







1、感知机
学习资料:《统计学习方法》,cs229讲义,其他。
感知机是用来进行二类分类的分类模型,而感知机的学习过程就是求出将训练数据进行线性划分的分离超平面过程。下面会给出感知机模型,接着进行学习,最后证明算法的收敛性。
1.1、感知机模型
看下面的图,有两类点,记为-1和+1(负累和正类),我们需要求一条直线(超平面,用 w x + b = 0 wx+b=0 wx+b=0来表示)来将它们进行划分。我们最后需要得到参数 w w w和 b b b,参数求解的过程就是感知机学习过程了。
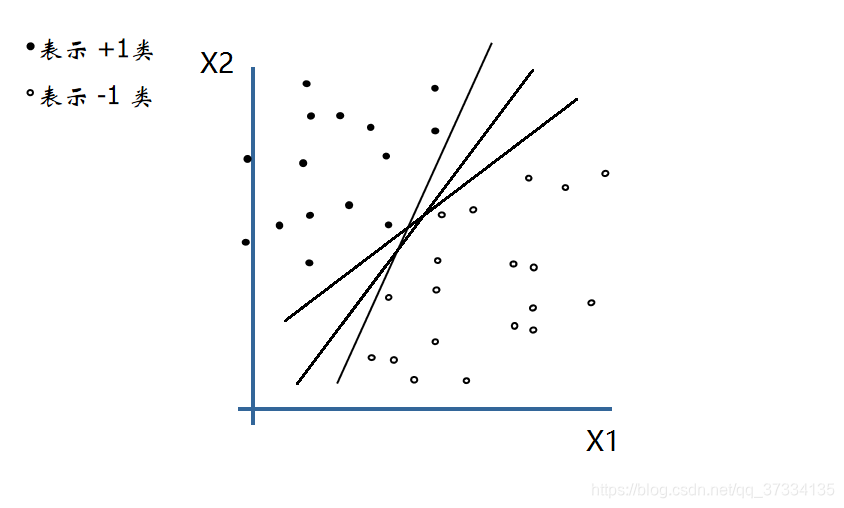
假设输入空间 X X X是m维向量,输出空间 Y = { + 1 , − 1 } Y=\{+1,-1\} Y={+1,−1}。输入 x = { x 1 , x 2 , . . . , x m } x=\{x^1,x^2,...,x^m\} x={x1,x2,...,xm}表示实例的特征向量;输出 y y y表示实例的类别。那么感知机模型表示如下:
f ( x ) = s i g n ( w x + b ) f(x)=sign(wx+b) f(x)=sign(wx+b)
其中 w w w称为权值, b b b称为偏置, w x = w 1 x 1 + w 2 x 2 + . . . + w m x m wx=w^1x^1+w^2x^2+...+w^mx^m wx=w1x1+w2x2+...+wmxm,当 w x + b > 0 wx+b>0 wx+b>0时候 s i g n ( w x + b ) = + 1 sign(wx+b)=+1 sign(wx+b)=+1,当 w x + b < 0 wx+b<0 wx+b<0 时候 s i g n ( w x + b ) = − 1 sign(wx+b)=-1 sign(wx+b)=−1。
现在要做的是求出这样的超平面 w x + b = 0 wx+b=0 wx+b=0将空间分成正类和负类,接下来进行模型的学习,求解参数 w w w和 b b b。
1.2、感知机的学习算法
先给出数据集线性可分的定义:
给定一个数据集
T
=
{
(
x
1
,
y
1
)
,
.
.
.
