










目录
近期,有人将本人博客,复制下来,直接上传到百度文库等平台。
本文为原创博客,仅供技术学习使用。未经允许,禁止将其复制下来上传到百度文库等平台。如有转载请注明本文博客的地址(链接)
源码请联系邮箱:1563178220@qq.com
抓包介绍
本人已经写了几篇模拟登陆的程序,具体请看http://blog.csdn.net/qy20115549/article/details/52250022
http://blog.csdn.net/qy20115549/article/details/52249232这两篇博客
在写网络爬虫时,有时需要模拟登陆。其实模拟登陆很简单,只需要通过抓包,然后使用httpclient输入用户名,密码等相关参数即可。
但也有一些复杂的,比如说豆瓣,微博等网站,在模拟登陆时,需要输入验证码,这一点比较烦人。如下,是豆瓣登陆时,需要输入验证码。
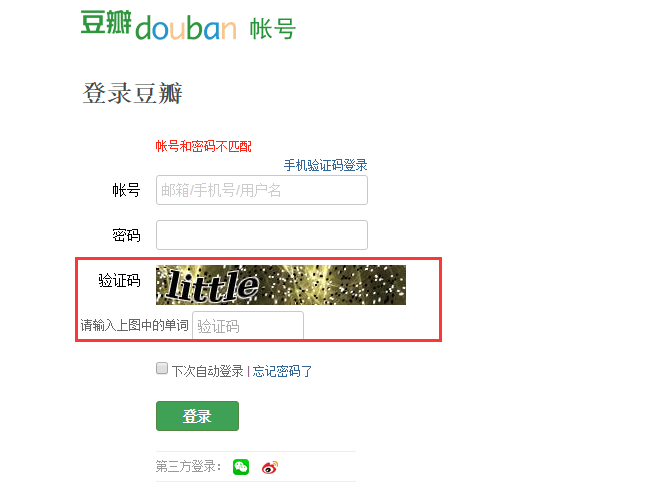
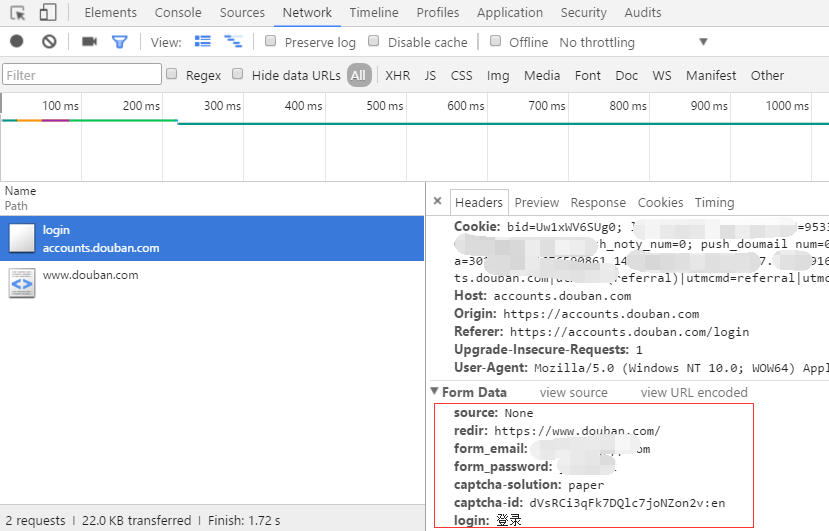
如下图所示,通过抓包,我们可以看出在登陆时,需要输入的参数有哪些。将下面对应的相关参数,写入到程序中,便可以模拟登陆了。
解决验证码的思路
一般解决验证码问题的思路是:将网站验证码对应的图片下载下来,以手工输入的方式,进行登陆。登陆完成后,便可以给一个url或多个url,爬取该url对应的html或json数据对应的信息。注意在爬取多个url的时候,只需要一次登陆即可,这样避免了多次输入验证码图片
验证码地址拼接
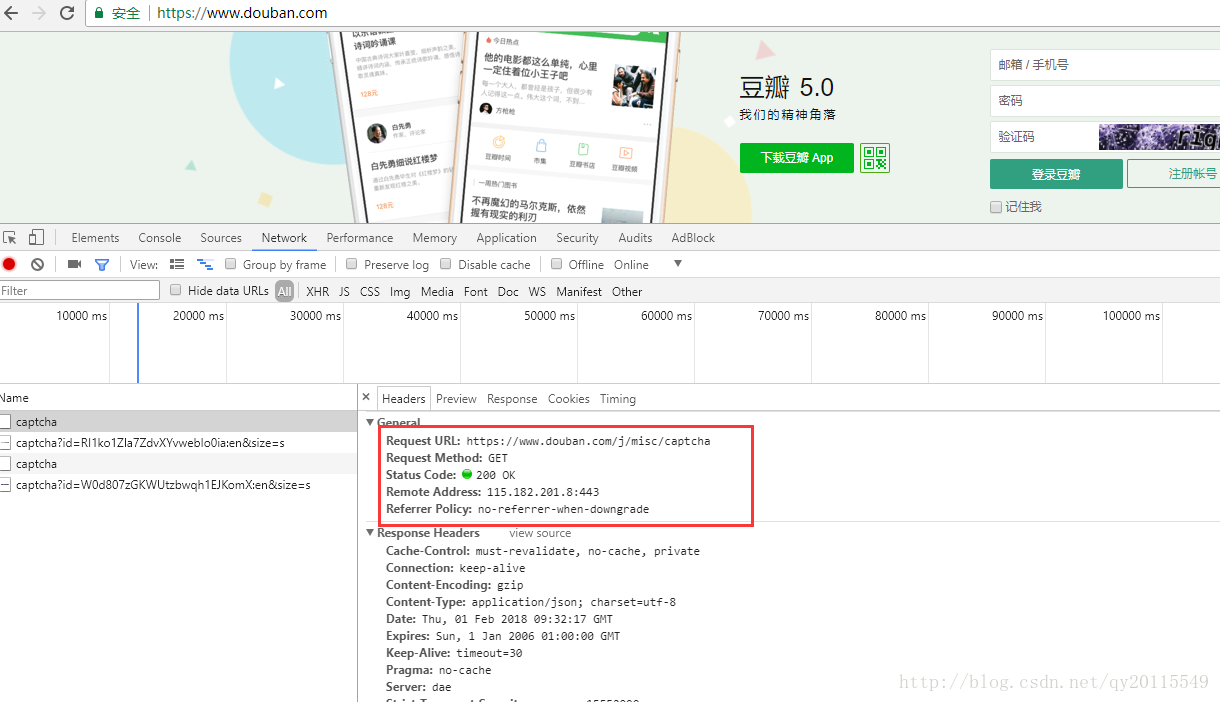
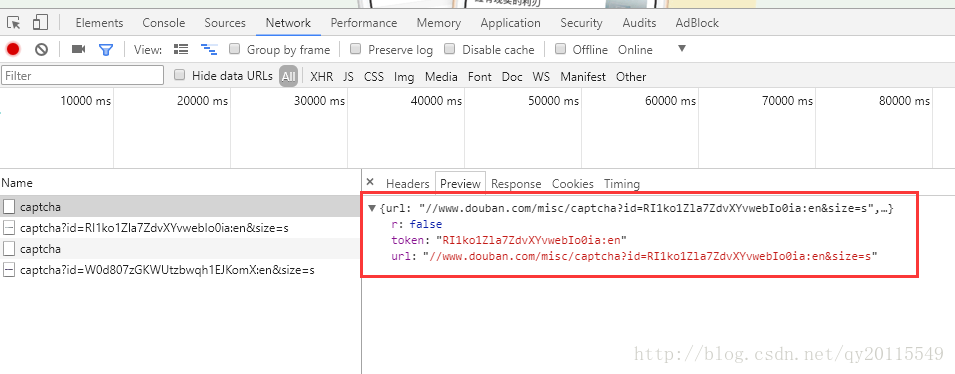
刷新验证码,进行图片请求抓包,我们可以看到,每次刷新,都会有一个图片id产生。如下图所示:
<\center>
其实,我们就是要根据这个地址: https://www.douban.com/j/misc/captcha获取一个json串,进而拼接当前需要模拟登陆的图片地址。获取的json串如下:
{"url":"\/\/www.douban.com\/misc\/captcha?id=lr50o304pwf8KvVdsdL7MKLU:en&size=s","token":"lr50o304pwf8KvVdsdL7MKLU:en","r":false}可以基于此地址获取图片地址:
https://www.douban.com/misc/captcha?id=RI1ko1Zla7ZdvXYvwebIo0ia:en&size=s如下,以豆瓣为例,进行登陆,并获取只有登陆之后,才能看到的信息
package simulate;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.NameValuePair;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import org.json.JSONException;
import org.json.JSONObject;
import util.HTTPUtils;
/**
* @author:合肥工业大学 管理学院 钱洋
* @email:1563178220@qq.com
* @
*/
public class DoubanSimulate {
private static HttpClient httpClient=new DefaultHttpClient();
//主登录入口
public static void loginDouban(){
// String redir="https://www.douban.com/people/144537495/";
String login_src="https://accounts.douban.com/login";
//输入用户名及密码
String form_email="";
String form_password="";
//获取验证码
String captcha_id=getImgID();
String login="登录";
String captcha_solution="";
//输入验证码
System.out.println("请输入验证码:");
BufferedReader buff=new BufferedReader(new InputStreamReader(System.in));
try {
captcha_solution=buff.readLine();
} catch (IOException e) {
e.printStackTrace();
}
//构建参数,即模拟需要输入的参数。这部分通过抓包获得。不会抓包的请看我之前写的一些博客
List<NameValuePair> list=new ArrayList<NameValuePair>();
list.add(new BasicNameValuePair("form_email", form_email));
list.add(new BasicNameValuePair("form_password", form_password));
list.add(new BasicNameValuePair("captcha-solution", captcha_solution));
list.add(new BasicNameValuePair("captcha-id", captcha_id));
