







 本文详细介绍了Apache HBase,一种基于Hadoop和HDFS的分布式非关系型数据库,适合处理大规模随机读写操作。内容涵盖HBase的基本概念、逻辑和物理结构、架构、存储原理、WAL日志、region查找机制、使用方法,包括安装、客户端分类与使用、高级特性如rowkey设计、过滤器、计数器、版本控制、MapReduce集成和协处理器等。此外,还讨论了HBase的优化和运维策略,提供了丰富的示例和实战经验。
本文详细介绍了Apache HBase,一种基于Hadoop和HDFS的分布式非关系型数据库,适合处理大规模随机读写操作。内容涵盖HBase的基本概念、逻辑和物理结构、架构、存储原理、WAL日志、region查找机制、使用方法,包括安装、客户端分类与使用、高级特性如rowkey设计、过滤器、计数器、版本控制、MapReduce集成和协处理器等。此外,还讨论了HBase的优化和运维策略,提供了丰富的示例和实战经验。
hbase
测试例子文件:http://download.csdn.net/detail/ruishenh/9551930
hbase 是什么
官方说明:Use Apache HBase™ when youneed random, realtime read/write access to your Big Data. This project's goalis the hosting of very large tables -- billions of rows X millions of columns-- atop clusters of commodity hardware. Apache HBase is an open-source,distributed, versioned, non-relational database modeled after Google's Bigtable: A DistributedStorage System for Structured Data by Chang et al. Just as Bigtableleverages the distributed data storage provided by the Google File System,Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
0.非关系型数据库
1.随机、实时读写高并发
2.低廉的商用机器上部署(方便扩增)
3.高可用的分布式系统(一般依赖于HDFS,但不仅限于)
4.key-Value
hbase可以做什么
非固定模式设计的表,日志存储,常用访问记录性数据存储。
1.当你的数据增长呈几何倍增的时候(很短的时间里增长到千万,亿级的数据,实时读写高并发)
2.当你的查询相对来讲固定的时候
3.当你后期面临着N多的数据分析的时候
4.当数据模式非结构化的时候
等等
hbase 逻辑结构
和关系型数据库的简单比较
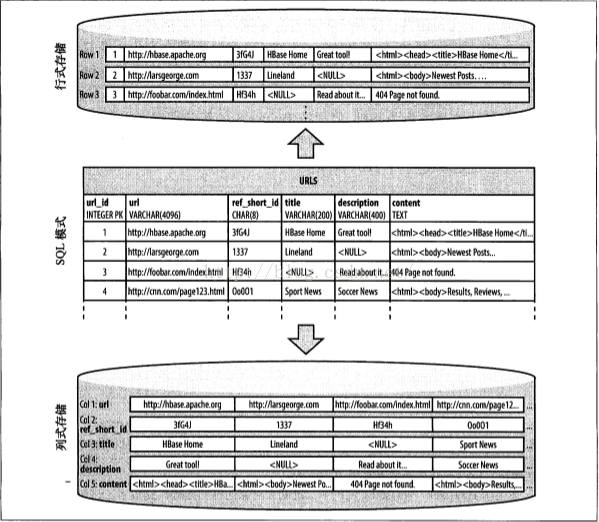
HBase以表的形式存储数据。表有行和列组成。列划分为若干个列族(row family)

Row Key
与nosql数据库们一样,row key是用来检索记录的主键。访问hbase table中的行,只有三种方式:
1 通过单个rowkey访问 (get)
2 通过rowkey的range (scan)
3 全表扫描
Row key行键 (Row key)可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes),在hbase内部,row key保存为字节数组。
存储时,数据按照Row key的字典序(byte order)排序存储。设计key时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
注意:
字典序对int排序的结果是1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99。要保持整形的自然序,行键必须用0作左填充。
行的一次读写是原子操作 (不论一次读写多少列)。这个设计决策能够使用户很容易的理解程序在对同一个行进行并发更新操作时的行为。
