







三层BP
/**
* input vector.输入向量
*/
private final double[] input;
/**
* hidden layer. 隐含层向量
*/
private final double[] hidden;
/**
* output layer. 输出层
*/
private final double[] output;
/**
* target. 期望值
*/
private final double[] target;
/**
* delta vector of the hidden layer .隐含层delta
*/
private final double[] hidDelta;
/**
* output layer of the output layer. 输出层delta
*/
private final double[] optDelta;
/**
* learning rate. 学习率
*/
private final double eta;
/**
* momentum. 动量系数
*/
private final double momentum;
/**
* weight matrix from input layer to hidden layer.输入层到隐含层权值矩阵
*/
private final double[][] iptHidWeights;
/**
* weight matrix from hidden layer to output layer. 隐含层到输出层权值矩阵
*/
private final double[][] hidOptWeights;
/**
* previous weight update. 上一个输出层到隐含层权值矩阵
*/
private final double[][] iptHidPrevUptWeights;
/**
* previous weight update. 上一个隐含层到输出层权值矩阵
*/
private final double[][] hidOptPrevUptWeights;
public double optErrSum = 0d;
public double hidErrSum = 0d;
private final Random random; 定义构造器,初始参数:
/**
* Constructor. 构造器
* 初始各个参数
*
* @param inputSize 输入层大小
* @param hiddenSize 隐含层大小
* @param outputSize 输出层大小
* @param eta 学习率
* @param momentum 动量系数
* @param epoch
*/
public BP(int inputSize, int hiddenSize, int outputSize, double eta,
double momentum) {
input = new double[inputSize + 1];
hidden = new double[hiddenSize + 1];
output = new double[outputSize + 1];
target = new double[outputSize + 1];
hidDelta = new double[hiddenSize + 1];
optDelta = new double[outputSize + 1];
iptHidWeights = new double[inputSize + 1][hiddenSize + 1];
hidOptWeights = new double[hiddenSize + 1][outputSize + 1];
// 随机初始化权值
random = new Random(201605);
randomizeWeights(iptHidWeights);
randomizeWeights(hidOptWeights);
iptHidPrevUptWeights = new double[inputSize + 1][hiddenSize + 1];
hidOptPrevUptWeights = new double[hiddenSize + 1][outputSize + 1];
this.eta = eta;
this.momentum = momentum;
} 不同构造器
/**
* 构造器,初始化各个参数
* Constructor with default eta = 0.25 and momentum = 0.3.
*
* @param inputSize
* @param hiddenSize
* @param outputSize
* @param epoch
*/
public BP(int inputSize, int hiddenSize, int outputSize) {
this(inputSize, hiddenSize, outputSize, 0.25, 0.9);
} 随机初始化参数
/**
* 随机初始化权重矩阵
* @param matrix
*/
private void randomizeWeights(double[][] matrix) {
for (int i = 0, len = matrix.length; i != len; i++)
for (int j = 0, len2 = matrix[i].length; j != len2; j++) {
double real = random.nextDouble();
matrix[i][j] = random.nextDouble() > 0.5 ? real : -real;
}
} 载入训练样本数据,下面程序将数组后移一位,因为需要增加偏置
/**
* Load the training data.
*/
private void loadInput(double[] inData) {
if (inData.length != input.length - 1) {
throw new IllegalArgumentException("Size Do Not Match.");
}
System.arraycopy(inData, 0, input, 1, inData.length);
} /**
* Load the target data.
* * public static void arraycopy(Object src,
int srcPos,
Object dest,
int destPos,
int length)
从指定源数组中复制一个数组,复制从指定的位置开始,到目标数组的指定位置结束。
从 src 引用的源数组到 dest 引用的目标数组,数组组件的一个子序列被复制下来。
被复制的组件的编号等于 length 参数。
源数组中位置在 srcPos 到 srcPos+length-1 之间的组件被分别复制到目标数组中的 destPos到 destPos+length-1 位置。
* @param inData
* @param arg
*/
private void loadTarget(double[] arg) {
if (arg.length != target.length - 1) {
throw new IllegalArgumentException("Size Do Not Match.");
}
System.arraycopy(arg, 0, target, 1, arg.length);
} 前馈过程
输入层数据经过权值系数转换,再计算累加和
/**
* Forward. 前馈过程,layer = f(W^T.X)
*
* @param layer0
* @param layer1
* @param weight
*/
private void forward(double[] layer0, double[] layer1, double[][] weight) {
// threshold unit.
