







Adaboost算法
1.概念
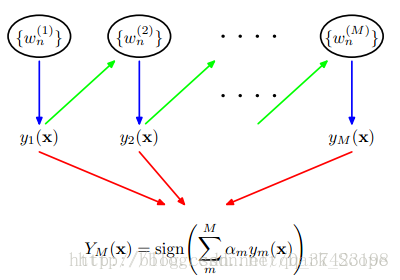
这就是Adaboost的结构,最后的分类器 YM Y M 是由数个弱分类器(weak classifier)组合而成的,相当于最后m个弱分类器来投票决定分类,而且每个弱分类器的“话语权”α不一样。
1.初始化所有训练样例的权重为 w1i=1N w 1 i = 1 N ,其中N是样例数,M个弱分类器
2.for m=1,…,M:
a)训练弱分类器
ym()
y
m
(
)
,使其最小化权重误差函数(weighted error function):
ϵm=∑n=1Nw(m)nI(ym(xn)≠tn)
ϵ
m
=
∑
n
=
1
N
w
n
(
m
)
I
(
y
m
(
x
n
)
≠
t
n
)
b)接下来计算该弱分类器的话语权α:
αm=ln(1−ϵmϵm)
α
m
=
l
n
(
1
−
ϵ
m
ϵ
m
)
c)更新权重:
wm+1,i=wmiZmexp(−αmtiym(xi)),i=1,2,3…,m
w
m
+
1
,
i
=
w
m
i
Z
m
e
x
p
(
−
α
m
t
i
y
m
(
x
i
)
)
,
i
=
1
,
2
,
3
…
,
m
其中 Zm Z m : Zm=∑Ni=1wmiexp(−αmtiym(xi)) Z m = ∑ i = 1 N w m i e x p ( − α m t i y m ( x i ) ) 是规范化因子,使所有w的和为1。
3.得到最后的分类器:
YM(x)=sign(∑m−1Mαmym(x))
Y
M
(
x
)
=
s
i
g
n
(
∑
m
−
1
M
α
m
y
m
(
x
)
)
2.原理:
前一个分类器改变权重w,同时组成最后的分类器,如果一个训练样例 在前一个分类其中被误分,那么它的权重会被加重,相应地,被正确分类的样例的权重会降低,使得下一个分类器 会更在意被误分的样例
直接将前项分步加法模型具体到adaboost上:
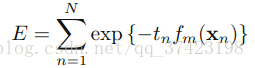
其中 fm f m 是前m个分类器的结合
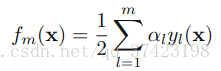
此时我们要最小化E,同时要考虑α和yl,但现在我们假设前m-1个α和y都已经fixed了
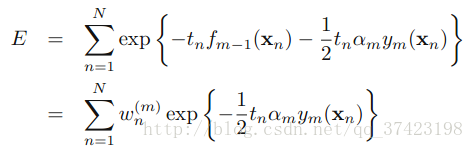
其中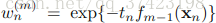 可以被看做一个常量,因为它里面没有
αm
α
m
和
ym
y
m
,接下来
可以被看做一个常量,因为它里面没有
αm
α
m
和
ym
y
m
,接下来
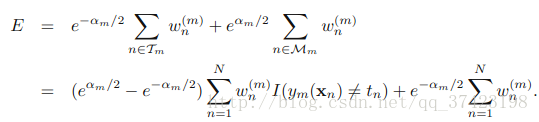
其中Tm表示正分类的集合,Mm表示误分类的集合,这一步其实就是把上面那个式子拆开,然后就是找ym了,就是最小化下式的过程,其实就是我们训练弱分类器
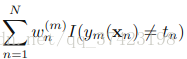
有了ym,α也就可以找了,然后继续就可以找到更新w的公式了(注意这里得到的w公式是没有加规范化因子Z的公式,为了计算方便我们加了个Z进去)
3.sklearn实现
本例是Sklearn网站上的关于决策树桩、决策树、和分别使用AdaBoost—SAMME和AdaBoost—SAMME.R的AdaBoost算法在分类上的错误率。这个例子基于Sklearn.datasets里面的make_Hastie_10_2数据库。取了12000个数据,其他前2000个作为训练集,后面10000个作为了测试集。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import zero_one_lossn_estimators = 500
learning_rate = 1
X,y = datasets.make_hastie_10_2(n_samples=12000,random_state=1)
#使用make_hastie_10_2数据集
X_test,y_test=X[2000:],y[2000:]
X_train,y_train=X[:2000],y[:2000]
dt_stump = DecisionTreeClassifier(max_depth=1,min_samples_leaf=1)
dt_stump.fit(X_train,y_train)
dt_stump_err = 1.0-dt_stump.score(X_test,y_test)#利用测试集去评分
dt = DecisionTreeClassifier(max_depth=9,min_samples_leaf=1)
dt.fit(X_train,y_train)
dt_err = 1.0-dt.score(X_test,y_test)
