







无论是做科学研究,还是工程项目,我们总是会碰上要比较字符串的相似性,比如拼写纠错、文本去重、上下文相似性等。度量的方法有很多,到底使用哪一种方法来计算相似性,这就需要我们根据情况选择合适的方法来计算。这里把几种常用到的度量字符串相似性的方法罗列一下,仅供参考,欢迎大家补充指正。
1、余弦相似性(cosine similarity)
余弦相似性大家都非常熟悉,它是定义在向量空间模型(VSM)中的。它的定义如下:
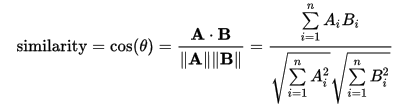
其中,A,B为向量中间中的两个向量。
在使用它来做字符串相似性度量的时候,需要先将字符串向量化,通常使用词袋模型(BOW)来向量化。举个例子如下:
String1 = “apple”
String2 = “app”
则词包为{’a’,’e’,’l’,’p’},若使用0,1判断元素是否在词包中,字符串1、2可以转化为:
StringA = [1111]
StringB = [1001]
那么,根据余弦公式,可以计算字符串相似性为:0.707。
2、欧氏距离(Euclidean distance)
欧氏距离大家非常熟悉,定义在向量空间模型中,计算使用欧氏距离公式:
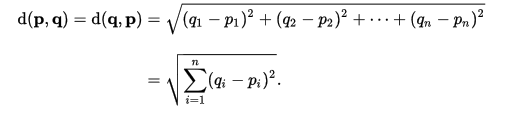
3、编辑距离(edit distance)
编辑距离,有的地方也会称为Levenshtein距离,表示从一个字符串转化为另一个字符串所需要的最少编辑次数,这里的编辑是指将字符串中的一个字符替换成另一个字符,或者插入删除字符。例如上例String1通过删除’l’与’e’转化为String2,所以其最小编辑次数为2。
编辑距离的核心就是如何计算出一对字符串间的最小编辑次数,考虑到问题的特点,我们可以使用动态规划的思想来计算其最小编辑次数,根据维基百科:两个字符串 a=a1a2⋯an,b=b1b2⋯bm 的编辑距离递归计算公式如下:
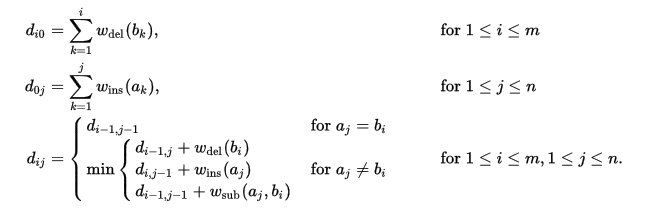
其中,w表示增删改三种操作的权重,一般定义为:
w={ 1,0,若有操作无操作
di0=i 表示从 b
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 845
845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









