






文章目录
- Models Corpus
- RoBERTa: A Robustly Optimized BERT Pretraining Approach
- ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
- DeBERTa: Decoding-enhanced BERT with Disentangled Attention
- DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing
Models Corpus

RoBERTa: A Robustly Optimized BERT Pretraining Approach
论文连接: https://arxiv.org/pdf/1907.11692.pdf
与BERT主要区别在于:
large mini-batches: 保持总训练tokens数一致,使用更大的学习率、更大的batch size,adam β 2 = 0.98 \beta_2=0.98 β2=0.98;dynamic masking: 动态掩盖,同一份样本重复10次;FULL-SENTENCES without NSP: 做了四种输入格式实验,验证了NSP任务的无效性,DOC-SENTENCES方式最优:- SEGMENT-PAIR+NSP: BERT输入类型,以一对文本段做了输入,文本段包含多句输入,总token数小于512;
- SENTENCE-PAIR+NSP: 以句对作为输入,总长度可能远小于512,增加batch size使得单批次总tokens数接近其它方法;
- FULL-SENTENCES:从单篇文章或多篇文章采样的连续句子,不同文章句采用特殊标记拼接,总长度最多512;
- DOC-SENTENCES: 从单篇文章采样的连续句子,总长度可能不足512,增加batch_size保持单批次总tokens数接近其它方法;
larger byte-level BPE: 使用更大词表的BPE,词表大小从30K提升至50K,无预处理步骤,无unknown token;
Byte-Pair Encoding (BPE)
A hybrid between character- and word-level representations that allows handling the large vocabularies common in natural language corpora.
Instead of full words, BPE relies on subwords units, which are extracted by performing statistical analysis of the training corpus.
Radford et al. (2019) introduce a clever implementation of BPE that uses bytes instead of unicode characters as the base subword units. Using bytes makes it possible to learn a subword vocabulary of a modest size (50K units) that can still encode any input text without introducing any “unknown” tokens.
ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
论文链接: https://arxiv.org/abs/2003.10555
释义: ELECTRA, “Efficiently Learning an Encoder that Classifies Token Replacements Accurately”.
主要贡献: 提出Replaced Token Detection (RTD)预训练任务,让判别器学习输入token是否被替换,与MLM预训练相比,消除了[MASK]在预训练与下游微调之间不统一的问题,此外,判别器学习输入中的每一个token,比MLM任务仅学习部分掩盖token更有效率。
如图1所示,同算力消耗下,RTD比MLM更高效:

RTD, Replaced Token Detection

同时训练生成器
G
G
G和判别器
D
D
D两个网络,每个网络都是一个Transformer Encoder,将输入tokens序列
x
=
[
x
1
,
.
.
.
,
x
n
]
\pmb x=[x_1, ..., x_n]
x=[x1,...,xn],编码为语义向量序列
h
(
x
)
=
[
h
1
,
.
.
.
,
h
n
]
h(\pmb x)=[h_1,...,h_n]
h(x)=[h1,...,hn]。
给定位置
t
t
t,令
x
t
=
[
MASK
]
x_t=[\text{MASK}]
xt=[MASK],生成器(MLM) 预测输出概率分布:
p
G
(
x
t
∣
x
)
=
exp
(
e
(
x
t
)
⊤
h
G
(
x
)
t
)
/
∑
x
′
exp
(
e
(
x
′
)
⊤
h
G
(
x
)
t
)
p_G(x_t|\pmb x)=\exp(e(x_t)^\top h_G(\pmb x)_t)/\sum_{x'}\exp(e(x')^\top h_G(\pmb x)_t)
pG(xt∣x)=exp(e(xt)⊤hG(x)t)/x′∑exp(e(x′)⊤hG(x)t)
式中
e
e
e表示token embeddings。对于位置
t
t
t,判别器判别该位置token来自于真实数据分布还是生成器预测分布,即是否被替换:
D
(
x
,
t
)
=
sigmoid
(
w
⊤
h
D
(
x
)
t
)
D(\pmb x, t)=\text{sigmoid}(w^\top h_D(\pmb x)_t)
D(x,t)=sigmoid(w⊤hD(x)t)
与GAN的区别在于,生成器以极大似然估计方式训练,不需要欺骗判别器。判别器梯度不反向传播至生成器,下游任务仅使用判别器。
生成器生成的token与原始token的语义接近,使用生成器预测序列作为判别器输入(更难区分),比随机替换token的方式更有效。
Weight Sharing
当判别器和生成器大小相同时,所有transformer参数均可以共享,但生成器参数量较少时训练更小效率,因此,仅共享token和position两种embedding参数。
表:GLUE在生成器和判别器共享参数下的性能
| 不共享参数 | 共享token embeddings | 共享全部参数 |
| 83.6 | 84.3 | 84.4 |
共享参数可带来性能微增,但却要求判别器和生成器模型结构一致!
Smaller Generators
若生成器和判别器大小一致,则单步迭代所需算力约是MLM模型的2倍,通过实验发现,当生成器大小为判别器大小的1/4至1/2时,判别器能够获得最优性能,可能是由于判别器难以应对过于强大的生成器,而且生成器建模数据分布,而判别器需要更多参数建模生成器。

