groupby
import pandas as pd
df = pd.DataFrame({'key1':list('aabba'),
'key2': ['one','two','one','two','one'],
'data1': np.random.randn(5),
'data2': np.random.randn(5)})
df
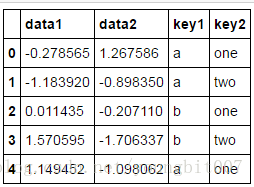
grouped=df['data1'].groupby(df['key1'])
grouped.mean()
以上的分组键均为Series,实际上分组键可以是任何长度适当的数组
states=np.array(['Ohio','California','California','Ohio','Ohio'])
years=np.array([2005,2005,2006,2005,2006])
df['data1'].groupby([states,years]).mean()

df.groupby('key1').mean()
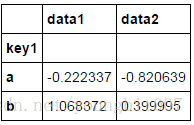
可以看出没有key2列,因为df[‘key2’]不是数值数据,所以被从结果中移除。默认情况下,所有数值列都会被聚合,虽然有时可能被过滤为一个子集。
对分组进行迭代
for name, group in df.groupby('key1'):
print (name)
print (group)
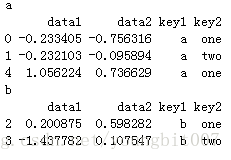
可以看出name就是groupby中的key1的值,group就是要输出的内容。
同理:
for (k1,k2),group in df.groupby(['key1','key2']):
print ('===k1,k2:')
print (k1,k2)
print ('===k3:')
print (group)

对group by后的内容进行操作,如转换成字典
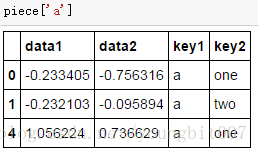
piece=dict(list(df.groupby('key1')))
piece
{'a': data1 data2 key1 key2
0 -0.233405 -0.756316 a one
1 -0.232103 -0.095894 a two
4 1.056224 0.736629 a one, 'b': data1 data2 key1 key2
2 0.200875 0.598282 b one
3 -1.437782 0.107547 b two}
piece['a']
groupby默认是在axis=0上进行分组的,通过设置也可以在其他任何轴上进行分组.
grouped=df.groupby(df.dtypes, axis=1)
dict(list(grouped))
{dtype('float64'): data1 data2
0 -0.233405 -0.756316
1 -0.232103 -0.095894
2 0.200875 0.598282
3 -1.437782 0.107547
4 1.056224 0.736629, dtype('O'): key1 key2
0 a one
1 a two
2 b one
3 b two
4 a one
选取一个或者一组列

对于大数据,很多情况是只需要对部分列进行聚合
df.groupby(['key1','key2'])[['data2']].mean()
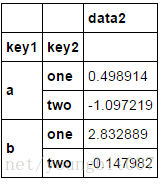
通过字典或者series进行分组
people=pd.DataFrame(np.random.randn(5,5),
columns=list('abcde'),
index=['Joe','Steve','Wes','Jim','Travis'])
people.ix[2:3,['b','c']]=np.nan #设置几个nan
people
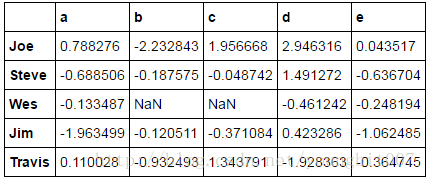
已知列的分组关系
mapping={'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'}
by_column=people.groupby(mapping,axis=1)
by_column.sum()
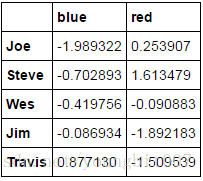
如果不加axis=1, 则只会出现 a b c d e
Series 也一样
map_series=pd.Series(mapping)
map_series
a red
b red
c blue
d blue
e red
f orange
dtype: object
people.groupby(map_series,axis=1).count()
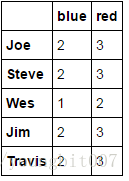
通过函数进行分组
相较于dic或者Series,python函数在定义分组关系映射时更有创意。任何被当做分组键的函数都会在各个索引上被调用一次,其返回值就会被用作分组名称。假设你按人名的长度进行分组,仅仅传入len即可
people.groupby(len).sum() a b c d e 3 -1.308709 -2.353354 1.585584 2.908360 -1.267162 5 -0.688506 -0.187575 -0.048742 1.491272 -0.636704 6 0.110028 -0.932493 1.343791 -1.928363 -0.364745
将函数和数组、列表、字典、Series混合使用也不是问题,因为任何东西都会最终转换为数组
key_list=['one','one','one','two','two'] people.groupby([len,key_list]).sum()
根据索引级别进行分组
层次化索引最方便的地方就在于他能够根据索引级别进行聚合。要实现该目的,通过level关键字出入级别编号或者名称即可:
columns=pd.MultiIndex.from_arrays([['US','US','US','JP','JP'],[1,3,5,1,3]],names=['cty','tenor'])
hier_df=pd.DataFrame(np.random.randn(4,5),columns=columns)
hier_df
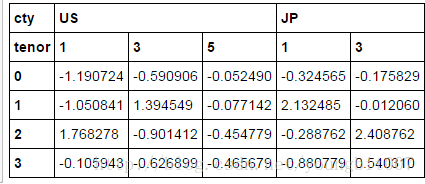
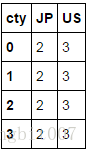
hier_df.groupby(level='cty',axis=1).count()
数据聚合
调用自定义的聚合函数