list.add(new BasicNameValuePair("login", login));
HttpPost httpPost = new HttpPost(login_src);
try {
//向后台请求数据,登陆网站
httpPost.setEntity(new UrlEncodedFormEntity(list));
HttpResponse response=httpClient.execute(httpPost);
HttpEntity entity=response.getEntity();
String result=EntityUtils.toString(entity,"utf-8");
} catch (ClientProtocolException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 获取验证码图片“token”值
* @return token
*/
private static String getImgID(){
//Json的地址[数据中包含验证码的地址]
String src="https://www.douban.com/j/misc/captcha";
HttpGet httpGet=new HttpGet(src);
String token="";
try {
HttpResponse response=httpClient.execute(httpGet);
HttpEntity entity=response.getEntity();
//将json数据转化为map,对应的是key,value的形式。不理解json数据的,请看我前面的关于json解析的博客
String content=EntityUtils.toString(entity,"utf-8");
Map<String,String> mapList=getResultList(content);
token=mapList.get("token");
//获取验证码的地址
String url="https:"+mapList.get("url");
//下载验证码并存储到本地
downImg(url);
//System.out.println(token);
//System.out.println(url);
//System.out.println(content);
} catch (ClientProtocolException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return token;
}
/**
* 用JSON 把数据格式化,并生成迭代器,放入Map中返回
* @param content 请求验证码时服务器返回的数据
* @return Map集合
*/
public static Map<String,String> getResultList(String content){
Map<String,String> maplist=new HashMap<String,String>();
try {
JSONObject jo=new JSONObject(content.replaceAll(",\\\"r\\\":false", ""));
Iterator it = jo.keys();
String key="";
String value="";
while(it.hasNext()){
key=(String) it.next();
value=jo.getString(key);
maplist.put(key, value);
}
} catch (JSONException e) {
e.printStackTrace();
}
return maplist;
}
/**
* 此方法是下载验证码图片到本地
* @param src 给个验证图片完整的地址
* @throws IOException
*/
private static void downImg(String src) throws IOException{
File fileDir=new File("E:\\钱洋个人\\IdentifyingCode");
if(!fileDir.exists()){
fileDir.mkdirs();
}
//图片下载保存地址
File file=new File("E:\\钱洋个人\\IdentifyingCode\\yzm.png");
if(file.exists()){
file.delete();
}
InputStream input = null;
FileOutputStream out= null;
HttpGet httpGet=new HttpGet(src);
try {
HttpResponse response=httpClient.execute(httpGet);
HttpEntity entity = response.getEntity();
input = entity.getContent();
int i=-1;
byte[] byt=new byte[1024];
out=new FileOutputStream(file);
while((i=input.read(byt))!=-1){
out.write(byt);
}
System.out.println("图片下载成功!");