,
(
x
n
,
y
n
)
}
T=\{(x_1,y_1),...,(x_n,y_n)\}
T={(x1,y1),...,(xn,yn)},其中
x
i
x_i
xi 是m维向量(m个特征),
y
i
=
{
+
1
,
−
1
}
y_i=\{+1,-1\}
yi={+1,−1}表示类别,如果存在某个超平面
S
S
S
w
x
+
b
=
0
wx+b=0
wx+b=0
能够将训练集的正实例点和负实例点正确的划分到超平面两侧,即:对于
y
=
+
1
y=+1
y=+1的实例有
w
x
i
+
b
>
0
wx_i+b>0
wxi+b>0,对于
y
=
−
1
y=-1
y=−1的实例有
w
x
i
+
b
<
0
wx_i+b<0
wxi+b<0,写到一起也就是
y
i
(
w
x
i
+
b
)
>
0
y_i(wx_i+b)>0
yi(wxi+b)>0那么就说数据集
T
T
T是线性可分的。
如果给定数据集是线性可分的,那么我们就可以去求这样的超平面 w x + b = 0 wx+b=0 wx+b=0,参数 w , b w,b w,b求解过程也就成了感知机学习过程。我们定义损失函数,通过最小化损失函数值来进行参数的求解。
定义一个点 x i x_i xi到超平面 w x + b = 0 wx+b=0 wx+b=0的距离:
1 ∣ ∣ w ∣ ∣ ∣ w x i + b ∣ \frac{1}{||w||}|wx_i + b| ∣∣w∣∣1∣wxi+b∣
其中 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣是向量 w w w的 L 2 L_2 L2范数,举个例子来说,假设超平面表示为 x 1 + 2 x 2 + 3 = 0 x_1+2x_2+3=0 x1+2x2+3=0那么点(1,-2)刚好在上面,而 ( 1 , 1 ) (1,1) (1,1)带入 x 1 + x 2 + 3 x_1+x_2+3 x1+x2+3中结果是6,而权重和偏置变成了原来两倍那么 ( 1 , 1 ) (1,1) (1,1)的距离就成了原来的2倍,所以我们使用了距离除以 L 2 L_2 L2范数进行距离的固定化,这样权重和偏置就算成倍增加那么距离也不会变了。这里叫做集合间隔,而不进行标准化的叫做函数间隔。
对于误分类的数据 ( x i , y i ) (x_i,y_i) (xi,yi),满足 y i ( w x i + b ) < 0 = > − y i ( w x i + b ) > 0 y_i(wx_i+b)<0 => -y_i(wx_i+b)>0 yi(wxi+b)<0=>−yi(wxi+b)>0 ,所以该误分类的点到超平面的距离为:
− 1 ∣ ∣ w ∣ ∣ y i ( w x i + b ) -\frac{1}{||w||}y_i(wx_i + b) −∣∣w∣∣1yi(wxi+b)
1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣∣w∣∣1可以直接去掉,只要响应的变化内部系数即可,所以所有误分类的点 x i ∈ M x_i \in M xi∈M到超平面的距离之和为:
J ( w , b ) = − ∑ x i ∈ M y i ( w x i + b ) J(w,b)=- \sum\limits_{x_i \in M}^{} y_i(wx_i + b) J(w,b)=−xi∈M∑yi(wxi+b)
这就是我们的损失函数(也称做感知机学习的经验风险函数),我们的学习要求使得这个损失函数值最小,显然损失函数的值是大于等于0,只有当超平面将数据集正确划分了,那么就是没有误分类点此时损失函数值就是0。
超平面是连续可导的,所以损失函数也是连续可导,这里要求最小值,所以可以使用梯度下降(比如随机梯度下降)
w
j
:
=
w
j
−
α
∂
J
(
w
,
b
)
∂
w
j
w_j := w_j - \alpha \frac{\partial J(w,b)}{\partial w_j}
wj:=wj−α∂wj∂J(w,b) for every j(表示第j个特征)
b
:
=
b
−
α
∂
J
(
w
,
b
)
∂
b
b:=b - \alpha \frac{\partial J(w,b)}{\partial b}
b:=b−α∂b∂J(w,b)
将损失函数带入求导可得:
w
j
:
=
w
j
+
α
∑
x
i
∈
M
y
i
x
i
j
w_j := w_j + \alpha\sum\limits_{x_i \in M}^{} y_i x_i^j
wj:=wj+αxi∈M∑yixij
b
:
=
b
+
α
∑
x
i
∈
M
y
i
b := b + \alpha\sum\limits_{x_i \in M}^{} y_i
b:=b+αxi∈M∑yi
由于是使用随机梯度下降,那么伪代码我们写成下面的形式
f o r i = i 1 − > i M { w j : = w j + α y i x i j ( 针 对 没 个 j 同 时 进 行 ) , b : = b + α y i } for i = i_1 -> i_M \{w_j:= w_j + \alpha y_i x_i^j(针对没个j同时进行),b:=b+\alpha y_i\} fori=i1−>iM{wj:=wj+αyixij(针对没个j同时进行),b:=b+αyi}
