







 本文介绍了一种基于深度学习的Deep Alignment Network(DAN)用于人脸关键点检测,它解决了视频中人脸关键点检测的抖动问题。DAN采用迭代处理框架,通过 Feed Forward NN 预测关键点位置,并使用Connection Layers计算相似变化矩阵以进行矫正。该方法适用于连续跟踪,源码基于Theano实现。
本文介绍了一种基于深度学习的Deep Alignment Network(DAN)用于人脸关键点检测,它解决了视频中人脸关键点检测的抖动问题。DAN采用迭代处理框架,通过 Feed Forward NN 预测关键点位置,并使用Connection Layers计算相似变化矩阵以进行矫正。该方法适用于连续跟踪,源码基于Theano实现。
人脸关键点检测的论文。速度略差,但想法不错。 视频中人脸关键点检测往往存在抖动,而常见的深度学习方法又不适合做连续跟踪。 本文提供了一个实现跟踪的思路。
文章链接: CVPR Workshop2017《Deep Alignment Network: A convolutional neural network for robust face alignment》
源码(Theano实现): https://github.com/MarekKowalski/DeepAlignmentNetwork
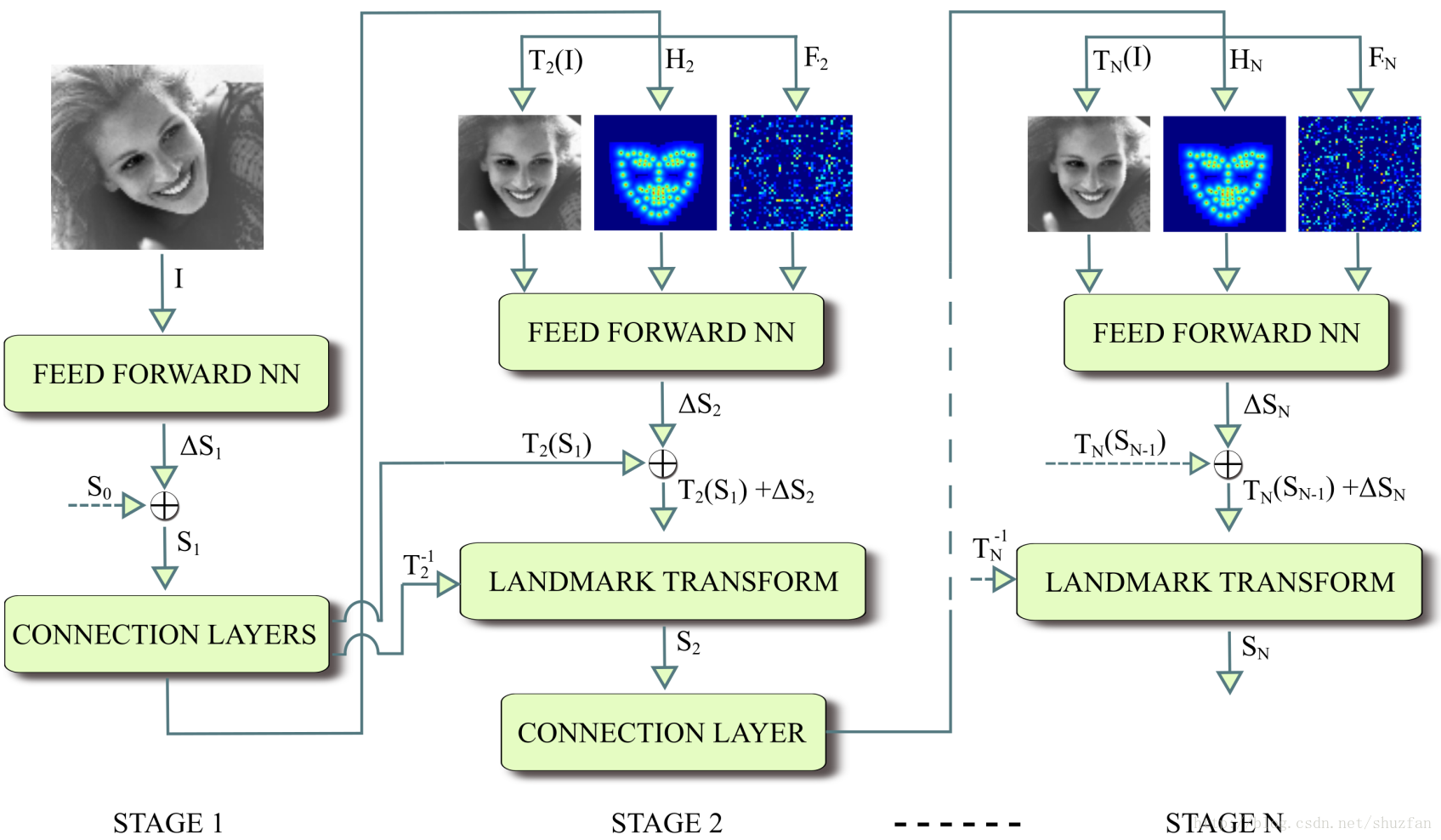
首先,可以明显看出是一个 迭代 处理的框架。 关键点检测流程如下:
(1)初始
输入灰度图 \(I\) 以及 标准关键点模板 \(S_0\),预测得到新的关键点位置 \(S_1\)。
其中“Feed Forward NN”<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