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
out.close();
}
//登陆后,便可以输入一个或者多个url,进行请求
public static String gethtml(String redirectLocation) {
HttpGet httpget = new HttpGet(redirectLocation);
// Create a response handler
ResponseHandler<String> responseHandler = new BasicResponseHandler();
String responseBody = "";
try {
responseBody = httpClient.execute(httpget, responseHandler);
} catch (Exception e) {
e.printStackTrace();
responseBody = null;
} finally {
httpget.abort();
// httpClient.getConnectionManager().shutdown();
}
return responseBody;
}
//一个实例,只请求了一个url
public static void main(String[] args) throws ClientProtocolException, IOException {
loginDouban();
String redir="https://www.douban.com/people/conanemily/contacts";
// System.out.println(gethtml(redir));
String cc=gethtml(redir);
System.out.println(cc);
}
}爬虫实战
爬虫架构
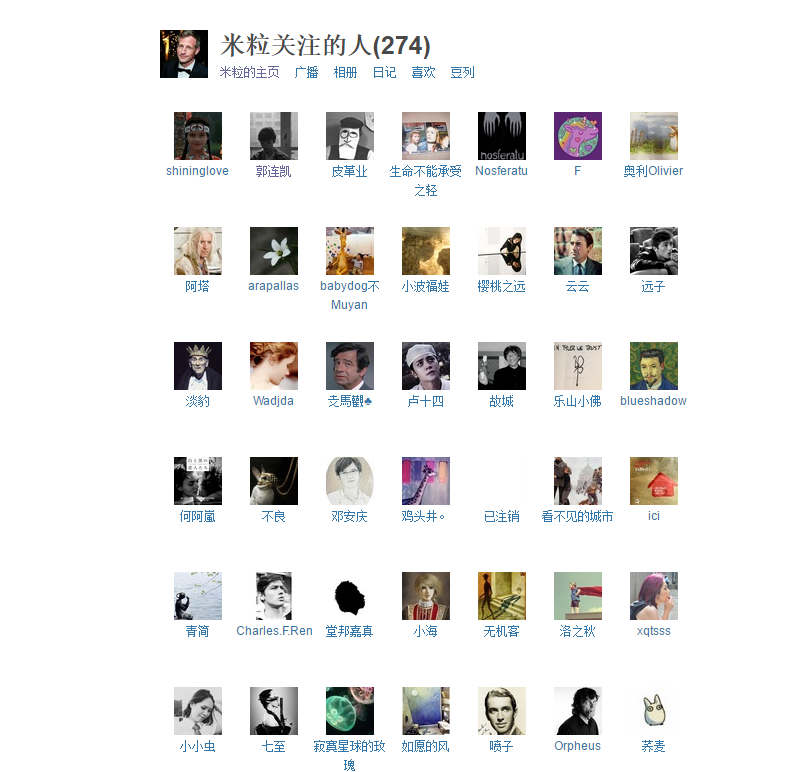
关于为什么使用此架构,可以去看我前面写的网络爬虫框架。此程序主要是用来爬取类似下面这一个网址的信息。
https://www.douban.com/people/conanemily/contacts。包含的信息有:用户自身的id,用户对应好友的id。将这两个字段写入model
model
package model;
/**
* @author:合肥工业大学 管理学院 钱洋
* @email:1563178220@qq.com
* @
*/
public class DouBanUserUrl {
private String user_id;
private String user_contactsid;
public String getUser_id() {
return user_id;
}
public void setUser_id(String user_id) {
this.user_id = user_id;
}
public String getUser_contactsid() {
return user_contactsid;
}
public void setUser_contactsid(String user_contactsid) {
this.user_contactsid = user_contactsid;
}
}
main
这里是main方法,其实,我注释已经写的非常详细了。大家可以直接看程序。
main方法里调用了上面的模拟登陆的程序,及给定url,模拟登陆后获取html的程序。
package navi.main;
import java.io.IOException;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import db.MYSQLControl;
import model.DouBanUserUrl;
import parse.DouBanParse;
import simulate.DoubanSimulate;
/**
* @author:合肥工业大学 管理学院 钱洋
* @email:1563178220@qq.com
*/
public class DouBan {
static final Log logger = LogFactory.getLog(DouBan.class);
public static void main(String[] args) throws IOException, SQLException, InterruptedException {
//以一个为起点
/*List<DouBanUserUrl> DouBanUserUrlData=new ArrayList<DouBanUserUrl>();
DoubanSimulate.loginDouban();
String id="/conanemily/";
String redir="https://www.douban.com/people"+id+"contacts";
String html=DoubanSimulate.gethtml(redir);
DouBanUserUrlData=DouBanParse.getData(id,html);
if (DouBanUserUrlData.size()!=0) {
MYSQLControl.executeUpdate(DouBanUserUrlData);
}*/