列族
hbase表中的每个列,都归属与某个列族。列族是表的schema的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如courses:history , courses:math 都属于 courses 这个列族。
访问控制、磁盘和内存的使用统计都是在列族层面进行的。实际应用中,列族上的控制权限能 帮助我们管理不同类型的应用:我们允许一些应用可以添加新的基本数据、一些应用可以读取基本数据并创建继承的列族、一些应用则只允许浏览数据(甚至可能因 为隐私的原因不能浏览所有数据)。
时间戳
HBase中通过row和columns确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由hbase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,hbase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。maxversion=3 verson=1
Cell
由{rowkey, column( =<family> + <label>), version} 唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存贮。
hbase 物理结构
1、Table中所有行都按照row key的字典序排列;
2、Table在行的方向上分割为多个Region;
3、Region按大小分割的,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region,之后会有越来越多的region;
4、Region是Hbase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上。

5、Region虽然是分布式存储的最小单元,但并不是存储的最小单元。Region由一个或者多个Store组成,每个store保存一个 columnsfamily;每个Strore又由一个memStore和0至多个StoreFile组成,StoreFile就是对HFile的轻量级封装;memStore存储在 内存中,StoreFile存储在HDFS上。
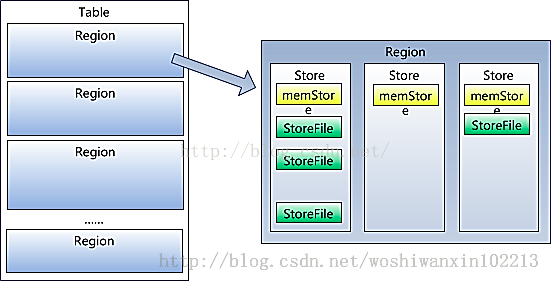
6.HFile, HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,实际StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile
HFile的存储格式
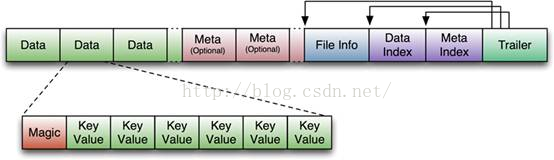
首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。正如图中所示的,
Trailer中有指针指向其他数 据块的起始点。
File Info中记录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN,LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。
Data Index和Meta Index块记录了每个Data块和Meta块的起始点。
Meta Block 段 (可选的)–保存用户自定义的kv对,可以被压缩。
Data Block是HBase I/O的基本单元,为了提高效率,HRegionServer中有基于LRU的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定,大号的Block有利于顺序Scan,小号Block利于随机查询。 每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成, Magic内容就是一些随机数字,目的是防止数据损坏。后面会详细介绍每个KeyValue对的内部构造。
HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个byte数组里面包含了很多项,并且有固定的结构
