










一、数据导入
In [2]:
import pandas from pandas import set_option #括号里面直接指定了数据的来源,当然你也可以按照老师视频中所讲授的来操作 iris = pandas.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data') iris.columns=['sepal_length','sepal_width','petal_length','petal_width','species']
导入seaborn
In [5]:
import matplotlib.pyplot as plt import seaborn as sns #要注意的是一旦导入了seaborn,matplotlib的默认作图风格就会被覆盖成seaborn的格式
让图片在notebook里面更加灵活
In [11]:
%matplotlib notebook
中文显示
In [4]:
plt.rc('font', family='SimHei', size=8)
二、条形图
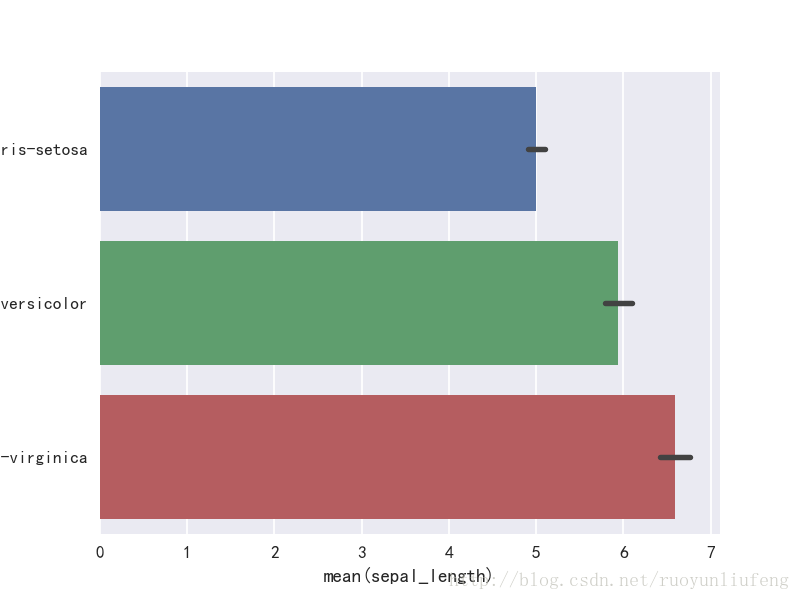
In [10]:
sns.barplot(x="sepal_length",y="species",data=iris)
Out[10]:
<matplotlib.axes._subplots.AxesSubplot at 0x8fa54b0>
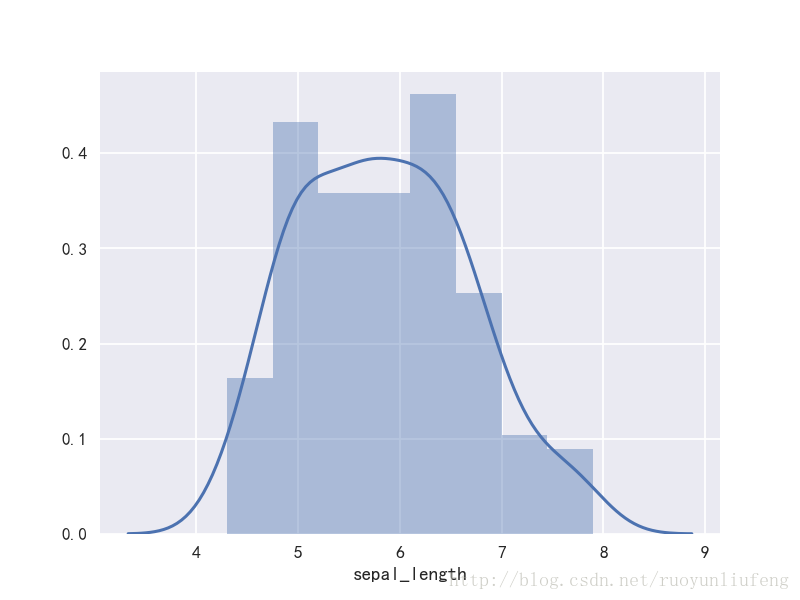
三、直方图
In [11]:
sns.distplot(iris["sepal_length"])
Out[11]:
<matplotlib.axes._subplots.AxesSubplot at 0x8fb49b0>