//多个url,循环继续
List<DouBanUserUrl> DouBanUserUrlData=new ArrayList<DouBanUserUrl>();
//登陆网站
DoubanSimulate.loginDouban();
//从数据库获取需要爬取的用户id
List<DouBanUserUrl> DouBanUserUrlDatafromMYSQL=MYSQLControl.getListInfoBySQL("select user_id,user_contactsid from doubancontacts where tag=0",DouBanUserUrl.class);
System.out.println(DouBanUserUrlDatafromMYSQL.get(1).getUser_id());
int count=1;
//对需要爬取的每一个用户进行循环
for (DouBanUserUrl ids:DouBanUserUrlDatafromMYSQL) {
String id=ids.getUser_contactsid();
++count;
//待爬取的用户url
String redir="https://www.douban.com/people"+id+"contacts";
//防止爬虫被封杀,需要中间休息
if(count%2==0){
//产生随机数
int m = (int)(Math.random()*10);
Thread.sleep(m*1000);
}
logger.info("count:"+count+"+\tthe current crawl url is:"+redir);
//获取html信息
String html=DoubanSimulate.gethtml(redir);
//解析html信息
DouBanUserUrlData=DouBanParse.getData(id,html);
//存储获取的信息
if (DouBanUserUrlData.size()!=0) {
MYSQLControl.executeUpdatecontainId(DouBanUserUrlData,id);
}
}
}
}
解析html(parse)
这部分是针对获取的html内容进行解析,获取用户好友的id。这要使用的方法很简单,就是Jsoup。
package parse;
import java.util.ArrayList;
import java.util.List;
import model.DouBanUserUrl;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* @author:合肥工业大学 管理学院 钱洋
* @email:1563178220@qq.com
*/
public class DouBanParse {
//将需要返回的数据,保存到List中
public static List<DouBanUserUrl> getData (String user_id,String html) {
List<DouBanUserUrl> DouBanUserUrlData=new ArrayList<DouBanUserUrl>();
Document doc=Jsoup.parse(html);
Elements elements=doc.select("dl[class=obu]");
for (Element ele:elements) {
String user_contactsid=ele.select("dd").select("a").attr("href").replaceAll("https://www.douban.com/people", "");
DouBanUserUrl douBanUserUrl=new DouBanUserUrl();
douBanUserUrl.setUser_id(user_id);
douBanUserUrl.setUser_contactsid(user_contactsid);
DouBanUserUrlData.add(douBanUserUrl);
}
return DouBanUserUrlData;
}
}
数据库操作程序(db)
db中包含两个java文件,MyDataSource,MYSQLControl。这两个文件的作用已在前面说明了。
package db;
import javax.sql.DataSource;
import org.apache.commons.dbcp2.BasicDataSource;
/**
* @author:合肥工业大学 管理学院 钱洋
* @email:1563178220@qq.com
*/
public class MyDataSource {
public static DataSource getDataSource(String connectURI){
BasicDataSource ds = new BasicDataSource();
//MySQL的jdbc驱动
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUsername("root"); //所要连接的数据库名
ds.setPassword("112233"); //MySQL的登陆密码
ds.setUrl(connectURI);
return ds;
}
}