keyValue格式

开始是两个固定长度的数值,分别表示Key的长度和Value的长度。紧接着是Key,开始是固定长度的数值,表示RowKey的长度,紧接着是 RowKey,然后是固定长度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete)。Value部分没有这么复杂的结构,就是纯粹的二进制数据了。
查看下hbase 的内容:用hfile命令(hbase hfile 能看到对应的参数解释)
[hcr@localhost 桌面]$ hbase hfile -bmpf/hbase/data/default/hcr_test/57df02bcef30c53874263ad8d72626ff/cf/f308df775b6b470eaa006df6623b5f2a
K:20150123000000001111/cf:skuID/1465113764558/Put/vlen=4/mvcc=0 V: 1234
K:20150123000000001315/cf:url/1465113632832/Put/vlen=13/mvcc=0 V: www.baidu.com
K:20150123000000002111/cf:url/1465113632920/Put/vlen=13/mvcc=0 V: www.baidu.com
K:20150123000000002214/cf:url/1465113632958/Put/vlen=13/mvcc=0 V: www.baidu.com
K:20150123000000002315/cf:url/1465113634419/Put/vlen=13/mvcc=0 V: www.baidu.com
Block indexsize as per heapsize: 408
reader=/hbase/data/default/hcr_test/57df02bcef30c53874263ad8d72626ff/cf/f308df775b6b470eaa006df6623b5f2a,
compression=none,
cacheConf=CacheConfig:enabled[cacheDataOnRead=true] [cacheDataOnWrite=false] [cacheIndexesOnWrite=false][cacheBloomsOnWrite=false] [cacheEvictOnClose=false] [cacheCompressed=false],
firstKey=20150123000000001111/cf:skuID/1465113764558/Put,
lastKey=20150123000000002315/cf:url/1465113634419/Put,
avgKeyLen=37,
avgValueLen=11,
entries=5,
length=1344
Trailer:
fileinfoOffset=496,
loadOnOpenDataOffset=370,
dataIndexCount=1,
metaIndexCount=0,
totalUncomressedBytes=1235,
entryCount=5,
compressionCodec=NONE,
uncompressedDataIndexSize=52,
numDataIndexLevels=1,
firstDataBlockOffset=0,
lastDataBlockOffset=0,
comparatorClassName=org.apache.hadoop.hbase.KeyValue$KeyComparator,
majorVersion=2,
minorVersion=3
Fileinfo:
BLOOM_FILTER_TYPE = ROW
DATA_BLOCK_ENCODING = NONE
DELETE_FAMILY_COUNT =\x00\x00\x00\x00\x00\x00\x00\x00
EARLIEST_PUT_TS =\x00\x00\x01U\x1F\x93\xE0@
KEY_VALUE_VERSION = \x00\x00\x00\x01
