







文章目录
本文是bilibili-《超系统学习Lucene全文检索技术》的学习笔记。
数据查询方法
顺序扫描法
数据表中查询包含某个字符串的文档,逐行逐字对比,对于每一个文档,需从头开始扫描待匹配的字段,直到找到目标字符串或扫描到文档末尾。
顺序扫描法,查询准确率高,但查询速度随着数据量增大,越来越慢。具体应用如数据库正则和like关键字模糊查询,又或者文档编辑器的ctrl+f查询。
倒排索引(全文检索过程使用倒排索引)
提前处理正文内容,如过滤特殊符号和特殊标签,进行切分词、去停词等,得到每一个文档的词、词位置、词频等信息,组成文档索引(相当于书本目录)。查询前先查询文档索引/目录,再获取对应文档。
索引不含重复词,中文检索系统中,索引大小有限,CPU可以通过索引定位到指定文档,查询速度非常快,查询速度基本不会随数据量的增加而增加。
倒排索引技术常用于海量数据模糊检索,如百度贴吧、百度搜索引擎等。
什么是Lucene
Lucene是一个开放源代码的全文检索引擎工具包,由apache软件基金会支持和提供,它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构。
Lucene的目的是为开发人员提供简单易用的全文检索工具,方便实现全文检索功能,或以此为基础建立起完整的全文检索引擎。
Lucene全文检索流程

绿色为索引过程,对要搜索的原始内容构建索引库,包括:获得文档、创建文档、分析文档和索引文档。 红色为搜索过程,从索引库中搜索内容,包括:查询接口、创建查询、执行查询和渲染结果。
索引流程
获得文档
爬虫获取互联网数据、JDBC获取数据库数据、IO流读取文档文件。
创建文档
建立索引前,需将原始内容创建成文档(Document),每一个文档有自己唯一标识ID,通过这个ID建立起词到文档的索引,所有文档组成文档集合。每个文档包括一个一个域/字段(Field),域中存储内容,key-value形式。
分析文档
将域中的内容进行分析,包括过滤、切分词、去停词、去特殊字符等,提取文档信息。
vivo X23 8GB+128GB 幻夜蓝 全网通4G手机
如elasticsearch的ik_max_word分词器:
vivo,x23,8GB,128GB,幻夜,幻夜蓝,全网,全网通,网通,4G,手机
索引文档
对所有文档分析得到的词汇单元汇总进行索引(有序排列),建立词汇到文档的索引关系。通过词汇查找文档,这种索引结构叫倒排索引结构。同一个词可能对应对个文档,多个文档有序存放在倒排表。
搜索流程
用户输入查询关键字执行搜索之前需要先构建一个查询对象,查询对象指定查询要查询的关键字、要搜索的Field文档域,查询对象生成具体地查询语法。
如搜索“华为手机”,创建查询对象 “name:华为 AND 手机”:表示搜索name中同时包含“华为”和“手机”的文档集合。
Lucene演示
索引过程
索引包括采集数据(从Mysql数据库读取数据),创建文档对象(原始数据转变为document对象),创建分词器、索引目录对象和输出流对象(使用标准分词器,中文按字分词),写入索引库。
由分词集合建立索引的过程在lucene底层实现。
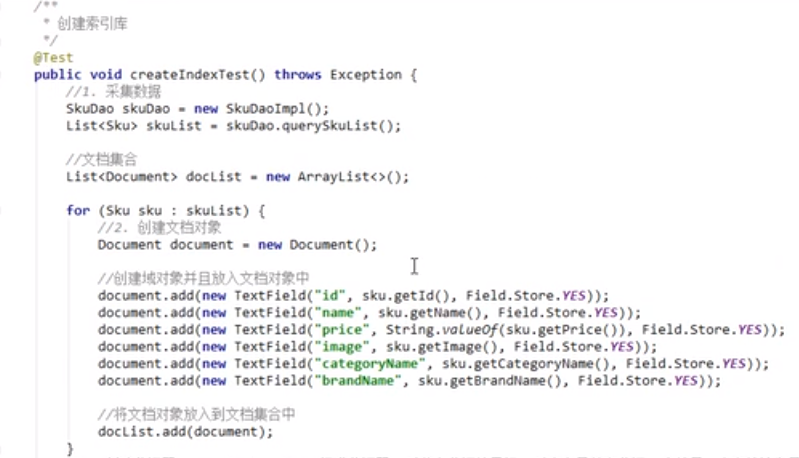