layer0[0] = 1.0;
for (int j = 1, len = layer1.length; j != len; ++j) {
double sum = 0;
for (int i = 0, len2 = layer0.length; i != len2; ++i)
sum += weight[i][j] * layer0[i];
layer1[j] = sigmoid(sum);
}
} 由于只有三层网络:输入层,隐含层,输出层
有两次向前计算的过程:输入层到隐含层,隐含层到输出层
/**
* Forward.两个前馈:输入层到隐含层,隐含层到输出层,这是一个 三层神经网络
*/
private void forward() {
forward(input, hidden, iptHidWeights);
forward(hidden, output, hidOptWeights);
} 反馈过程
隐含层到输出层delta计算
/**
* Calculate output error. 计算输出层更新delta,下面的optErrSum没有用到
* o * (1d - o) * (target[idx] - o); 这里定义的激活函数是sigmoid函数f(x) = 1/(1+e^(-x)),其导数是f(x)(1-f(x))
*/
private void outputErr() {
double errSum = 0;
for (int idx = 1, len = optDelta.length; idx != len; ++idx) {
double o = output[idx];
optDelta[idx] = derivativeSigmoid(o)* (target[idx] - o);
errSum += Math.abs(optDelta[idx]);
}
optErrSum = errSum;
} 输入层到隐含层delta计算
/**
* Calculate hidden errors. 计算隐含层更新delta,hidErrSum没有用到
*/
private void hiddenErr() {
double errSum = 0;
for (int j = 1, len = hidDelta.length; j != len; ++j) {
double o = hidden[j];
double sum = 0;
for (int k = 1, len2 = optDelta.length; k != len2; ++k)
sum += hidOptWeights[j][k] * optDelta[k];
hidDelta[j] = derivativeSigmoid(o)* sum;
errSum += Math.abs(hidDelta[j]);
}
hidErrSum = errSum;
} 说明下,上面的两个ErrSum没有用到,原作者程序里面就有,同时我增加了可以选取tanh作为激活函数
上面的delta更新按照下面的规则

计算两次delta更新,要先计算隐含层到输出层,再计算输入层到隐含层,这是两次反馈的过程
/**
* Calculate errors of all layers. 输出层 更新delta 隐含层更新delta
*/
private void calculateDelta() {
outputErr();
hiddenErr();
} delta计算出来后,进行更新权值系数
/**
* Adjust the weight matrix. 更新weight矩阵,增加了动量系数
*
* @param delta
* @param layer
* @param weight
* @param prevWeight
*/
private void adjustWeight(double[] delta, double[] layer,
double[][] weight, double[][] prevWeight) {
layer[0] = 1;
for (int i = 1, len = delta.length; i != len; ++i) {
for (int j = 0, len2 = layer.length; j != len2; ++j) {
double newVal = momentum * prevWeight[j][i] + eta * delta[i] * layer[j];
weight[j][i] += newVal;
prevWeight[j][i] = newVal;
}
}
}
/**
* Adjust all weight matrices. 输出层到隐含层,输入层到隐含层,两个权值矩阵进行更新
*/
private void adjustWeight() {
adjustWeight(optDelta, hidden, hidOptWeights, hidOptPrevUptWeights);
adjustWeight(hidDelta, input, iptHidWeights, iptHidPrevUptWeights);
} 两次计算过程,输入层到隐含层,隐含层到输出层
上面的权值更新利用到了动量系数,但是会发现,动量系数的更新和上面的公式不一样,神经网络与机器学习书上公式推导的时候是上面图片中的规则,而最后伪代码写的是上面代码中方式的规则,这里我不明白为什么。
不同的激活函数
/**
* Sigmoid.
*
* @param val
* @return
*/
private double sigmoid(double val) {
return 1d / (1d + Math.exp(-val));
}
private double tanh(double val) {
double a = Math.pow(Math.E, val);
double b = Math.pow(Math.E, -val);
return (a-b)/(a+b);
}
private double derivativeSigmoid(double val){
double f = sigmoid(val);
return f*(1-f);
}
private double derivativeTanh(double val){
double f = tanh(val);
return 1- Math.pow(f,2);
}训练模型
/**
* 训练模型,注意每次需要一个训练集样本数据进行训练
* Entry method. The train data should be a one-dim vector.
*
* @param trainData
* @param target
*/
public void train(double[] trainData, double[] target) {
loadInput(trainData); // 载入数据
loadTarget(target);
forward(); // 前馈
calculateDelta();// 计算delta值
adjustWeight(); // 调整权值矩阵
}测试数据,只需要一个前馈过程就好了
/**
* 测试模型,每次也只能测试一条样本数据
* Test the BPNN.
*
* @param inData
* @return
*/
public double[] test(double[] inData) {
if (inData.length != input.length - 1) {
throw new IllegalArgumentException("Size Do Not Match.");
}
System.arraycopy(inData, 0, input, 1, inData.length);
forward();
return getNetworkOutput();
} 上面用到的返回输出结果
/**
* 返回输出层
* Return the output layer.