LAST_BLOOM_KEY = 20150123000000002315
MAJOR_COMPACTION_KEY = \x00
MAX_MEMSTORE_TS_KEY =\x00\x00\x00\x00\x00\x00\x00\x00
MAX_SEQ_ID_KEY = 14
TIMERANGE = 1465113632832....1465113764558
hfile.AVG_KEY_LEN = 37
hfile.AVG_VALUE_LEN = 11
hfile.LASTKEY =\x00\x1420150123000000002315\x02cfurl\x00\x00\x01U\x1F\x93\xE6s\x04
Mid-key:\x00\x1420150123000000001111\x02cfskuID\x00\x00\x01U\x1F\x95\xE2\xCE\x04
Bloom filter:
BloomSize: 8
No of Keys in bloom: 5
Max Keys for bloom: 6
Percentage filled: 83%
Number of chunks: 1
Comparator: RawBytesComparator
Delete FamilyBloom filter:
Not present
Block Index:
size=1
key=20150123000000001111/cf:skuID/1465113764558/Put
offset=0, dataSize=325
Scanned kvcount -> 5
hbase 架构
基本组件
HBase的服务器体系结构遵循简单的主从服务器架构,它由HRegion服务器(HRegion Server)群和HBase Master服务器(HBaseMaster Server)构成。HBase Master服务器负责管理所有的HRegion服务器,而HBase中所有的服务器都是通过ZooKeeper来进行协调,并处理HBase服务器运行 期间可能遇到的错误。HBase Master Server本身不存储HBase中的任何数据,HBase逻辑上的表可能会被划分为多个HRegion,然后存储到HRegion Server群中,HBase Master Server中存储的是从数据到HRegionServer中的映射。
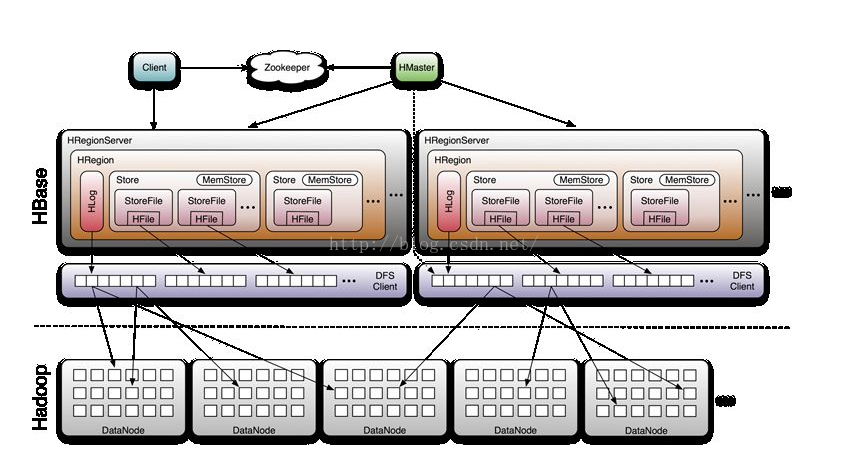
Client
操作HBase的接口,并维护cache来加快对HBase的读或者写操作
Zookeeper
维护master的单点问题
存贮所有Region的寻址入口
实时监控Region server的上线和下线信息。并实时通知给Master
存储HBase的schema和table元数据 指针
WAL监控 等等(split,roller);
可能新版本还会有其他的监控等等吧
Master
为Region server分配region
负责Region server的负载均衡
发现失效的Region server并重新分配其上的region
管理用户对table的增删改查操作
HregionServer
HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
所有的数据库数据一般是保存在Hadoop分布式文件系统上面的,用户通过一系列HRegion服务器来获取这些数据,一台机器上面一般只运行一个HRegionServier,且每一个区段的HRegion也只会被一个HRegionServier维护。
当用户需要更新数据的时候,他会被分配到对应的HRegionServier上提交修改,这些修改先是被写到memStore(内存中的缓存,保存最 近更新的数据)缓存和服务器的Hlog(磁盘上面的记录文件,他记录着所有的更新操作)文件里面。在操作写入Hlog之后,commit()调用才会将其 返回给客户端。
在读取数据的时候,HRegionServier会先访问memStore缓存,如果缓存里没有改数据,才会回到Store磁盘上面寻找,每一个列族都会有一个Store集合,每一个Store集合包含很多storeFile(封装了Hfile)文件