这里我写了很多的操作方面,本程序里面用到两个方法MYSQLControl.getListInfoBySQL()及MYSQLControl.executeUpdatecontainId()。其他方法,大家可以忽略不看,仅供大家写其他程序的时候参考。
package db;
import java.sql.SQLException;
import java.util.List;
import javax.sql.DataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.ResultSetHandler;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.apache.commons.dbutils.handlers.ColumnListHandler;
import org.apache.commons.dbutils.handlers.ScalarHandler;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import model.ContentModel;
import model.DouBanUserUrl;
/**
* @author:合肥工业大学 管理学院 钱洋
* @email:1563178220@qq.com
*/
public class MYSQLControl {
static final Log logger = LogFactory.getLog(MYSQLControl.class);
static DataSource ds = MyDataSource.getDataSource("jdbc:mysql://127.0.0.1:3306/moviedata");
static QueryRunner qr = new QueryRunner(ds);
//第一类方法
public static void executeUpdate(String sql){
try {
qr.update(sql);
} catch (SQLException e) {
logger.error(e);
}
}
//按照SQL查询单个结果
public static Object getScalaBySQL ( String sql ){
ResultSetHandler<Object> h = new ScalarHandler<Object>(1);
Object obj = null;
try {
obj = qr.query(sql, h);
} catch (SQLException e) {
e.printStackTrace();
}
return obj;
}
//按照SQL查询多个结果
public static <T> List<T> getListInfoBySQL (String sql, Class<T> type ){
List<T> list = null;
try {
list = qr.query(sql,new BeanListHandler<T>(type));
} catch (SQLException e) {
e.printStackTrace();
}
return list;
}
//查询一列
public static List<Object> getListOneBySQL (String sql,String id){
List<Object> list=null;
try {
list = (List<Object>) qr.query(sql, new ColumnListHandler(id));
} catch (SQLException e) {
e.printStackTrace();
}
return list;
}
//第二类数据库操作方法
public static void executeUpdate(List<DouBanUserUrl> data) throws SQLException {
Object[][] params = new Object[data.size()][2];
for ( int i=0; i<params.length; i++ ){
params[i][0] = data.get(i).getUser_id();
params[i][1] = data.get(i).getUser_contactsid();
}
try{
qr.batch("insert into doubancontacts (user_id, user_contactsid)"
+ "values (?,?)", params);
// qr.update("update movie set is_crawler=1 where id='"+id+"'");
}catch( Exception e){
logger.error(e);
}
}
//第三类数据库操作方法
public static void executeUpdatecontainId(List<DouBanUserUrl> data,String id) throws SQLException {
Object[][] params = new Object[data.size()][2];
for ( int i=0; i<params.length; i++ ){
params[i][0] = data.get(i).getUser_id();