fig = plt.figure()
ax=fig.add_subplot(111)
ax.plot([1,n_estimators],[dt_stump_err]*2,'k-',label='Decision Stump Error')
ax.plot([1,n_estimators],[dt_err]*2,'k--',label='Decision Tree Error') #画水平直线的方法 套入模型
ada_discrete = AdaBoostClassifier(base_estimator=dt_stump, learning_rate=learning_rate,n_estimators=n_estimators,algorithm='SAMME')
ada_discrete.fit(X_train, y_train)
ada_real = AdaBoostClassifier(base_estimator=dt_stump, learning_rate=learning_rate,n_estimators=n_estimators,algorithm='SAMME.R')
ada_real.fit(X_train, y_train)ada_discrete_err=np.zeros((n_estimators,))
for i,y_pred in enumerate(ada_discrete.staged_predict(X_test)):
ada_discrete_err[i]=zero_one_loss(y_pred,y_test) ######zero_one_loss
ada_discrete_err_train=np.zeros((n_estimators,))
for i,y_pred in enumerate(ada_discrete.staged_predict(X_train)):
ada_discrete_err_train[i]=zero_one_loss(y_pred,y_train)
#zero_one_loss:If normalize is True(default), return the fraction of misclassifications (float),
#else it returns the number of misclassifications (int). The best performance is 0.
ada_real_err=np.zeros((n_estimators,))
for i,y_pred in enumerate(ada_real.staged_predict(X_test)):
ada_real_err[i]=zero_one_loss(y_pred,y_test)
ada_real_err_train=np.zeros((n_estimators,))
for i,y_pred in enumerate(ada_real.staged_predict(X_train)):
ada_discrete_err_train[i]=zero_one_loss(y_pred,y_train)
ax.plot(np.arange(n_estimators)+1,ada_discrete_err,label='Discrete AdaBoost Test Error',color='red')
ax.plot(np.arange(n_estimators)+1,ada_discrete_err_train,label='Discrete AdaBoost Train Error',color='blue')
ax.plot(np.arange(n_estimators)+1,ada_real_err,label='Real AdaBoost Test Error',color='orange')
ax.plot(np.arange(n_estimators)+1,ada_real_err_train,label='Real AdaBoost Train Error',color='green')
ax.set_ylim(0.0,0.5)
ax.set_xlabel('n_estimators')
ax.set_ylabel('error rate')
ax.legend(loc='upper right',fancybox=True).get_frame().set_alpha(0.7)
plt.show()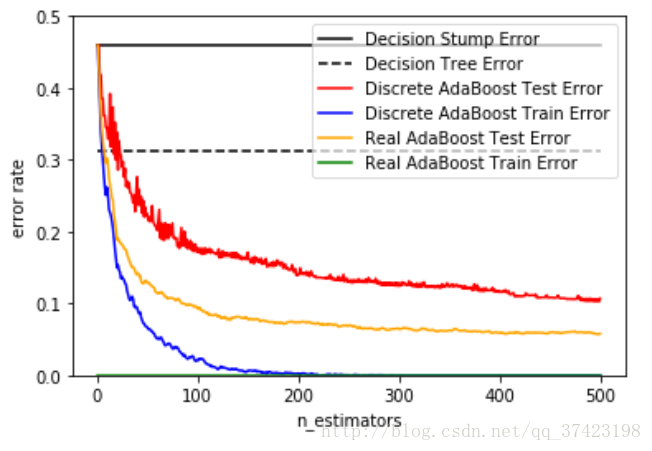
弱分类器(Decision Tree Stump)单独分类的效果很差,错误率将近50%,强分类器(Decision Tree)的效果要明显好于他。















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