*
* @return
*/
private double[] getNetworkOutput() {
int len = output.length;
double[] temp = new double[len - 1];
for (int i = 1; i != len; i++)
temp[i - 1] = output[i];
return temp;
} 上面训练模型很差的画了一个图
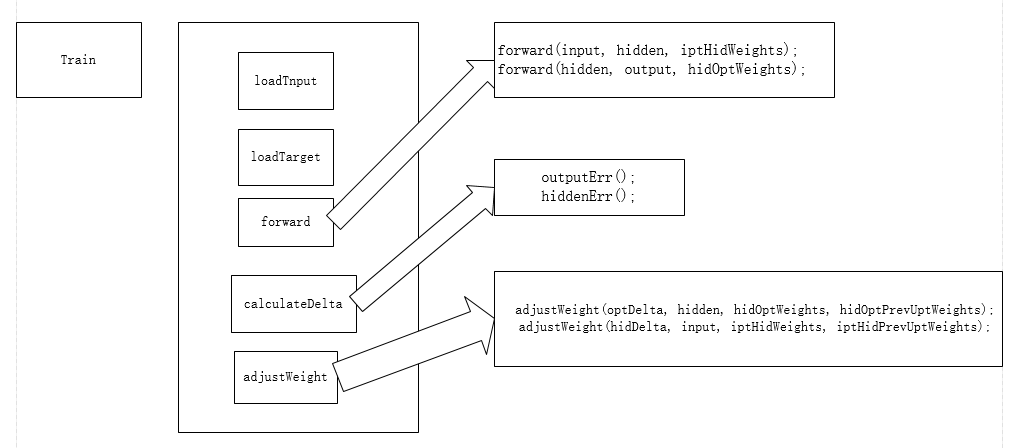
上面链接中给的程序,判断数是正数还是负数。
定义输入层32个神经元,隐含层15个神经元,输出层4个神经元,随机产生1000个数作为训练集,将每个数转换成二进制形式,对每个数训练200次,然后进行测试。
package bp;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
public class Test {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
BP bp = new BP(32, 15, 4);
Random random = new Random();
List<Integer> list = new ArrayList<Integer>();
for (int i = 0; i != 1000; i++) {
int value = random.nextInt();
list.add(value);
}
for (int i = 0; i != 200; i++) {
for (int value : list) {
double[] real = new double[4];
if (value >= 0)
if ((value & 1) == 1)
real[0] = 1;
else
real[1] = 1;
else if ((value & 1) == 1)
real[2] = 1;
else
real[3] = 1;
double[] binary = new double[32];
int index = 31;
do {
binary[index--] = (value & 1);
value >>>= 1;
} while (value != 0);
bp.train(binary, real);
}
}
System.out.println("训练完毕,下面请输入一个任意数字,神经网络将自动判断它是正数还是复数,奇数还是偶数。");
while (true) {
byte[] input = new byte[10];
System.in.read(input);
Integer value = Integer.parseInt(new String(input).trim());
int rawVal = value;
double[] binary = new double[32];
int index = 31;
do {
binary[index--] = (value & 1);
value >>>= 1;
} while (value != 0);
double[] result = bp.test(binary);
double max = -Integer.MIN_VALUE;
int idx = -1;
for (int i = 0; i != result.length; i++) {
if (result[i] > max) {
max = result[i];
idx = i;
}
}
switch (idx) {
case 0:
System.out.format("%d是一个正奇数\n", rawVal);
break;
case 1:
System.out.format("%d是一个正偶数\n", rawVal);
break;
case 2:
System.out.format("%d是一个负奇数\n", rawVal);
break;
case 3:
System.out.format("%d是一个负偶数\n", rawVal);
break;
}
}
}
}上面程序测试效果很好
在神经网络中很常见的学习样例就是异或问题
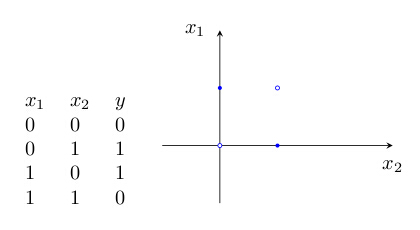
每个样例迭代120次已经很好了
package bp;
public class Test2 {
public static void main(String[] args){
//设置样本数据,对应上面的4个二维坐标数据
double[][] data = new double[][]{{0,0},{0,1},{1,1},{1,0}};
//设置目标数据,对应4个坐标数据的分类
double[][] target = new double[][]{{1,0},{0,1},{0,1},{1,0}};
// BP(int inputSize, int hiddenSize, int outputSize, double eta, double momentum)
BP bp = new BP(2,3,2);
int limit = 120;
while(limit>0){
for(int i=0;i<data.length;i++){
bp.train(data[i],target[i]);
}
limit--;
}
for(int i=0;i<data.length;i++){
double[] predict= bp.test(data[i]);
System.out.println("test:"+i);
for(int j=0;j<predict.length;j++){
System.out.println(predict[j]+" "+target[i][j]);
}
}
}
}
输出
test:0
0.9891777576155748 1.0
0.00885171294335521 0.0
test:1
0.00596229519260654 0.0
0.9923139692468484 1.0
test:2
0.006437172245489061 0.0
0.9916683784692554 1.0
test:3
0.9913501883953556 1.0
0.006853150891322226 0.0














 5599
5599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