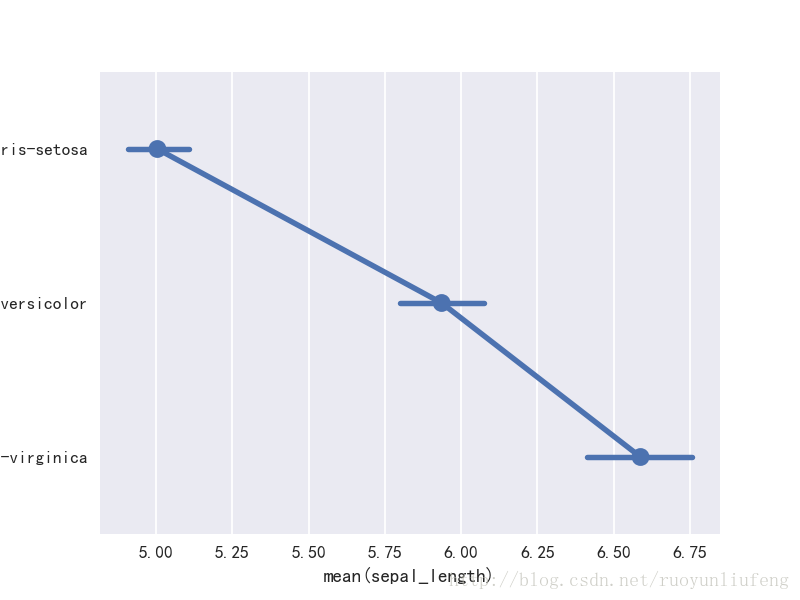
三、折线图
In [12]:
sns.pointplot(x="sepal_length",y="species",data=iris)
Out[12]:
<matplotlib.axes._subplots.AxesSubplot at 0xb1f7770>
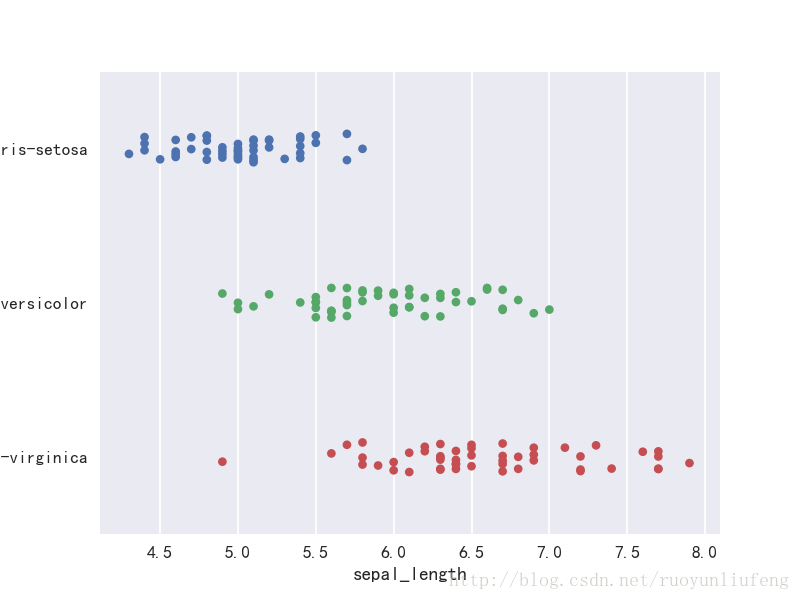
四、散点图
普通散点图
In [19]:
sns.stripplot(x="sepal_length", y="species", data=iris, jitter=True, edgecolor="gray")
Out[19]:
<matplotlib.axes._subplots.AxesSubplot at 0xb97c050>
带回归线的散点图
In [15]:
sns.regplot(x="sepal_length",y="sepal_length",data=iris)
Out[15]:
<matplotlib.axes._subplots.AxesSubplot at 0xb62a370>
五、箱形图
In [20]:
sns.boxplot(x="sepal_length",y="species",data=iris)
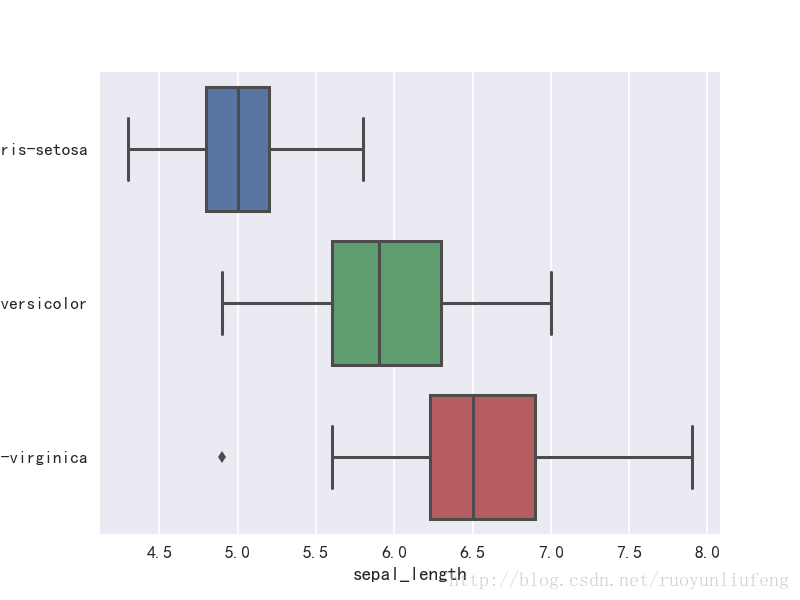
Out[20]:
<matplotlib.axes._subplots.AxesSubplot at 0xb97c950>
六、小提琴图
In [22]:
sns.violinplot(x="sepal_length", y="species", data=iris, size=6)
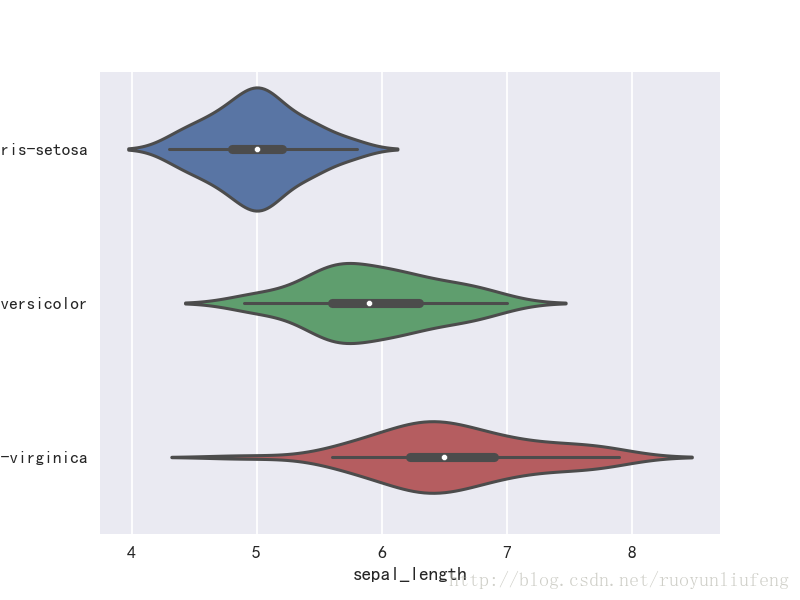
Out[22]:
<matplotlib.axes._subplots.AxesSubplot at 0xbb69450>
七、pairplot
In [61]:
sns.pairplot(iris,hue="species",size=2)
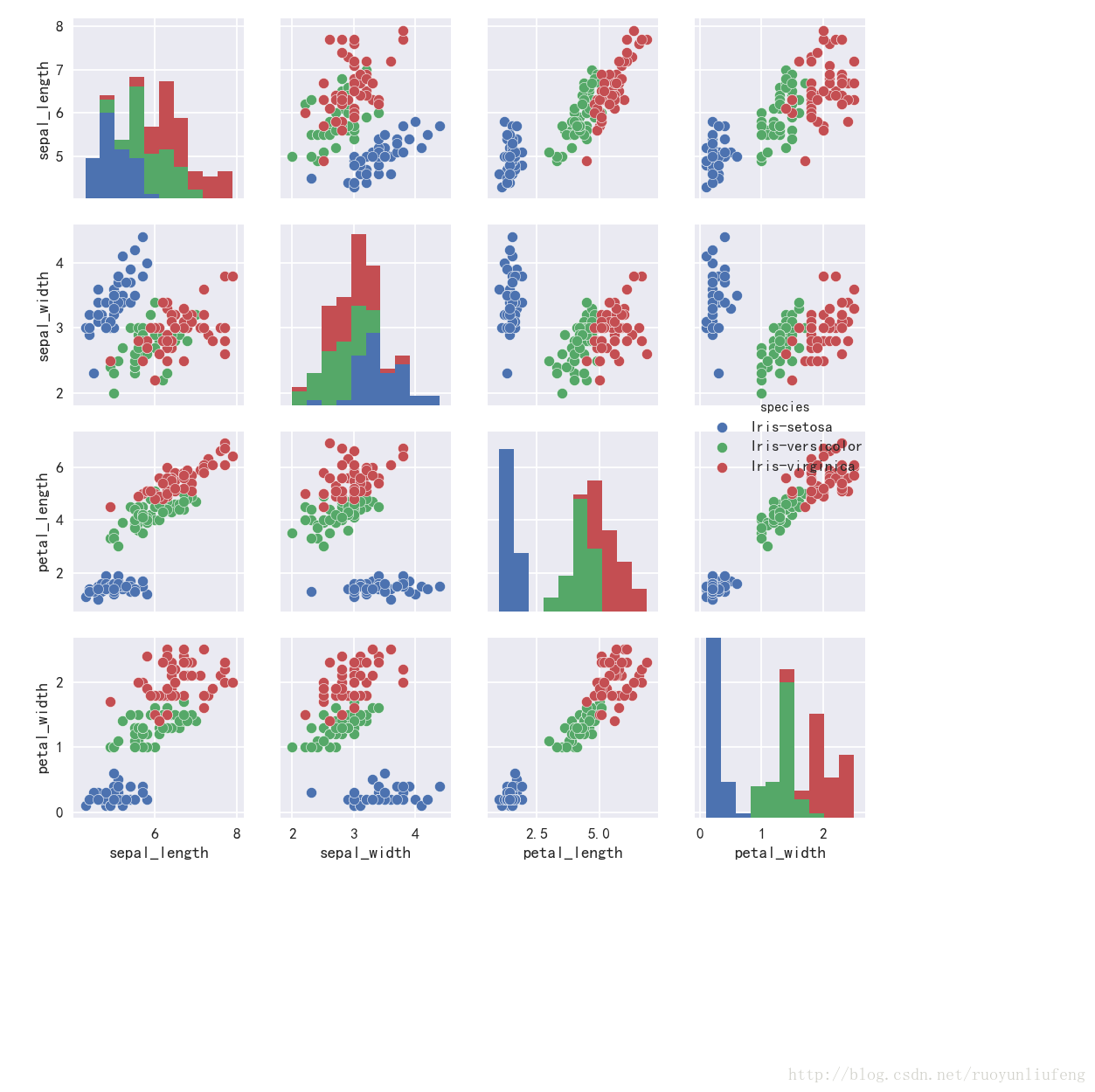
Out[61]:
<seaborn.axisgrid.PairGrid at 0x2593e850>
显示kde
In [55]:
sns.pairplot(iris,hue="species", size=2, diag_kind="kde")
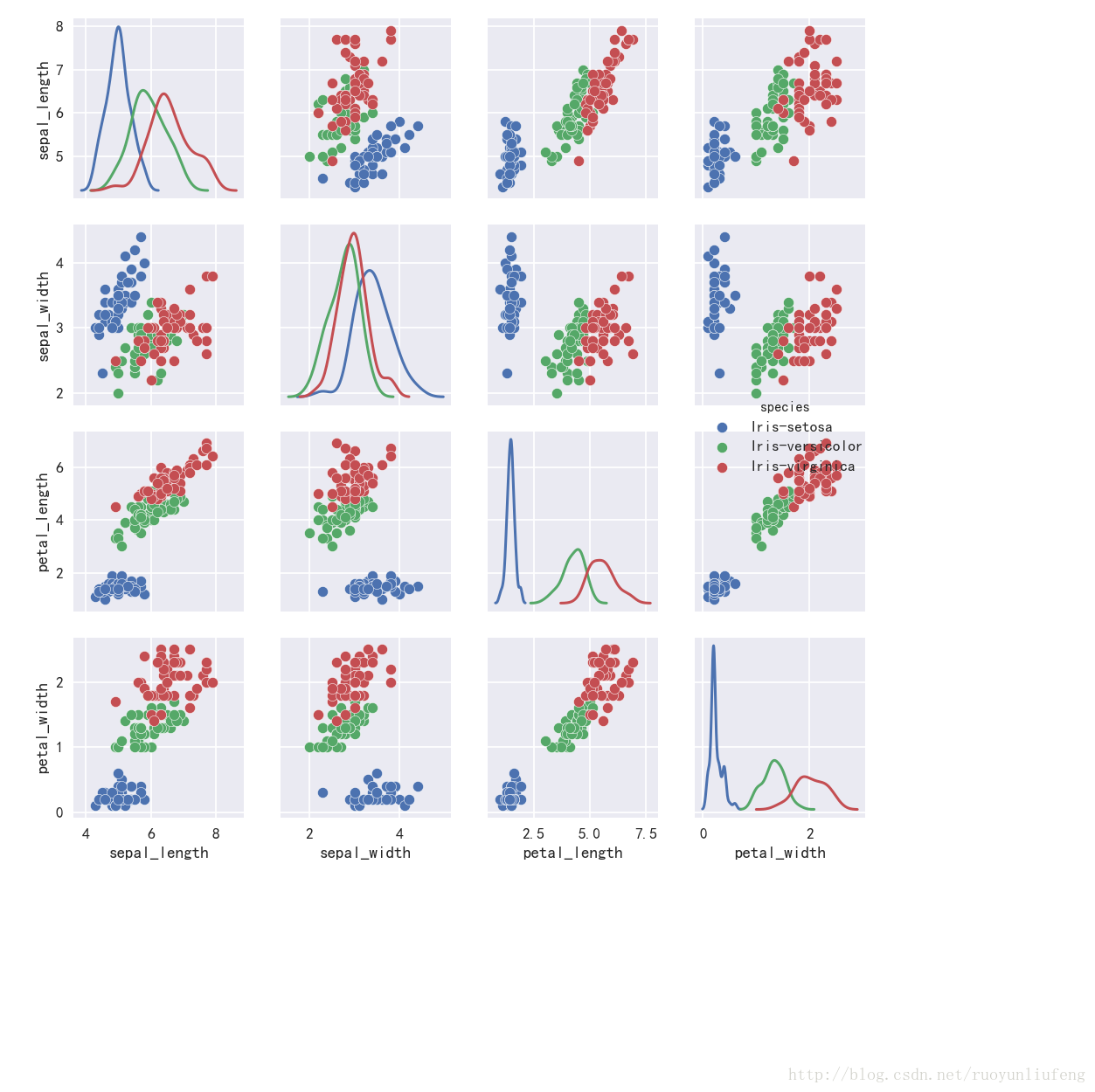
Out[55]:
<seaborn.axisgrid.PairGrid at 0x23491b30>
八、热点图
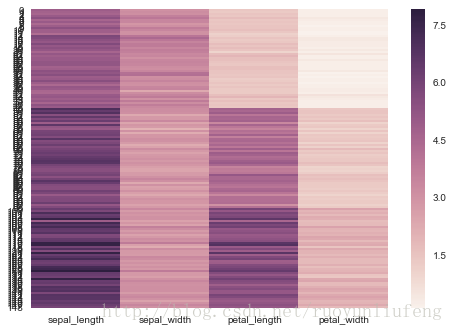
