







本文基于http://beader.me/的博客进行编写,有些的地方我做了简单修改,公式也重新敲了,加深一下理解。
银行在决定是否要通过贷款申请人的授信请求前,会根据申请人的资料对其进行风险评估,(通常银行会为其计算信用评分),申请人状况符合银行要求时,银行通过其申请,反之则婉拒。那么银行凭借什么来判断申请人将来是否会违约呢?通过银行之前的信用贷款记录,这些记录中,有些客户发生了违约行为,其他则表现良好,银行从这些违约与非违约的记录中learning到了一些规律,然后利用这些规律,来对新申请人的违约风险进行估计。因此信用评估模型就是一个learning的问题,那么我们该如何使用历史数据做好learning呢?
下面这张图描述了learning的基础架构:

f:X→Y
,其中
X
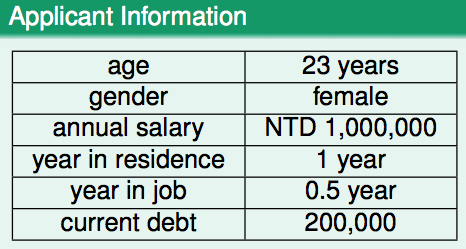
表示输入空间,譬如下图中第一列
(age, gender, annual salary, year in residence, year in job, current
debt)
为输入空间(6维),而右边一列
(23 years, female, NTD 1,000,000, 1 year, 0.5 year, 200,000)
为该输入空间下的一个向量,每位贷款申请人对应该空间下的一个向量。
-
D
:(x1,y1),⋯,(xN,yN)为训练集,该训练集有N笔数据,每笔数据由某申请人在
X 中的向量和与其对应的类别构成。 -
H
,hypothesis set是一个由有限个或无限个方程组成的集合,算法
A 只能从 H 的范围内挑选方程。 A ,是一个学习算法,它能够帮助我们在 H 中找到一个与f 的判断最接近或足够接近的一个方程。当然我们可以说穷举法是一种学习算法,当 H 中candidate formula数量不多时,我们可以用穷举法来寻找。但往往candidate formula数量很大甚至是无穷的,我们就需要设计一个比较好的算法,他能够在较短时间找到我们想要的那个方程。g ,final hypothesis,即 A 从H 中挑选的和f判断最接近的那个方程。说到底,learning在干的事情,就是从hypothesis set里面挑一个“长”的最像 f 的方程
g ,注意前面我的用词是用”它的判断接近 f ”,并不是说g 和f结构很类似,(记住 f 永远是unknown的),而是说他们的判断很一致,即f(x)≈g(x) 。并且这里谈到的接近,是针对训练集 D 而言的,D 之外的数据他们能否表现一致,这才是我们最应该关心的问题,如果 D 之外他们也能够表现一致,说明我们learning的还不错,我们有从D 上面学到东西。这时候换个角度来想,能不能有某个理论,来保证我们的g与f在 D 之外也能有差不多的接近程度?
Learning真的可行吗? (Is Learning Feasible?)

图片前两行为training set,对于第一行的所有样本,有f(x)=−1,对于第二行的所有样本,有f(x)=+1,那么我们能不能通过这6笔数据来猜测一下f是长什么样的呢?同学1和同学2利用各自的学习方法分别给出了自己的g
- 同学1训练出来的g:
g1 (对称图形)=+1 g1 (非对称图形)=−1 - 同学2训练出来的g: g2 (左上角为白色的图形)=+1 g2 (左上角为黑色的图形)=−1
对于training set中所有样本,有 g1(x)=g2(x)=f(x) ,即两个 g1 , g2 与 f 的表现是一致的,似乎可以认为他们都”学”到了东西,但是对于测试样本来说
g1(x)=+1 , g2(x)=−1 。真实的f我们无法知道,如果他们中的某一个人在所有非训练的资料中也和 f(x) 表现一致,我们才能说他们当中某个人真的学到了东西。但在目前这种情况下,我们无法说同学1学到了东西还是同学2学到了东西。让我们再来考虑一个简单的二元分类问题。 x=0,13,y=o,×1

为何要举这么简单的例子呢?因为前面我们说到真实的
f
是我们无法知道的,但在上面这个简单的例子中,我们有办法把所有可能的

可能产生这样的
D
的f只可能有8种并且只有其中的1个是正确的,这样一来,虽然我们可以保证我们的
推断未知的世界(Inferring Something Unknown)
我们知道在前面简单版的learning问题中,由于我们无法推断