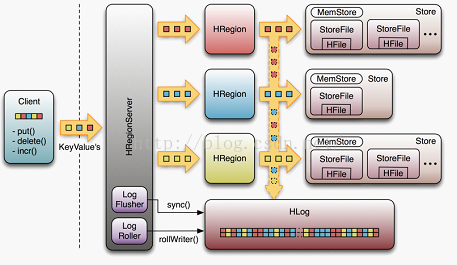
存储原理
LSM树(log-structured merge-tree)则按另一种方式组织数据。输入数据首先被存储在日志文件,这些文件内的数据完全有序。当有日志文件被修改时,对应的更新会被先保存在内存中来加速查询。
当系统经历过许多次数据修改,且内存空间被逐渐被占满后,LSM树会把有序的“键-记录”对写到磁盘中,同时创建一个新的数据存储文件。此时,因为最近的修改都被持久化了,内存中保存的最近更新就可以被丢弃了。
存储文件的组织与B树相似,不过其为磁盘顺序读取做了优化,所有节点都是满的并按页存储。修改数据文件的操作通过滚动合并完成,也就是说,系统将现有的页与内存刷写数据混合在一起进行管理,直到数据块达到它的容量
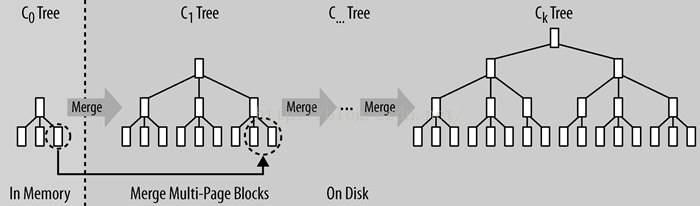
在内存中多个块存储归并到磁盘的过程,合并写入会产生一个新的结果块,最终多个块被合并为更大块。
多次数据刷写之后会创建许多数据存储文件,后台线程就会自动将小文件聚合成大文件,这样磁盘查找就会 被限制在少数几个数据存储文件中。磁盘上的树结构也可以拆分成独立的小单元,这样更新就可以被分散到多个数据存储文件中。所有的数据存储文件都按键排序, 所以没有必要在存储文件中为新的键预留位置。
查询时先查找内存中的存储,然后再查找磁盘上的文件。这样在客户端看来数据存储文件的位置是透明的。
删除是一种特殊的更改,当删除标记被存储之后,查找会跳过这些删除过的键。当页被重写时,有删除标记的键会被丢弃。
此外,后台运维过程可以处理预先设定的删除请求。这些请求由TTL(time-to-live)触发,例如,当TTL设为20天后,合并进程会检查这些预设的时间戳,同时在重写数据块时丢弃过期的记录。
B树和LSM树最主要的区别在于它们的结构如何利用硬件,特别是磁盘。
WAL(write-ahead-log)
region服务器会将数据保存到内存中,直到积攒足够多的数据再将其刷写到硬盘上,这样可以避免创建很多小文件。存储在内存中的数据是不稳定的,例如,在服务器断电的情况下数据就可能会丢失。一个比较常见的解决这个问题的方法是预写日志(WAL)每次更新都会写入日志,只有写入成功才会通知客户端操作成功,然后服务器可以按需自由地批量处理或聚合内存中的数据。
当灾难发生的时候,WAL就是所需的生命线。类似于MySQL的binary log,WAL存储了对数据的所有更改。这在主存储器出现意外的情况下非常重要。如果服务器崩溃,它可以有效地回放日志,使得服务器恢复到服务器崩溃以 前。这也就意味着如果将记录写入到WAL失败时,整个操作也会被认为是失败的。
处理过程如下:首先客户端启动一个操作来修改数据。例如,可以对put()、delete()和increment()进行调用。每一个修改都封装到一个KeyValue对象实例中,并通过RPC调用发送出去。这些调用(理想情况下)成批地发送给含有匹配region的HRegionServer。
一旦KeyValue实例到达,它们会被发送到管理相应行的HRegion实例。数据被写入到WAL,然后被放入到实际拥有记录的存储文件的MemStore中。实质上,这就是HBase大体的写路径。
最后,当memstore达到一定的大小或是经历一个特定的时间之后,数据就会异步地连续写入到文件 系统中。在写入的过程中,数据以一种不稳定的状态存放在内存中,即使在服务器完全崩溃的情况下,WAL也能够保证数据不会丢失,因为实际的日志存储在 HDFS上。其他服务器可以打开日志文件然后回放这些修改—恢复操作并不在这些崩溃的物理服务器上进行。
当然WAL可以关闭比如当执行大规模的Mapreduce运算的时候一般都是关闭的。
region查找
client->zookeeper->.ROOT->.META-> 用户数据表
zookeeper记录了.ROOT的路径信息(root只有一个region),.ROOT里记录了.META的region信息, (.META可能有多个region),.META里面记录了region的信息
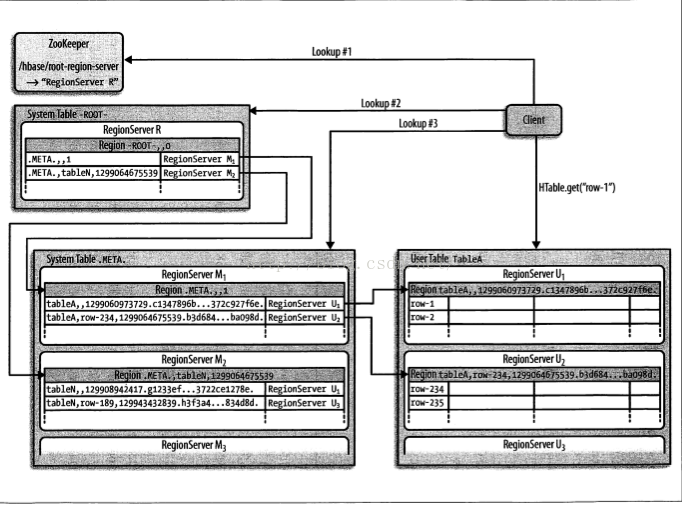
(在0.96+以上)ROOT表已经改名为hbase:namespace,META则是hbase:meta .
