









1、Non-linear hypotheses,引入课程中的一幅图片

对于图中的数据,只有俩个feature,分类效果尚能令人满意,但当feature数量不断增大时,假设函数中二次项数会剧增,比如feature为100时,此时二次项数为(100*100)/2=5000个
作者后面又举了一个识别汽车的例子,在一幅50*50像素的图片中,特征量能达到2500个,那么二次项就有(2500*2500)/2约3million个
所以对这些拥有大的feature数据,需要引入神经网络来表示假设函数。
2、Model Represent,从一个简单的神经元引入
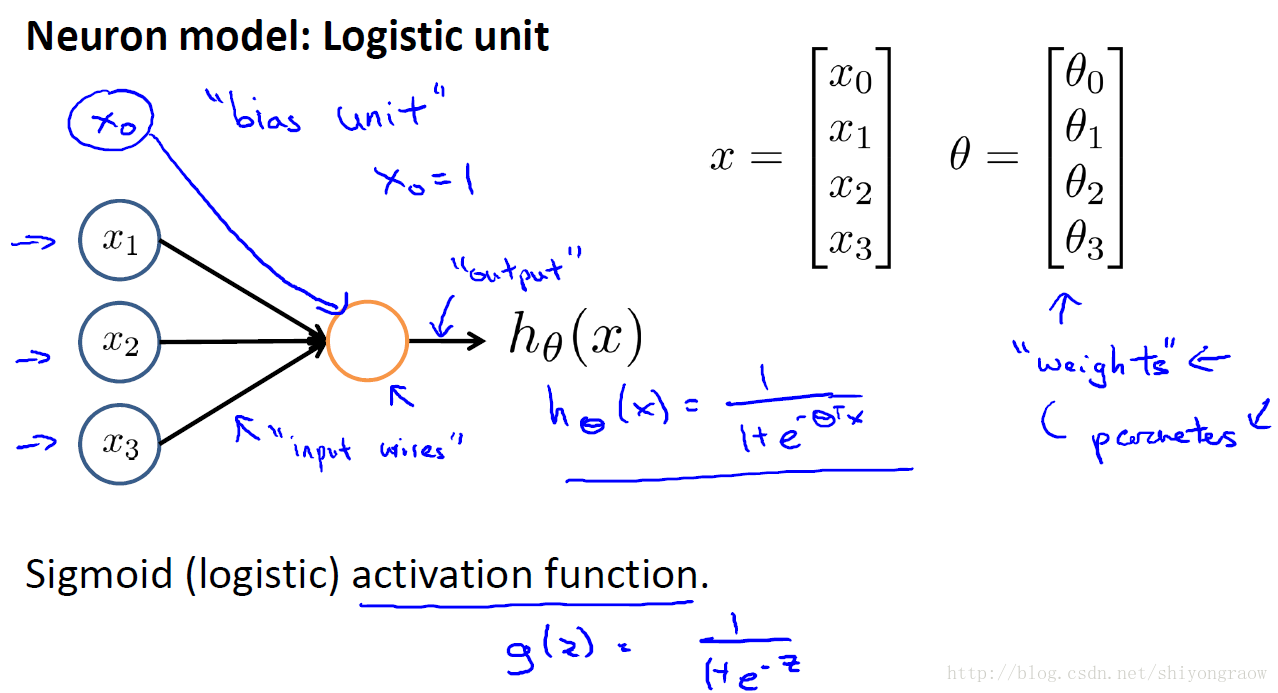
如图,有三个feature,将feature作为输入,同样加入x0并置1,这里我们称x0为偏置项(bias unit)。输入经过一个神经元,最后得到我们的假设函数,假设函数形式任然采用Sigmoid函数,在这里称Sigmoid函数为激活函数(activation function),也称theta为权值(weights)。
同样,当扩展到多个神经元时如下:
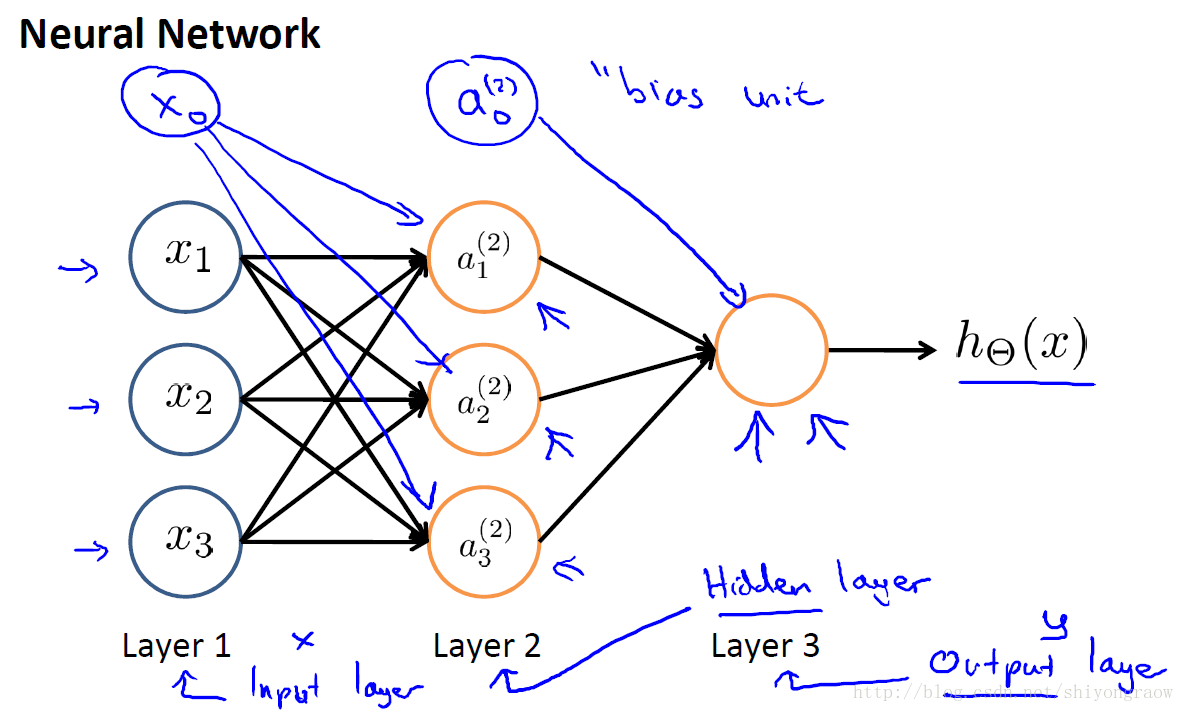
这里我们称layer1为输入层(input layer),layer3为输出层(output layer),介于layer1和layer3之间的为隐藏层(hidden layers),这里为layer2.同时,我们称隐藏层的结点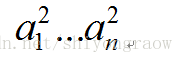
以一个具体神经网络为例解释计算过程:

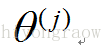
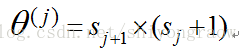
3、vectorized implementation(向量化表示)
以图中每个激活结点和假设函数的的具体计算过程为例。
我们引入变量Z并给出向量化实现:
以第二层为例,k表示结点序号,向量Z为:
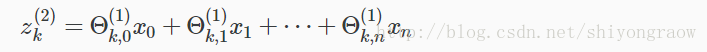
因为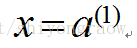

所以激活结点的向量化表示如下:

进一步化简

同时,也得到假设函数的向量化表示如下:
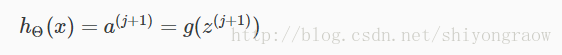














 1078
1078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