具体的算法如下:
- 选取初始值 w 0 , b 0 w_0,b_0 w0,b0
- 训练集中选取数据 ( x i , y i ) (x_i,y_i) (xi,yi)
- 找误分类点,即 y i ( w x i + b ) < = 0 y_i(wx_i+b)<=0 yi(wxi+b)<=0,那么进行上面的 w w w和 b b b的更新操作,转到步骤2。直到没有误分类点为止。
1.3、算法的收敛性
对于上面的算法会不会存在,一直找不到这样的超平面导致会一直循环下去呢?答案是不会,也就是说经过有限次迭代可以得到一个将训练集正确划分的超平面,也就是说该算法具有收敛性。
为方便起见,进行如下的转换:
w
‾
=
(
w
T
,
b
)
\overline w = (w^T,b)
w=(wT,b),
x
‾
=
(
x
T
,
1
)
T
\overline x = (x^T,1)^T
x=(xT,1)T,为了方便起见后面将
T
T
T给去掉了。
那么
w
⋅
x
+
b
=
0
w\cdot x+b=0
w⋅x+b=0就可以表示成
w
‾
⋅
x
‾
=
0
\overline w\cdot \overline x=0
w⋅x=0
下面来进行证明收敛性
给定训练集 { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } \{(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\} {(x1,y1),(x2,y2),...,(xn,yn)}是线性可分的。
(1)、证明存在满足条件 ∣ ∣ w ‾ e ∣ ∣ = 1 ||\overline w_{e}||=1 ∣∣we∣∣=1的超平面 w ‾ e ⋅ x ‾ = w e ⋅ x + b e = 0 \overline w_{e}\cdot \overline x=w_e\cdot x +b_e=0 we⋅x=we⋅x+be=0,将训练集正确分开,且存在 γ > 0 \gamma>0 γ>0,对所有的 i = 1 , 2 , … , n i=1,2,\dots,n i=1,2,…,n都有
y i ( w ‾ e ⋅ x ‾ i ) = y i ( w e ⋅ x i + b e ) > = γ y_i(\overline w_{e}\cdot \overline x_i)=y_i(w_e\cdot x_i +b_e)>=\gamma yi(we⋅xi)=yi(we⋅xi+be)>=γ
证明: 由于训练集线性可分,自然就存在超平面 S S S将其正确划分,对于该超平面我们只需要规范一下,或者说同比例增加或者减少参数大小,是的满足 w ‾ = 1 \overline w=1 w=1即可,那么该平面就是我们想要的,记做 w ‾ e ⋅ x ‾ = w e ⋅ x + b e = 0 \overline w_{e}\cdot \overline x=w_e\cdot x +b_e=0 we⋅x=we⋅x+be=0。此时必然满足
y i ( w ‾ e ⋅ x ‾ i ) = y i ( w e ⋅ x i + b e ) > 0 y_i(\overline w_{e}\cdot \overline x_i)=y_i(w_e\cdot x_i +b_e)>0 yi(we⋅xi)=yi(we⋅xi+be)>0,我们将 γ \gamma γ 记做 min y i ( w e ⋅ x i + b e ) \min y_i(w_e\cdot x_i +b_e) minyi(we⋅xi+be),所以就得到对任意 i = 1 , 2 , … , n i=1,2,\dots,n i=1,2,…,n, 都有 y i ( w ‾ e ⋅ x ‾ i ) = y i ( w e ⋅ x i + b e ) > = γ y_i(\overline w_{e}\cdot \overline x_i)=y_i(w_e\cdot x_i +b_e)>=\gamma yi(we⋅xi)=yi(we⋅xi+be)>=γ
(2)、令 R = max i ∈ [ 1 , n ] ∣ ∣ x ‾ i ∣ ∣ R=\max\limits_{i \in [1,n]} ||\overline x_i|| R=i∈[1,n]max∣∣xi∣∣ ,则前面提到的感知机算法的误分类次数 k k k(或者说参数的迭代的轮次)满足如下不等式
k < = ( R γ ) 2 k <= (\frac{R}{\gamma})^2 k<=(γR)2
补充:如果满足了(2)那么就说明了算法的收敛性,也就是一定的迭代次数后能得到满足要求的超平面。下面开始证明