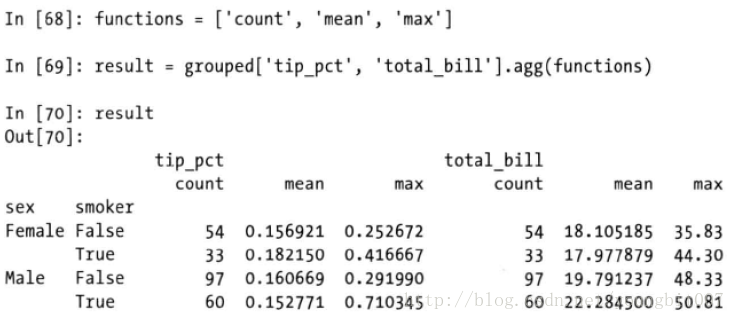
面向列的多函数应用
对Series或者DataFrame列的聚合运算实际是使用aggregate或者调用mean,std等方法。下面我们想对不同的列使用不同的聚合函数,或者一次应用多个函数
grouped=tips.groupby(['sex','smoker'])
grouped_pct=grouped['tip_pct']
grouped_pct.agg('mean')

自动给出的列名辨识度低,如果传入的是(name, function)元组组成的列表,则各个元组的第一个元素将被用作df的列名

对于df,可以定义一组用于全部列的函数,或在不同的列应用不同的函数
如果想对不同的列应用不同的函数, 具体的办法是想agg传入一个从列名映射到函数的字典

只有将多个函数应用到至少一列时,df才能拥有层次化的列
分组级运算和转换
聚合只是分组运算的一种,它是数据转换的特列。transform 和apply更牛叉.
transform会将一个函数应用到各个分组,然后将结果放在适当的位置. 如果各分组产生的标量值,则该标量值会被广播出去。
transform也是有严格条件的特殊函数:传入的函数只能产生两种结果,要么产生一个可以广播的标量值(如:np.mean), 要么产生一个相同大小的结果数组。
people=pd.DataFrame(np.random.randn(5,5),
columns=list('abcde'),
index=['Joe','Steve','Wes','Jim','Travis'])
people
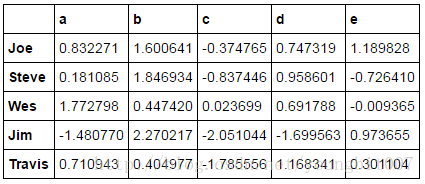
key=['one','two','one','two','one']
people.groupby(key).mean()
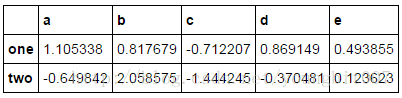
people.groupby(key).transform(np.mean)
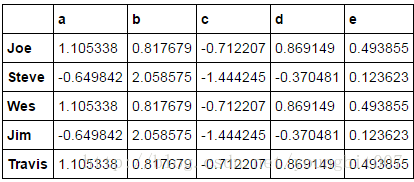
可以看到有很多与表2一样的值。
def demean(arr):
return arr-arr.mean()
demeaned=people.groupby(key).transform(demean)
demeaned
demeaned.groupby(key).mean()
最一般化的groupby 方法是apply.
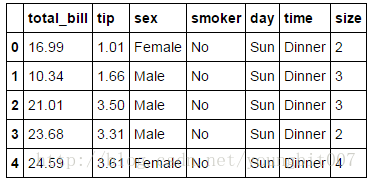
tips=pd.read_csv('C:\\Users\\ecaoyng\\Desktop\\work space\\Python\\py_for_analysis_code\\pydata-book-master\\ch08\\tips.csv')
tips[:5]
新生成一列
tips['tip_pct']=tips['tip']/tips['total_bill']
tips[:6]
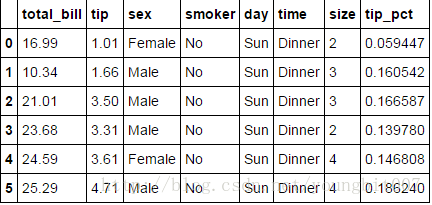
根据分组选出最高的5个tip_pct值
def top(df,n=5,column='tip_pct'):
return df.sort_index(by=column)[-n:]
top(tips,n=6)
