介绍:在使用爬虫时,对某些网站的爬取需要进行登录才能爬取到,在一般的带有登录的网站中通常采用cookie的方式保存信息,所以这里有两种方式:模拟登录 获取cookie以后的请求都带上cookie,直接登录网站 将cookie保存下来,相当于写死了;第一种当时比较灵活,第二中就会涉及到cookie过期
目标网站:豆瓣+我的用户名(binbin)

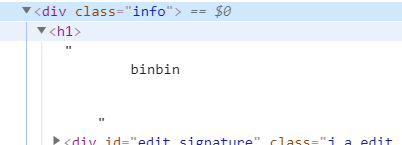
手动获取cookie:查看请求

1 用Jsoup设置cookie,并查看节点
代码:
package Jsoup;
import HttpClient.HttpClientPc;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
/**
* 已经有了cookie
*/
public class LoginCookie {
public static void main(String[] args) throws IOException {
String url="https://www.douban.com/people/205769149/";
LoginCookie loginCookie=new LoginCookie();
String cookie="";
loginCookie.setCookies(url,cookie);
}
/**
* 手动设置 cookies
* 先从网站上登录,然后查看 request headers 里面的 cookies
* @param url
* @throws IOException
*/
public void setCookies(String url,String cookie) throws IOException {
Document document = org.jsoup.Jsoup.connect(url)
// 手动设置cookies
.header("Cookie", cookie)
.get();
//
if (document != null) {
// 获取豆瓣昵称节点
Element element = document.select(".info h1").first();
if (element == null) {
System.out.println("没有找到 .info h1 标签");
return;
}
// 取出豆瓣节点昵称
String userName = element.ownText();
System.out.println("豆瓣我的网名为:" + userName);
} else {
System.out.println("出错啦!!!!!");
}
}
}
运行结果:

模拟登录方式:登录链接:登录豆瓣


代码:
package Jsoup;
import org.jsoup.Connection;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class login {
public static void main(String[] args) throws IOException {
String loginUrl="https://accounts.douban.com/j/mobile/login/basic";
String userInfoUrl="https://www.douban.com/people/205769149/";
login login=new login();
login.jsoupLogin(loginUrl,userInfoUrl);
}
/**
* Jsoup 模拟登录豆瓣 访问个人中心
* 在豆瓣登录时先输入一个错误的账号密码,查看到登录所需要的参数
* 先构造登录请求参数,成功后获取到cookies
* 设置request cookies,再次请求
* @param loginUrl 登录url :https://accounts.douban.com/j/mobile/login/basic
* @param userInfoUrl 个人中心url https://www.douban.com/people/205769149/
* @throws IOException
*/
public void jsoupLogin(String loginUrl,String userInfoUrl) throws IOException {
// 构造登陆参数
Map<String,String> data = new HashMap<>();
data.put("name","用户名");
data.put("password","密码");
data.put("remember","false");
data.put("ticket","");
data.put("ck","");
Connection.Response login = org.jsoup.Jsoup.connect(loginUrl)
.ignoreContentType(true) // 忽略类型验证
.followRedirects(false) // 禁止重定向
.postDataCharset("utf-8")
.header("Upgrade-Insecure-Requests","1")
.header("Accept","application/json")
.header("Content-Type","application/x-www-form-urlencoded")
.header("X-Requested-With","XMLHttpRequest")
.header("User-Agent","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36")
.data(data)
.method(Connection.Method.POST)
.execute();
login.charset("UTF-8");
// login 中已经获取到登录成功之后的cookies
// 构造访问个人中心的请求
Document document = org.jsoup.Jsoup.connect(userInfoUrl)
// 取出login对象里面的cookies
.cookies(login.cookies())
.get();
if (document != null) {
Element element = document.select(".info h1").first();
if (element == null) {
System.out.println("没有找到 .info h1 标签");
return;
}
String userName = element.ownText();
System.out.println("豆瓣我的网名为:" + userName);
} else {
System.out.println("出错啦!!!!!");
}
}
}
成功
2 使用httpclient模拟登录
好处:jsoup需要每一次请求都登陆,但是httpclient会保存session会话,登陆一次就会进行保存,以后无需登录
代码:
package HttpClient;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpUriRequest;
import org.apache.http.client.methods.RequestBuilder;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.net.URI;
public class login {
public static void main(String[] args) throws Exception {
String loginUrl="https://accounts.douban.com/j/mobile/login/basic";
String userInfoUrl="https://www.douban.com/people/205769149/";
login login=new login();
login.httpClientLogin(loginUrl,userInfoUrl);
}
/**
* httpclient 的方式模拟登录豆瓣
* httpclient 跟jsoup差不多,不同的地方在于 httpclient 有session的概念
* 在同一个httpclient 内不需要设置cookies ,会默认缓存下来
* @param loginUrl
* @param userInfoUrl
*/
public void httpClientLogin(String loginUrl,String userInfoUrl) throws Exception{
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpUriRequest login = RequestBuilder.post()
.setUri(new URI(loginUrl))// 登陆url
.setHeader("Upgrade-Insecure-Requests","1")
.setHeader("Accept","application/json")
.setHeader("Content-Type","application/x-www-form-urlencoded")
.setHeader("X-Requested-With","XMLHttpRequest")
.setHeader("User-Agent","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36")
// 设置账号信息
.addParameter("name","用户名")
.addParameter("password","密码")
.addParameter("remember","false")
.addParameter("ticket","")
.addParameter("ck","")
.build();
// 模拟登陆
CloseableHttpResponse response = httpclient.execute(login);
if (response.getStatusLine().getStatusCode() == 200){
// 构造访问个人中心请求
HttpGet httpGet = new HttpGet(userInfoUrl);
CloseableHttpResponse user_response = httpclient.execute(httpGet);
HttpEntity entity = user_response.getEntity();
//拿到body
String body = EntityUtils.toString(entity, "utf-8");
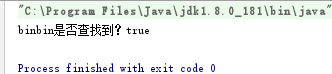
// 直接判断 用户名binbin是否存在
System.out.println("binbin是否查找到?"+(body.contains("binbin")));
}else {
System.out.println("httpclient 模拟登录豆瓣失败了!!!!");
}
}
}
























 919
919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











