









用Apriori、FP Growth、eclat算法进行关联分析时中,常常用到Groceries数据集,该数据集是某个杂货店一个月真实的交易记录,共有9835条消费记录,169个商品。在开源软件RGui的arules程序包里含有Groceries数据集,保存格式是.rda,如图(1)所示:
下面,进行Grocerices数据集的导出到Groceries.csv中,详细步骤如下。
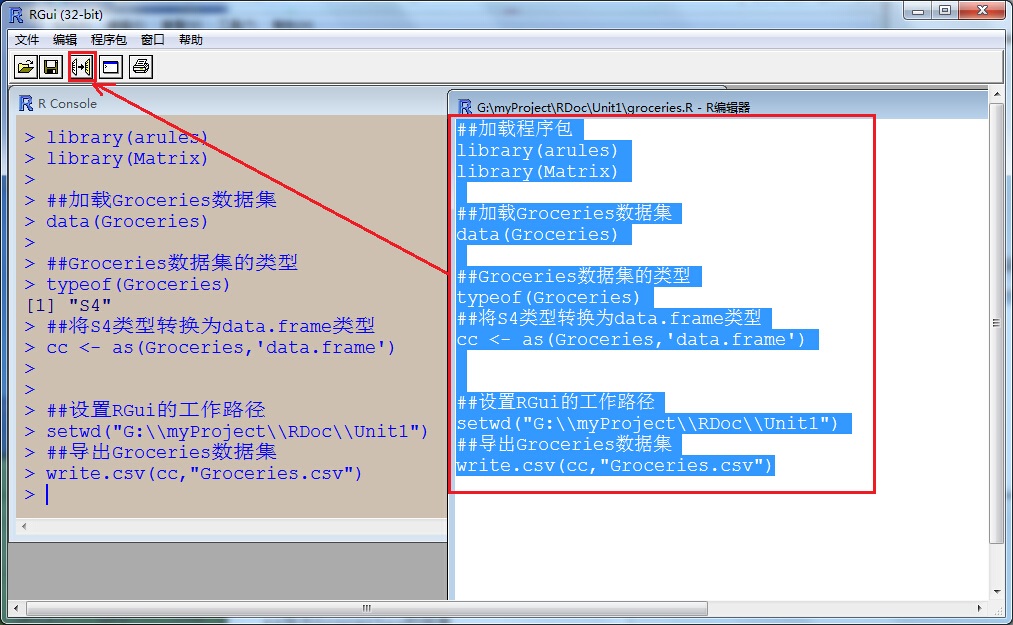
1)打开RGui,点击【文件】–》新建程序脚本 –》命名为:groceries.R ,代码如下:
//groceries.R
##加载程序包
library(arules)
library(Matrix)
##加载Groceries数据集
data(Groceries)
##Groceries数据集的类型
typeof(Groceries)
##将S4类型转换为data.frame类型
cc <- as(Groceries,'data.frame')
##设置RGui的工作路径
setwd("G:\\myProject\\RDoc\\Unit1")
##导出Groceries数据集
write.csv(cc,"Groceries.csv") 2)选中groceries.R中的全部代码,点击工具栏上的
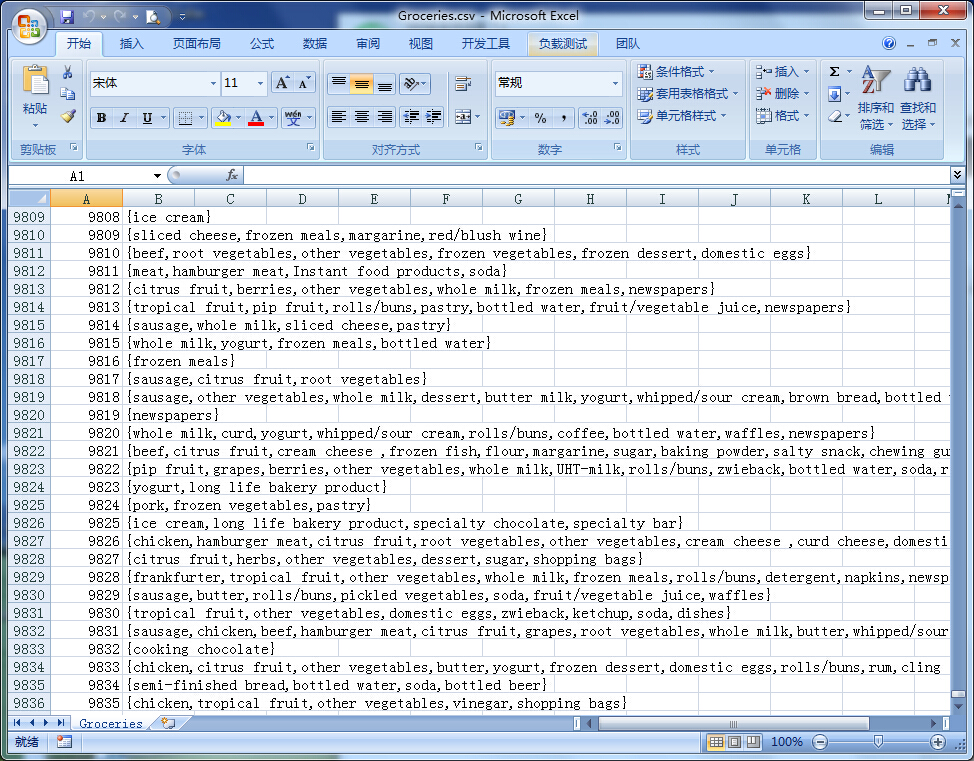
3)在G:\myProject\RDoc\Unit1目录,就得到了Groceries.csv数据集,效果如下:
Groceries数据集下载地址:
http://download.csdn.net/detail/sanqima/9301589
















 1471
1471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