索引演示
中文按字分词,建立每个文档包含字的索引。

OR的形式查询“华为手机”,返回包含任意四个字的并集。

搜索过程


Field域类型
文档域包含域名和域值,Field值即为要索引的内容,也就是要搜索的内容。
| Field类 | 数据类型 | 是否分词 | 是否索引 | 是否存储 | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName, FieldValue, Store.Yes) | 字符串 | N | Y | Y或N | 字符串域不分词,整个字符串作为索引,如订单号、身份证号等 |
| FloatPoint(FieldName, FieldValue) | Float型 | Y | Y | N | 浮点域分词且索引,不存储 |
| IntPoint(FieldName, FieldValue) | Interger型 | Y | Y | N | 整数域分词且索引,不存储 |
| StoredField(FieldName, FieldValue) | 重载方法,支持多种类型 | N | N | Y | 用于构建不同类型Field,不分析、不索引,但要Field存储在文档中 |
| TextField(FieldName, FieldValue, Store.NO)或TextField(FieldName, reader) | 字符串或流 | Y | Y | Y或N | 如果是Reader,lucene猜测内容较多,会采用Unstored策略 |
只有一个默认选项的类型不能选择,含或的类型才能选择。
是否分词(tokenized)
- 是:对Field值分词,分词的目的是为了索引,索引的目的是为了查询,比如商品名称、商品描述等搜索内容丰富的域,用户需要通过关键字搜索,通过分词将语单元建立索引;
- 否:不对Field值分词,比如商品id、订单号、身份证号等;
是否索引(indexed)
- 是:进行索引,将Field分词后的词或整个Field值进行索引,存储到索引域,索引的目的是为了搜索,比如商品名称、商品描述需分析/分词后索引,订单号、身份证号不用分词也要索引,索引域将来都可以作为查询条件;
- 否:不索引。如图片路径,文件路径等,不用索引的域不支持查询;
是否存储(stored)
- 是:将Field值存储在文档域中,存储在文档域中的Field才能从document中获取,比如商品名称、订单号等,凡是需要从document中获取的field都需要存储,此外如商品链接、商品图片不需要索引和分词的域,如果需要从document中获取,也需要存储;
- 否:不存储,如商品描述比较大的域,如果需要返回不存储的字段,可以其他数据库获取;
对商品的字段进行具体分析:
- 商品id: StringField类型(不支持分词、默认索引),不分词、索引、存储(用于到其他数据库查询详细);
- 商品名称: TextFieldle类型,分词、索引、存储;
- 商品价格: IntPoint类型,分词(范围查询必须分词,底层算法实现)、索引、存储(配合StoredField实现存储);
- 商品地址: StoredField类型,不分词、不索引、存储;
- 商品分类: StringField类型,不分词(专有名词,可不分词)、索引、存储;
- 商品品牌名: StringField类型,不分词(专有名词,可不分词)索引、存储
索引维护
主文档存储在关系型数据库,索引库用于索引文档,文档的修改操作发生在关系型数据库,比如修改商品价格。为同步关系型数据库修改的信息到索引库,需进行索引库的维护。 索引维护主要包含索引的增、删、改、查。
分析器(Analyzer)
分词,将document中指定域的value切分为一个一个的词;过滤,去除特殊字符、停词等,大写转小写,词形还原(复数转单数、过去式转现在式等)等。同一域在索引和搜索时需使用相同的分词器。
Lucene原生分析器
1. StandardAnalyzer
标准分词器,包括分词(中文按字分词)、标准过滤、大小写过滤、停词过滤等。TokenFilter是分词过滤器,负责对雨汇单元进行过滤。