- bin,即总体,假设 P(orange)=μ , P(green)=1−μ 。但我们无法知道 μ 到底多大。
sample,即样本,数量为
N ,在抽出的 N 个小球中,orange的比例为ν ,green的比例为 1−ν ,数一数就能算出 ν 。问题来了,这个
ν 能不能在一定程度上代表了 μ 。也许不能,因为即使bin中orange占多数,也可能发生这样的事情,你抽了10个小球出来但全是green的。但这种事情发生的可能性大吗?不大,并且如果我们有更多的样本(抽出更多的球),则这种事情发生的可能性会越来越小。在概率论中,可以用Hoeffding’s Inequality来描述上面那件事情的概率:
ℙ[|ν−μ|>ϵ]≤2exp(−2ϵ2N)
注: ϵ 是我们的容忍度,当μ 与 ν 的差别小于容忍度时,我们称μ 与 ν “差不多”(PAC, probably approximately correct),当μ 与 ν 差别大于容忍度时,我们称μ 与 ν ”差很多”。“差很多”这件事发生的概率越小越好,最大不会超过右边。上面这个不等式中,控制右边数值大小的只有
ϵ2 和 N ,ϵ2 减小(要求降低)与 N (样本增加)增大都能够使坏事情发生的概率的上限减少。当上限足够小的时候,我们可以说,sample中orange的比例和bin中orange的概率差不多,如果sample中的orange比例少,则bin中的orange的比例也会比较少。
我们可以把learning与抓球这件事结合起来。

还记得之前说过的f 吗?他代表未知的真理,而 h(x) 是是属于hypothesis set H 的某一个方程。对于某一个向量xn :如果 h(xn)≠f(xn) ,即他们判断不一致,我们记第 n 个小球是orange
- 如果
h(xn)=f(xn) , 即他们判断是一致的,我们记第 n 个小球是green
(好吧,这块我也没想清。。。。。)
利用之前抓小球的逻辑,我们可以利用sample中orange的比例来推断总体中orange出现的概率,则同样的,我们可以利用sample中h(x)≠f(x) 的比例来推断总体中 h(x)≠f(x) 的概率。这里 h(x)≠f(x) 表示一个error,则我们可以称
Ein (in-sample-error): h(x) 在sample中出现error的比例,
- Eout (out-of-sample-error): 在总体中出现error的概率为。则对于 h 来说:
Eout(h)=ϵx∼P[h(x)≠f(x)] , ϵ 表示数学期望Ein(h)=1N∑n=1N[h(xn)≠yn] 利用Hoeffding’s Inequality,我们可以写成:
ℙ[|Ein(h)−Eout(h)|>ϵ]≤2exp(−2ϵ2N)
简单说来,当右边这个“上界”足够小时,我们可以说 h 在sample中的表现(错误率)与h在总体中的表现是差不多的。

注意这里仅仅是说,对于一个固定的
h(fixedh) 而言, Ein(h) 会与 Eout(h) 很接近,这种情况能说是一种好的learning吗?当然不能,因为如果 Ein(h) 很大,则 Eou t也大,这样是没有意义的。因此我们的算法 A 要能够自由的从H 中挑选方程,我们把 A 挑选出的最好的h 称为 g (final hypothesis)。因此这里就需要添加一个验证流程(Verification Flow),这个流程使用历史数据来判断某个h 够不够好。

不幸的状况 (Bad Data)
前面说到,
A
要能够自由的在
learning同样会遇到bad sample的麻烦。比如实际上
h1
是个很好的方程,本来能够成为
g
的,但是由于抽样误差,碰到了bad sample,造成
因此只要
H
中任意个
由此看出,learning得好不好,还与
H
里面的方程数量
总结 (Summary)
从概率论的角度出发,可以证明learning的确是可行的。因此,只有当
Ein(h)
和
Eout(h)
的判断很接近的时候,我们才能说learning是可行的。可行之余,倘若
Ein(h)
很大,这样的learning也没有太大意义,因为你的这个h在sample中表现不好,则他在out-of-sample中表现也不大可能会好。我们把
H
中表现最好(















 2228
2228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









