







Adaboost算法
1.概念
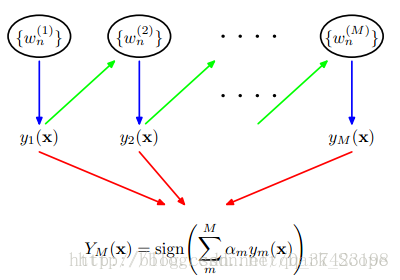
这就是Adaboost的结构,最后的分类器 YM Y M 是由数个弱分类器(weak classifier)组合而成的,相当于最后m个弱分类器来投票决定分类,而且每个弱分类器的“话语权”α不一样。
1.初始化所有训练样例的权重为 w1i=1N w 1 i = 1 N ,其中N是样例数,M个弱分类器
2.for m=1,…,M:
a)训练弱分类器 ym() y m ( ) ,使其最小化权重误差函数(weighted error function):
ϵm=∑n=1Nw(m)nI(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 272
272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









