









文章目录
梯度提升综述
梯度提升树的同义叫法:
- GBDT,Gradient Boosting Decision Tree,梯度提升决策树
- GBRT,Gradient Boosting Regression Tree,梯度回归树
- MART,Multiple Additive Regression Tree,多重累加回归树
GBDT是一种迭代的决策树算法,由多棵回归决策树组成,将所有决策树的输出累加作为最终输出.即
f
m
(
x
)
=
f
m
−
1
(
x
)
+
T
(
x
;
Θ
m
)
f_m(\bm x)=f_{m-1}(\bm x)+T(\bm x; \Theta_m)
fm(x)=fm−1(x)+T(x;Θm)
对于回归问题,若采用平方误差损失,则
L
(
y
,
f
m
−
1
(
x
i
)
+
T
(
x
i
;
Θ
m
)
)
=
[
y
−
f
m
−
1
(
x
)
−
T
(
x
;
Θ
m
)
]
2
=
[
r
−
T
(
x
;
Θ
m
)
]
2
L(y, f_{m-1}(\bm x_i)+T(\bm x_i;\Theta_m)) =[y-f_{m-1}(\bm x)-T(\bm x; \Theta_m)]^2 = [r-T(\bm x; \Theta_m)]^2
L(y,fm−1(xi)+T(xi;Θm))=[y−fm−1(x)−T(x;Θm)]2=[r−T(x;Θm)]2
其中
r
=
y
−
f
m
−
1
(
x
)
r=y-f_{m-1}(\bm x)
r=y−fm−1(x)是当前模型在训练集上的残差(实际值-预测值),每轮基模型的学习实际是在拟合当前模型的残差。
GBDT算法使用 负梯度近似残差,基模型的学习问题转变为拟合当前总体损失负梯度,使得各损失函数可用。Sklearn的GBDT实现,回归问题可选用MSE、MAE、Huber等损失,分类问题可选用Deviance(二分类对应于logistic、多分类对应于softmax)、Exponential损失。
GBDT优缺点:
- 采用决策树作为基模型,不需要特征标准化,数值缩放不影响分裂点,而且树形模型不通过梯度下降求解;
- 模型解释力强;
- 适用于不同的损失函数;
- 计算密集型,不能并行计算;
- 无法处理高纬稀疏特征的数据,如词袋特征的文本数据;
GBDT for Regression and Binary Classification
算法实现步骤:
-
初始化,将使损失函数极小的常数值作为初始值(MSE损失初值为均值):
H 0 ( x ) = arg min c E D [ L ( y , c ) ] = arg min c ∑ i w i L ( y i , c ) H_0(\boldsymbol x)=\arg\min_{c}\Bbb E_{\mathcal D}[L(y, c)]=\arg\min_c\sum_iw_iL(y_i,c) H0(x)=argcminED[L(y,c)]=argcmini∑wiL(yi,c) -
t t t,从1至T遍历:
-
将当前总体损失函数的负梯度作为本轮基模型拟合值:
g t = − [ ∂ L ( y , H ( x ) ) ∂ H ( x ) ] H ( x ) = H t − 1 ( x ) g_t=-\left[\dfrac{\partial L(y,H(\boldsymbol x))}{\partial H(\boldsymbol x)}\right]_{H(\boldsymbol x)=H_{t-1}(\boldsymbol x)} gt=−[∂H(x)∂L(y,H(x))]H(x)=Ht−1(x)回归任务一般使用MSE损失,分类任务一般使用Deviance损失(二分类和多分类对应于logistic和softmax).
-
使用CART决策树拟合 g t g_t gt,分类/回归任务均可使用MSE损失,对应结点输出均值:
h t ( x ) = arg min h E D [ ( g t − h ( x ) ) 2 ] = ∑ j = 1 J y ‾ j I ( x ∈ R j ) h_t(\boldsymbol x)=\arg\min_h\Bbb E_{\mathcal D}[(g_t-h(\boldsymbol x))^2] =\sum_{j=1}^J\overline y_j\Bbb I(\boldsymbol x\in R_j) ht(x)=arghminED[(gt−h(x))2]=j=1∑JyjI(x∈Rj) -
搜索最优步长 α t \alpha_t αt(sklearn使用固定值learning_rate),组合基模型
H t ( x ) = H t − 1 ( x ) + α t h t ( x ) , α t = arg min α E D [ L ( y , H t − 1 ( x ) + α h t ( x ) ) ] , H_t(\boldsymbol x)=H_{t-1}(\boldsymbol x)+\alpha_th_t(\boldsymbol x),\quad\alpha_t=\arg\min_{\alpha}\Bbb E_{\mathcal D}[L(y,H_{t-1}(\boldsymbol x)+\alpha h_t(\boldsymbol x))], Ht(x)=Ht−1(x)+αtht(x),αt=argαminED[L(y,Ht−1(x)+αht(x))],
-
-
迭代结束,最终模型为:
H ( x ) = H 0 ( x ) + ∑ t = 1 T α t h t ( x ) H(\boldsymbol x)=H_0(\boldsymbol x)+\sum_{t=1}^T\alpha_th_t(\boldsymbol x) H(x)=H0(x)+t=1∑Tαtht(x)
GBDT for K-class Classification
算法实现步骤:
-
初始化,各目标函数值初值为0, f k 0 ( x ) = 0 f_{k0}(\boldsymbol x)=0 fk0(x)=0;