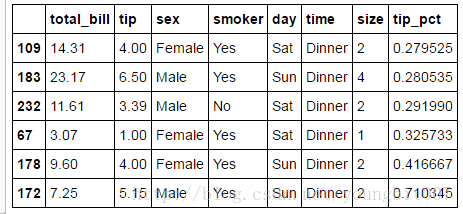
对smoker分组并应用该函数
tips.groupby('smoker').apply(top)
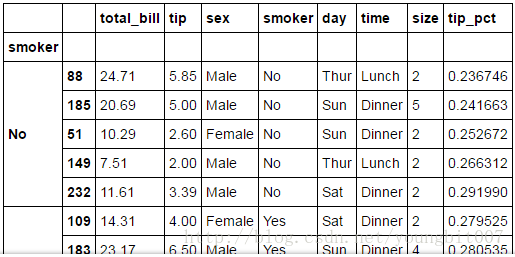
多参数版本
tips.groupby(['smoker','day']).apply(top,n=1,column='total_bill')
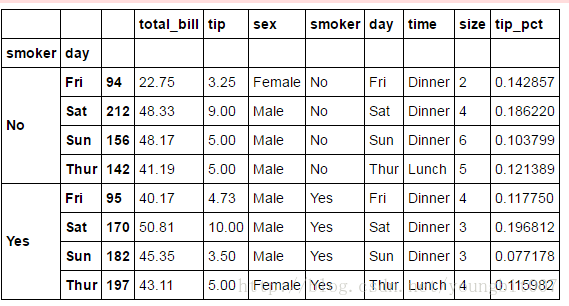
分位数和桶分析
cut and qcut与groupby结合起来,能轻松的对数据集的桶(bucket)或者分位数(quantile)分析。
frame=pd.DataFrame({'data1':np.random.randn(1000),
'data2': np.random.randn(1000)})
frame[:5]
factor=pd.cut(frame.data1,4)
factor[:10]
0 (0.281, 2.00374]
1 (0.281, 2.00374]
2 (-3.172, -1.442]
3 (-1.442, 0.281]
4 (0.281, 2.00374]
5 (0.281, 2.00374]
6 (-1.442, 0.281]
7 (-1.442, 0.281]
8 (-1.442, 0.281]
9 (-1.442, 0.281]
Name: data1, dtype: category
Categories (4, object): [(-3.172, -1.442] < (-1.442, 0.281] < (0.281, 2.00374] < (2.00374, 3.727]]
def get_stats(group):
return {'min':group.min(),'max':group.max(),'count':group.count(),'mean':group.mean()}
grouped=frame.data2.groupby(factor)
grouped.apply(get_stats).unstack()
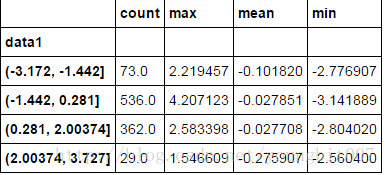
这些都是长度相等的桶,要根据样本分为数得到大小相等的桶,使用qcut即可.
长度相等的桶:区间大小相等
大小相等的桶:数据点数量相等
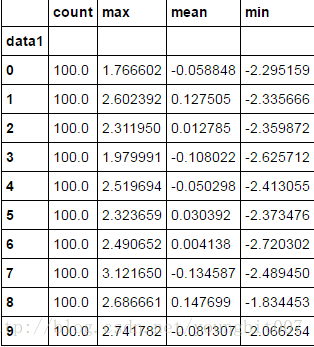
grouping=pd.qcut(frame.data1,10,labels=False)#label=false即可值获取分位数的编号
grouped=frame.data2.groupby(grouping)
grouped.apply(get_stats).unstack()




 本文介绍Pandas库中groupby方法的使用技巧,包括基于不同类型的键进行分组、迭代分组结果、转换分组内容及应用自定义函数进行数据聚合等高级用法。
本文介绍Pandas库中groupby方法的使用技巧,包括基于不同类型的键进行分组、迭代分组结果、转换分组内容及应用自定义函数进行数据聚合等高级用法。

















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