In [8]:
iris_nospecies = iris.pop("species") sns.heatmap(iris) #
Out[8]:
<matplotlib.axes._subplots.AxesSubplot at 0xb2b0730>
In [9]:
plt.show()
In [12]:
sns.clustermap(iris, fmt="d",cmap='YlGnBu',figsize=(6,9))
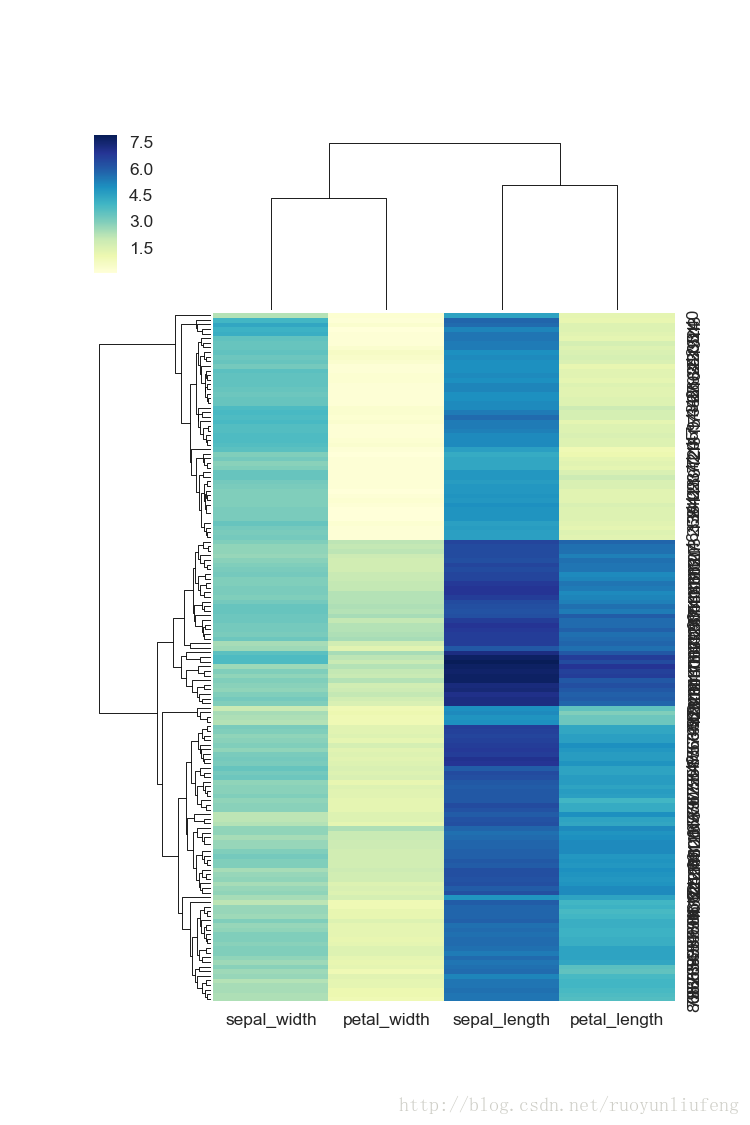
Out[12]:
<seaborn.matrix.ClusterGrid at 0xe6675f0>
















 9850
9850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