Training Algorithms
两阶段训练算法步骤:
- 训练生成器n步;
- 使用生成器参数初始化判别器,冻结生成器参数,训练判别器n步;
如图3右图可见,两阶段训练的模型性能不如联合训练,对抗训练不如最大似然训练。对抗训练性能较低的原因可能在于,强化学习在大空间尺度上的样本采样性能差,导致对抗生成器在掩码语言建模上表现较差。
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
论文链接: https://arxiv.org/abs/2006.03654
DISENTANGLED SELF-ATTENTION
改进自注意力机制,将不同位置的内容向量和相对位置向量的cross attention分数作为自注意力分数:

标准自注意力机制:

引入相对位置的分散自注意力机制:

上述矩阵各行对应各位置的向量表示,其中:
- H , H o ∈ R N × d H,H_o\in\R^{N\times d} H,Ho∈RN×d,表示注意力层输入、输出隐状态;
- Q c , K c , V c Q_c,K_c,V_c Qc,Kc,Vc,表示经投影矩阵 W q , c , W k , c , W v , c ∈ R d × d W_{q,c}, W_{k,c}, W_{v,c}\in\R^{d\times d} Wq,c,Wk,c,Wv,c∈Rd×d,投影后的内容向量;
- P ∈ R 2 k × d P\in\R^{2k\times d} P∈R2k×d,表示相对位置嵌入,所有层共享;
- Q r , K r Q_r,K_r Qr,Kr,表示经投影矩阵 W q , r , W k , r ∈ R d × d W_{q,r},W_{k,r}\in\R^{d\times d} Wq,r,Wk,r∈Rd×d,投影后的相对位置向量;
- softmax \text{softmax} softmax,表示做行向量归一化,输出矩阵行向量为单位向量;
ENHANCED MASK DECODER ACCOUNTS FOR ABSOLUTE WORD POSITIONS
Given a sentence “a new store opened beside the new mall” with the words “store” and “mall” masked for prediction. Using only the local context (e.g., relative positions and surrounding words) is insufficient for the model to distinguish store and mall in this sentence, since both follow the word new with the same relative positions. For example, the subject of the sentence is “store” not “mall”. These syntactical nuances depend, to a large degree, upon the words’ absolute positions in the sentence.
语法上的细微差别,很大程度上取决于单词在句子中的绝对位置。
In DeBERTa, we incorporate them right after all the Transformer layers but before the softmax layer for masked token prediction, as shown in Figure 2. In this way, DeBERTa captures the relative positions in all the Transformer layers and only uses absolute positions as complementary information when decoding the masked words. Thus, we call DeBERTa’s decoding component an Enhanced Mask Decoder (EMD).
在所有transformers层之后、softmax之前,合并绝对位置信息,预测掩盖的token。

SCALE INVARIANT FINE-TUNING,SiFT
向标准化的word embeddings增加扰动,增强模型泛化性。
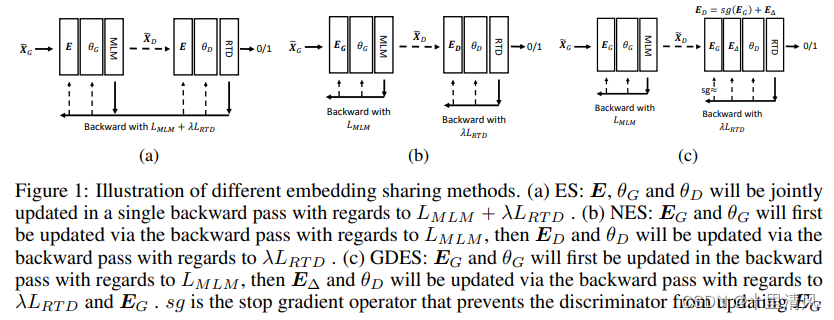
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing
论文链接: https://arxiv.org/abs/2111.09543
主要特点:
- 使用ELECTRA架构训练,以RTD代替MLM;
- 提出词向量梯度分散共享,优化生成器和判别器词向量共享,避免发生“tug-of-war”(激烈竞争);
DeBERTa with RTD
Replacing the MLM objective used in DeBERTa with the RTD objective.
Token Embedding Sharing in ELECTRA
The tasks of MLM and RTD pull token embeddings into very different directions. MLM tries to map the tokens that are semantically similar to the embedding vectors that are close to each other. RTD, on the other hand, tries to discriminate semantically similar tokens, pulling their embeddings as far as possible to optimize the classification accuracy.
使用不同词向量共享和梯度传播方式,词向量平均余弦相似度比较:

Gradient-Disentangled Embedding Sharing
The training of GDES follows that of NES. E Δ E_\Delta EΔ is initialized as a zero matrix. In each training pass:
- Run a forward pass with the generator to generate the inputs for the discriminator, and then run a backward pass with respect to the MLM loss to update E G E_G EG, which is shared by both the generator and the discriminator.
- Run a forward pass for the discriminator using the inputs produced by the generator, and run a backward pass with respect to the RTD loss to update ED by propagating gradients only through E Δ E_\Delta EΔ.
- After model training, E Δ E_\Delta EΔ is added to E G E_G EG and the sum is saved as E D E_D ED in the discriminator.















 1735
1735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