params[i][1] = data.get(i).getUser_contactsid();
}
try{
qr.batch("insert into doubancontacts (user_id, user_contactsid)"
+ "values (?,?)", params);
qr.update("update doubancontacts set tag=1 where user_contactsid='"+id+"'");
}catch( Exception e){
logger.error(e);
}
}
public void handleTable ( ){
int rowNum = Integer.valueOf(getScalaBySQL("SELECT count(*) FROM qirui_jianghuai2016data.forum_comment;").toString() );
System.out.println(rowNum);
if ( rowNum >= 5000000 ){
int tableNum = Integer.valueOf(getScalaBySQL("SELECT number_flag FROM qirui_jianghuai2016data.table_utils_comment;").toString() );
executeUpdate("rename table qirui_jianghuai2016data.forum_comment to qirui_jianghuai2016data.forum_comment"+(tableNum+1));
executeUpdate("update qirui_jianghuai2016data.table_utils_comment set number_flag="+(tableNum+1));
executeUpdate("CREATE TABLE `qirui_jianghuai2016data`.`forum_comment` ( `comm_id` varchar(50) NOT NULL DEFAULT '' COMMENT '评论id,命名规则论坛编号+帖子id+评论ID',`post_id` varchar(50) DEFAULT NULL COMMENT '帖子ID,命名规则为论坛编号+帖子对应ID',`addr_id` varchar(50) DEFAULT NULL,`comm_userid` varchar(50) DEFAULT NULL COMMENT '发帖作者ID,命名规则论坛编号+作者id',`comm_userurl` varchar(100) DEFAULT NULL COMMENT '用户的url',`comm_time` datetime DEFAULT NULL COMMENT '用户的评论时间',`comm_content` text COMMENT '用户的评论内容',`craw_time` datetime DEFAULT NULL COMMENT '爬取时间',`report_time` datetime DEFAULT NULL COMMENT '数据更新时间',PRIMARY KEY (`comm_id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;");
}
}
//操作评论的数据库
public static void executeUpdateContent(List<ContentModel> data,String user_contactsid) throws SQLException {
Object[][] params = new Object[data.size()][8];
for ( int i=0; i<params.length; i++ ){
params[i][0] = data.get(i).getUser_id();
params[i][1] = data.get(i).getMovie_name();
params[i][2] = data.get(i).getMovie_id() ;
params[i][3] = data.get(i).getIntroduce();
params[i][4] = data.get(i).getRating();
params[i][5] = data.get(i).getRating_time() ;
params[i][6] = data.get(i).getComment();
params[i][7] = data.get(i).getTags() ;
}
try{
qr.batch("insert into doubanusercontent (user_id, movie_name,movie_id, introduce,rating,rating_time,comment,tags)"
+ "values (?,?,?,?,?,?,?,?)", params);
qr.update("update doubanuserid set tag=1 where user_contactsid='"+user_contactsid+"'");
}catch( Exception e){
logger.error(e);
}
}
}














 1486
1486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