2. WhitespaceAnalyzer
仅仅按空格切分,不支持中文。
3. SimpleAnalyzer
将除字母以外的符号全部去除,并且将所有字母变为小写,会把数字去除,不支持中文。
4. CJKAnalyzer(中日韩分词器)
对中文执行二分法(2-gram)分词,去掉空格、去掉标点符号。
第三方中文分词器
IK-analyzer,该分词器支持Lucene 4.10,支持用户扩展词典(专有名词)、停词词典(不建立索引的词)。
Lucene高级搜索
// 创建查询对象,默认查询name域
Analyzer analyzer = new StandrdAnalyzer();
QueryParser queryParser = new QueryParser("name", analyser);
// 并列查询,默认OR查询
Query query = queryParser .parse("华为 AND 手机");
// 价格范围查询
Query query = queryParser .parse("price:[1 TO 99999]");
// 组合查询,省略。。。
Lucene底层储存结构(高级)
存储结构(倒排索引)包含:索引和文档集合。索引相当于字典目录,文档集合相当于字典正文。
一个索引由多个Segment组成,多个段可以合并,以减少磁盘IO。段有写锁,避免多线程同时写。段的修改是将原数据删除,在段尾添加新数据。
词典的构建
倒排索引中的词典位于内存,数据结构有很多种,Lucene 3.0之前使用跳跃表结构,后换成了FST,各数据结构对比
| 数据结构 | 优缺点 |
|---|---|
| 跳跃表 | 占用内存小,对模糊查询支持不好 |
| 排列列表 | 使用二分法查找,查询效率不平衡 |
| 字典树 | 查询效率和字符长度有关,只适合英文字典 |
| 哈希表 | 性能高,内存消耗大,几乎是原始数据的三倍 |
| 双数组字典树 | 适合中文词典,内存占用小,很多分词工具均采用此种算法 |
| 有限状态转换器(Finite State Transducers, FST) | Lucene 4有开源实现,并大量使用 |
| B树 | 磁盘索引,更新方便,但检索速度慢,多用于速度库 |
跳跃表原理
跳跃表是一种近似支持二分查找的有序链表,查询效率与跳表的级数有关,理想情况下查询平均时间复杂度为O(log n)。为什么不用红黑树而用跳表? 红黑树区间搜索性能低,跳表完美支持区间检索。

天下没有免费的午餐,跳跃是使用空间换时间,跳表的空间复杂度是O(2n)。
FST原理
Lucene现在采用的数据结构为FST,它的特点:
- 优点: 它内存占用低(公用前缀),压缩率一般在3倍至20倍之间,模糊查询的支持率好,查询快;
- 缺点: 结构复杂,输入要求有序,不易更新;
具体实现细节后面再研究。
Lucene优化(高级)
主要考虑优化索引创建效率和搜索效率。
解决大量磁盘IO
缓存区文档数:控制写入一个新的Segment前内存中保存的document的数目,设置较大数目可以加快建索引速度(批量写Segment),缓存文档数越多,对内存的消耗越大。
段文档数:设置N个文档合并为一个段。数值越大,建索引速度越快,搜索速度越慢,反之亦然。程序可利用并发机制在搜索时完成段的合并,因此段文档数越小,可利用的并发数可能越多。 实际应用过程中,应对程序进行不同值测试,选择最优的分段文档数。
选择合适的分词器
如IKAnalyzer分析器对中文支持好,但建索引速度和搜索速度都必StandardAnalyzer慢,因为需使用分词算法,而且得到的语汇数也会更多。
选择合适的位置存放索引库
文件系统、内存映射系统
Lucene相关度排序
Lucene对查询关键字和文档的相关度打分,得分高的就排在前面。具体地说,通过TF-IDF对搜索结果文档打分,假如查询语句被切分为5个词,以或的形式查询得到100篇文档,将每篇文档对5个词的TF-IDF值累加作为查询相关度得分,按分数逆序返回最终结果。
Lucene在多域检索时,可设定不同域的权重,影响最终的分数。















 1123
1123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