-
t t t,从1至T遍历:
-
k k k,从1至K遍历:
-
将当前类别总体损失的负梯度作为本轮拟合值,若使用Deviance损失,则:
g t k = y k − exp ( f t − 1 , k ( x ) ) ∑ l = 1 K exp ( f t − 1 , l ( x ) ) g_{tk}=y_k-\frac{\exp(f_{t-1,k}(\boldsymbol x))}{\sum_{l=1}^K\exp(f_{t-1,l}(\boldsymbol x))} gtk=yk−∑l=1Kexp(ft−1,l(x))exp(ft−1,k(x)) -
拟合CART回归树:
h t k ( x ) = arg min h E D [ ( g t k − h t k ( x ) ) 2 ] h_{tk}(\boldsymbol x)=\arg\min_h\Bbb E_{\mathcal D}[(g_{tk}-h_{tk}(\boldsymbol x))^2] htk(x)=arghminED[(gtk−htk(x))2] -
根据最优步长 α t k \alpha_{tk} αtk组合基模型:
f t k ( x ) = f t − 1 , k ( x ) + α t k h t k ( x ) f_{tk}(\boldsymbol x)=f_{t-1,k}(\boldsymbol x)+\alpha_{tk}h_{tk}(\boldsymbol x) ftk(x)=ft−1,k(x)+αtkhtk(x)
-
-
-
迭代结束得K个模型,第k个模型:
f k ( x ) = ∑ t = 1 T α t k h t k ( x ) f_k(\boldsymbol x)=\sum_{t=1}^T\alpha_{tk}h_{tk}(\boldsymbol x) fk(x)=t=1∑Tαtkhtk(x)
实例1:GBDT预测波士顿房价
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
dataset = load_boston()
features = dataset.feature_names
X_train, X_test, y_train, y_test = train_test_split(
dataset.data, dataset.target, train_size=0.9, test_size=0.1, random_state=188)
gbr = GradientBoostingRegressor(
loss='ls',
learning_rate=0.1,
n_estimators=500,
max_depth=4,
min_samples_split=2,
verbose=1)
gbr.fit(X_train, y_train)
plt.scatter(y_test, gbr.predict(X_test))
plt.xlabel('True Values [Bostion House Price]')
plt.ylabel('Predictions [Bostion House Price]')
# plt.axis('equal')
# plt.axis('square')
plt.xlim([0, plt.xlim()[1]])
plt.ylim([0, plt.ylim()[1]])
plt.plot([-100, 100], [-100, 100], 'r')
plt.show()
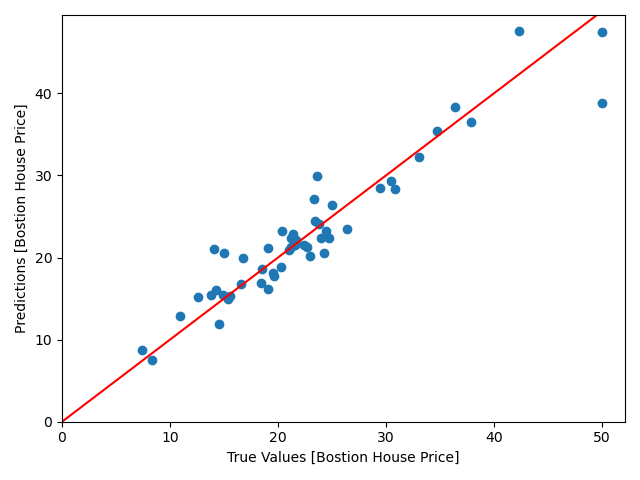
模型预测效果图如下,离直线越近的点,拟合越好:
实例2:GBDT预测鸢尾花类别
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.model_selection import train_test_split
dataset = load_iris()
features = dataset.feature_names
X_train, X_test, y_train, y_test = train_test_split(
dataset.data, dataset.target, train_size=0.8, test_size=0.2, random_state=188)
gbc = GradientBoostingClassifier(
loss='deviance',
learning_rate=0.1,
n_estimators=200,
max_depth=4,
min_samples_split=2,
verbose=1)
gbc.fit(X_train, y_train)
y_pred = gbc.predict(X_test)
report = classification_report(y_test, gbc.predict(X_test), output_dict=False)
print(report)
sns.heatmap(confusion_matrix(y_test, y_pred), annot=True, robust=True)
plt.show()
预测分类报告
precision recall f1-score support
0 1.00 1.00 1.00 11
1 0.83 1.00 0.91 5
2 1.00 0.93 0.96 14
accuracy 0.97 30
macro avg 0.94 0.98 0.96 30
weighted avg 0.97 0.97 0.97 30
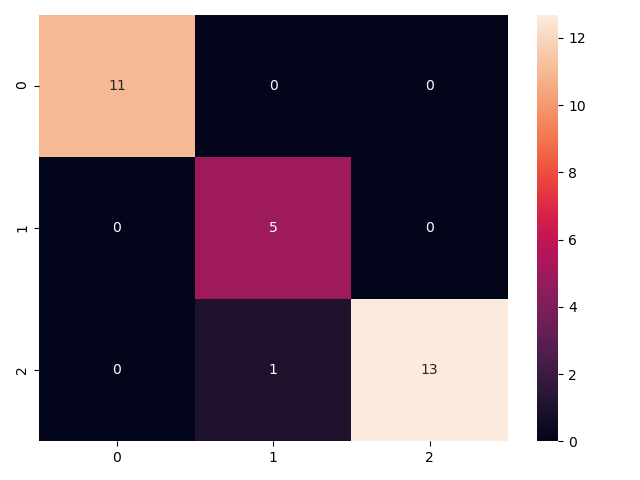
预测分类混淆矩阵















 1026
1026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









