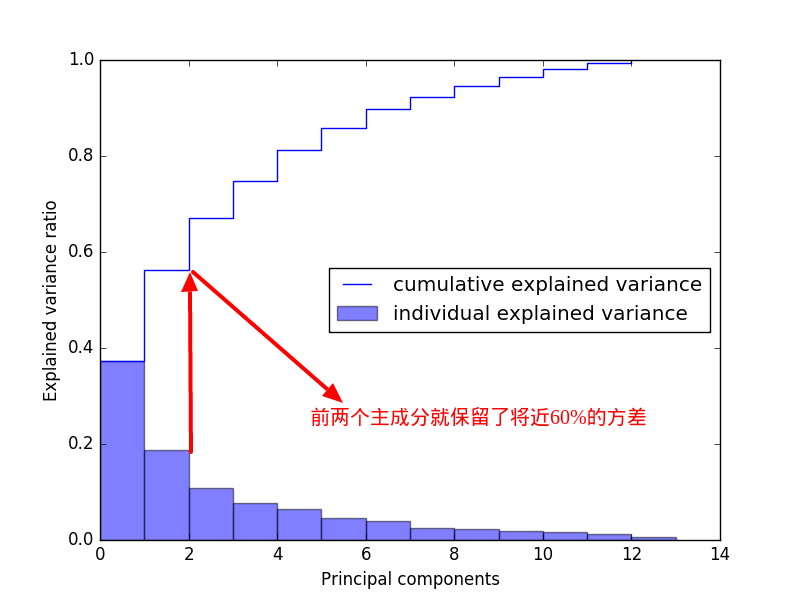
从上图你也看到了,其实2个特征就已经保留了数据集的大部分信息,可见在实际应用中,大部分的特征都是冗余的。注意,有一点你始终要记在心里,PCA是无监督学习算法,这就意味着它会忽视类标签信息。
特征变换(Feature transformation)
我们已经成功地把协方差方阵转换成了特征向量和特征值,现在让我们把葡萄酒数据集映射到新的主成分坐标轴吧。为了数据的可视化,我只想把我的数据集映射到2个保留最多方差的主成分。因此,我们要从大到小排序特征值,选出前2个特征值对应的特征向量,并用这2个特征向量构建映射矩阵,用这个映射矩阵把数据集转换到2维空间。
eigen_pairs =[(np.abs(eigen_vals[i]),eigen_vecs[:,i]) for i in range(len(eigen_vals))] # 把特征值和对应的特征向量组成对
eigen_pairs.sort(reverse=True) # 用特征值排序
- 1
- 2
- 1
- 2
下面,我只选出前2对来构建我们的映射矩阵,但是在实际应用中,你应该权衡你的计算效率和分类器之间的性能来选择恰当的主成分数量。
first = eigen_pairs[0][1]
second = eigen_pairs[1][1]
first = first[:,np.newaxis]
second = second[:,np.newaxis]
W = np.hstack((first,second))
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
现在,我们已经构建出了13×2维的映射矩阵 W ,我们可以用这个映射矩阵来转换我们的训练集X_train_std(124×13维)到只包含2个特征的子空间,用 X_train_pca=X_train_stdW ,现在这个2维的新空间我可以可视化了,代码如下:
X_train_pca = X_train_std.dot(w) # 转换训练集
colors = ['r', 'b', 'g']
markers = ['s', 'x', 'o']
for l, c, m in zip(np.unique(y_train), colors, markers):
plt.scatter(X_train_pca[y_train==l, 0], X_train_pca[y_train==l, 1], c=c, label=l, marker=m) # 散点图
plt.xlabel('PC 1')
plt.ylabel('PC 2')
plt.legend(loc='lower left')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
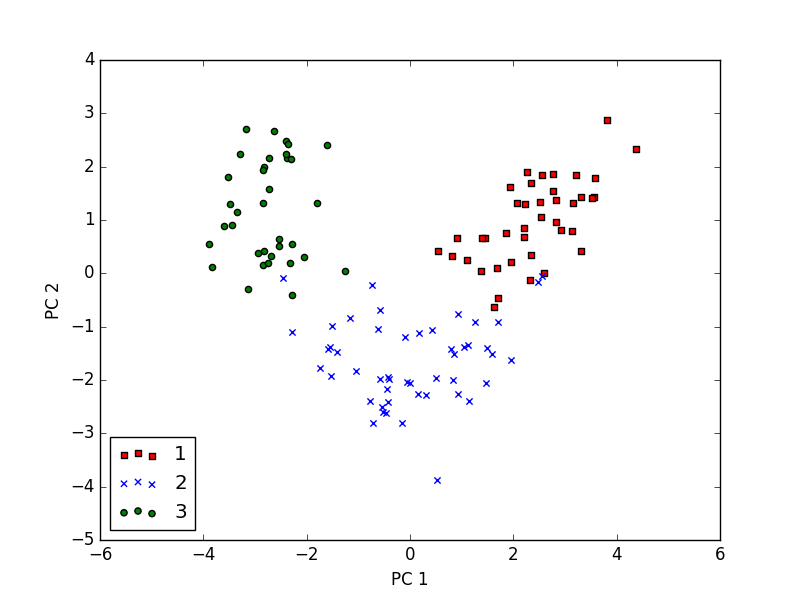