假设初始参数 w ‾ 0 = 0 \overline w_0=0 w0=0,如果实例被误分类那么需要继续更新参数。对于第 k − 1 k-1 k−1次参数 w ‾ k − 1 \overline w_{k-1} wk−1,对应的误分类实例为 x ‾ i \overline x_i xi,由于是误分类很自然的有 y i ( w ‾ k − 1 ⋅ x ‾ i ) = y i ( w k − 1 ⋅ x i + b k − 1 ) < 0 y_i(\overline w_{k-1} \cdot \overline x_i)=y_i(w_{k-1}\cdot x_i + b_{k-1})<0 yi(wk−1⋅xi)=yi(wk−1⋅xi+bk−1)<0
根据前面写的随机梯度下降得到的公式如下(将所有的特征 j j j全部写到了一起,所以没有了 w j w_j wj):
w
k
=
w
k
−
1
+
α
y
i
x
i
w_k=w_{k-1} + \alpha y_ix_i
wk=wk−1+αyixi
b
k
=
b
k
−
1
+
α
y
i
b_k=b_{k-1} + \alpha y_i
bk=bk−1+αyi
k − 1 k-1 k−1表示上一轮, k k k表示当前,两个写到一起就是
w ‾ k = w ‾ k − 1 + α y i x ‾ i \overline w_k=\overline w_{k-1}+\alpha y_i\overline x_i wk=wk−1+αyixi
(2.1)、证明 w ‾ e ⋅ w ‾ k > = k α γ \overline w_e\cdot \overline w_k>=k\alpha \gamma we⋅wk>=kαγ
证明: w ‾ e ⋅ w ‾ k = w ‾ e ( w ‾ k − 1 + α y i x i ) = w ‾ e ⋅ w ‾ k − 1 + α y i w ‾ e x i > = w ‾ e ⋅ w ‾ k − 1 + α γ > = w ‾ e ⋅ w ‾ k − 2 + 2 α γ > = . . . > = w ‾ e ⋅ w ‾ 0 + k α γ = k α γ \overline w_e\cdot \overline w_k=\overline w_e(\overline w_{k-1} + \alpha y_ix_i) =\overline w_e\cdot\overline w_{k-1} + \alpha y_i \overline w_e x_i>=\overline w_e\cdot\overline w_{k-1}+ \alpha \gamma>=\overline w_e\cdot\overline w_{k-2}+2\alpha \gamma>=...>=\overline w_e\cdot\overline w_{0}+k\alpha \gamma=k\alpha \gamma we⋅wk=we(wk−1+αyixi)=we⋅wk−1+αyiwexi>=we⋅wk−1+αγ>=we⋅wk−2+2αγ>=...>=we⋅w0+kαγ=kαγ
(2.2)、证明 ∣ ∣ w ‾ k ∣ ∣ 2 < = k α 2 R 2 ||\overline w_k||^2<=k\alpha^2R^2 ∣∣wk∣∣2<=kα2R2
证明: ∣ ∣ w ‾ k ∣ ∣ 2 = w ‾ k ⋅ w ‾ k = w ‾ k − 1 ⋅ w ‾ k − 1 + 2 α y i w ‾ k − 1 x ‾ i + α 2 ∣ ∣ x ‾ i ∣ ∣ 2 < = ∣ ∣ w ‾ k − 1 ∣ ∣ 2 + α 2 R 2 < = . . . < = k α 2 R 2 ||\overline w_k||^2=\overline w_k\cdot \overline w_k=\overline w_{k-1}\cdot \overline w_{k-1}+2\alpha y_i \overline w_{k-1}\overline x_i + \alpha^2||\overline x_i||^2<=||\overline w_{k-1}||^2 + \alpha^2R^2<=...<=k\alpha^2R^2 ∣∣wk∣∣2=wk⋅wk=wk−1⋅wk−1+2αyiwk−1xi+α2∣∣xi∣∣2<=∣∣wk−1∣∣2+α2R2<=...<=kα2R2
根据(2.1)和(2.2)得到
k
α
γ
<
=
w
‾
e
⋅
w
‾
k
<
=
∣
∣
w
‾
e
∣
∣
⋅
∣
∣
w
‾
k
∣
∣
=
∣
∣
w
‾
k
∣
∣
<
=
k
α
R
k\alpha \gamma<=\overline w_e\cdot \overline w_k<=||\overline w_e||\cdot ||\overline w_k||=||\overline w_k||<=\sqrt{k}\alpha R
kαγ<=we⋅wk<=∣∣we∣∣⋅∣∣wk∣∣=∣∣wk∣∣<=kαR
=
>
k
2
α
2
γ
2
<
=
k
α
2
R
2
=> k^2\alpha^2 \gamma^2<=k\alpha^2 R^2
=>k2α2γ2<=kα2R2,最后得到
k
<
=
(
R
γ
)
2
k <= (\frac{R}{\gamma})^2
k<=(γR)2














 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