client->zookeeper->meta-region-server->regionServer上meta数据查找具体Regioin
hbase使用
1.安装
因官方和各大论坛都存在很多的安装介绍,此处就不再熬述。
2.客户端
1.客户端分类
交互客户端
hbase的客户端访问有很多种比较常用的就是
JAVA 原生语言
比如创建表:
HBaseAdmin admin = new HBaseAdmin(conf);
HTableDescriptor desc = new HTableDescriptor(TableName.valueOf(tableName));
for (inti =0; i < family.length; i++) {
desc.addFamily(new HColumnDescriptor(family[i]));
}
if (admin.tableExists(tableName)) {
System.out.println("table Exists!");
} else {
admin.createTable(desc);
System.out.println("create table Success!");
}
shell 基于ruby语言实现
[hcr@localhost hbase-0.96.1.1-cdh5.0.6]$bin/hbase shell
2016-05-22 20:14:17,696 INFO [main] Configuration.deprecation:hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter 'help<RETURN>'for list of supported commands.
Type "exit<RETURN>" toleave the HBase Shell
Version 0.96.1.1-cdh5.0.6, rUnknown, MonApr 6 13:14:38 PDT 2015
hbase(main):001:0>
COMMANDGROUPS:
Groupname: general
Commands:status, table_help, version, whoami
Groupname: ddl
Commands:alter, alter_async, alter_status, create, describe, disable, disable_all, drop,drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list,show_filters
http://www.cnblogs.com/johnnyflute/p/3654426.html?utm_source=tuicool&utm_medium=referral
Groupname: namespace
Commands:alter_namespace, create_namespace, describe_namespace, drop_namespace,list_namespace, list_namespace_tables
Groupname: dml
Commands:count, delete, deleteall, get, get_counter, incr, put, scan, truncate,truncate_preserve
Groupname: tools
Commands:assign, balance_switch, balancer, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch,close_region, compact, flush, hlog_roll, major_compact, merge_region, move,split, trace, unassign, zk_dump
Groupname: replication
Commands:add_peer, disable_peer, enable_peer, list_peers, list_replicated_tables,remove_peer
Groupname: snapshot
Commands:clone_snapshot, delete_snapshot, list_snapshots, rename_snapshot,restore_snapshot, snapshot
Groupname: security
Commands:grant, revoke, user_permission
rest
启动
hbaserest start
[hcr@localhost ~]$ curl -X gethttp://localhost:8080/
hcr_test
t1
http://localhost:8080/version
http://localhost:8080/version/cluster
http://localhost:8080/status/cluster
http://localhost:8080/
http://localhost:8080/t1/schema
参考:
http://kane-xie.iteye.com/blog/2228967
http://wiki.apache.org/hadoop/Hbase/HbaseRest
thrift 各种语言版本的接口
官方文档:http://wiki.apache.org/hadoop/Hbase/ThriftApi
avro
hadoop生态圈的一种类是与thrfit的协议和序列化框架
除了以上客户端还有一些批处理客户端(pig,hive,mapreduce,)和其他小使用范围语言的client没有列入。
3.Example
Maven 依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>0.96.1.1-hadoop2</version>
</dependency>
java API 调用
| package com.ruishenh.hbase.client.java; import com.google.common.io.Closeables; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.*; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.util.Bytes; import java.io.IOException; public class HbaseClient { // 声明静态配置 st |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