从上图我们可以看到在PC 1轴上数据是更加分散的,因此它的方差更大。现在,我们也可以看到数据是线性可分的。
scikit-learn实现PCA
为了更好地理解PCA,我们自己实现了这个算法。但是scikit-learn已经帮我们更好地实现了。代码如下:
from sklearn.linear_model import LogisticRegression
from sklearn.decomposition import PCA
pca = PCA(n_components=2) # 保留2个主成分
lr = LogisticRegression() # 创建逻辑回归对象
X_train_pca = pca.fit_transform(X_train_std) # 把原始训练集映射到主成分组成的子空间中
X_test_pca = pca.transform(X_test_std) # 把原始测试集映射到主成分组成的子空间中
lr.fit(X_train_pca, y_train) # 用逻辑回归拟合数据
plot_decision_regions(X_train_pca, y_train, classifier=lr)
lr.score(X_test_pca, y_test) # 0.98 在测试集上的平均正确率为0.98
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend(loc='lower left')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
关于逻辑回归的具体细节参考:http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
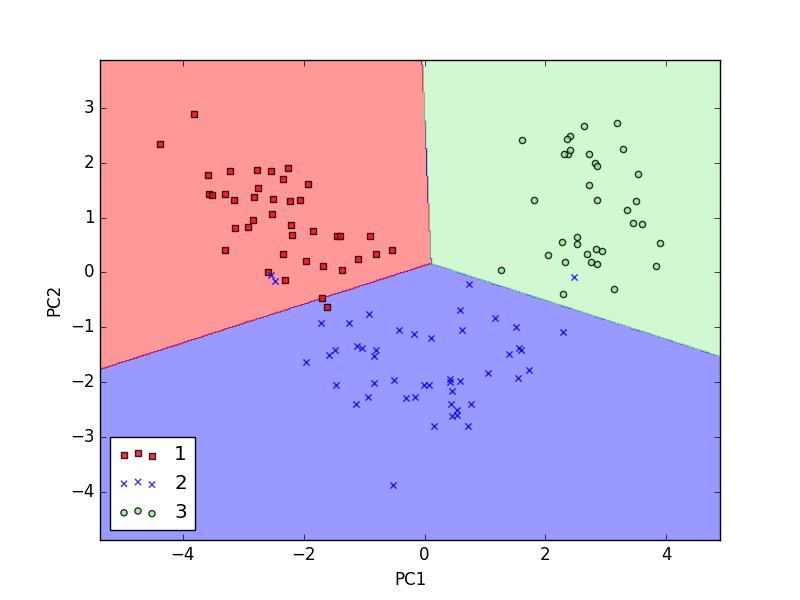
从上图我们可以看出,用PCA压缩数据以后,我们依然很好对样本进行分类。
我们也可以查看PCA的方差解释率(variance explained ratios),代码如下:
pca = PCA(n_components=None) # 保留所有的主成分
X_train_pca = pca.fit_transform(X_train_std)
pca.explained_variance_ratio_
# 输出如下
array([ 0.37329648, 0.18818926, 0.10896791, 0.07724389, 0.06478595,
0.04592014, 0.03986936, 0.02521914, 0.02258181, 0.01830924,
0.01635336, 0.01284271, 0.00642076])














 2030
2030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









