







上一篇博客 Spatial Transformer Networks论文笔记(一)——仿射变换和双线性插值介绍了仿射变换和双线性插值,为更好地理解STN打基础。本篇博客是记录的是阅读原文Spatial Transformer Networks的一些笔记。
摘要
卷积神经网络(CNN)定义了一个非常强大的分类模型,但仍然受限于缺乏在计算和参数效率上对输入数据空间不变性的能力。本文我们引入一种欣的学习模块Spatial transformer(ST),它让网络明确地利用了数据的空间信息。这种可导的模块可以插入到现有的卷积结构中,赋予网络在不需要额外训练监督或者修改优化过程的情况下,基于特征图本身进行空间变换的能力。我们展示了空间变换网络的利用让模型学习了对平移、尺度变换、旋转和更多常见的扭曲的不变性,这也使得模型在一些基准数据集和变换分类上效果最好。
Spatial Transformers
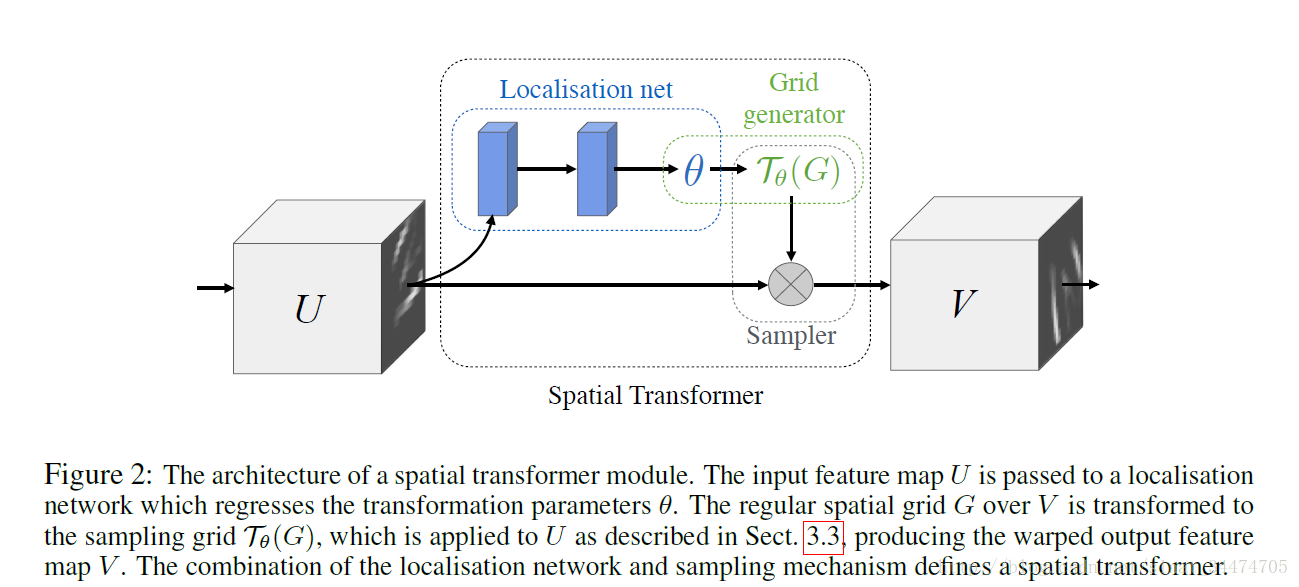
ST的结构如上图,它分成三部分,分别为Localisation Net, Grid Generator和Sampler,它完成的是一个将输入特征图进行一定的变换的过程,而具体如何变换,是通过在训练过程中学习来的,更通俗地将,该模块在训练阶段学习如何对输入数据进行变换更有益于模型的分类,然后在测试阶段应用已经训练好的网络对输入数据进行执行相应的变换,从而提高模型的识别率。下面具体介绍ST的三个部分。
Localisation Network
Localisation Network的输入是特征图 U U ,输出是变换参数,即 θ=floc(U) θ = f l o c ( U ) ,该层的结构通常是一个全连接网络或者卷积网络后接一个回归层来训练参数 θ θ 。 θ θ 的规模取决于具体的变换,当变换取二维仿射变换时, θ θ 是一个6维(2*3)的向量。
Grid Generator
该层利用Localisation 层输出的变换参数
θ
θ
,将输入的特征图进行变换,以仿射变换为例,这里就需要上一篇博客里介绍的双线性插值了,即输出特征图上某一位置
(xti,yti)
(
x
i
t
,
y
i
t
)
根据变换参数
θ
θ
映射到输入特征图上某一位置
(xsi,ysi)
(
x
i
s
,
y
i
s
)
,具体如下:
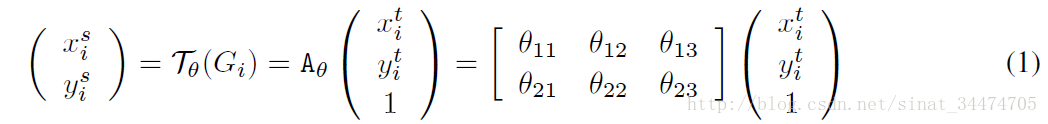
但此时往往
(xsi,ysi)
(
x
i
s
,
y
i
s
)
会落在原始输入特征图的几个像素点中间部分,所以需要利用双线性插值来计算出对应该点的灰度值。需要补充的是,文中在变幻时用都都是标准化坐标,即
xi,yi∈[−1,1]
x
i
,
y
i
∈
[
−
1
,
1
]
。(如果不太理解仿射变换和双线性插值,可以参考我的上一篇博客 Spatial Transformer Networks论文笔记(一)——仿射变换和双线性插值),文中给出了该层两个例子,如下图:

Sampler
在讲过上面两个部分后,我们可以知道,对于输出特征图上的每一个点,都可以和输入特征图上的某些像素点灰度值建立具体的联系,具体表示成如下公式:
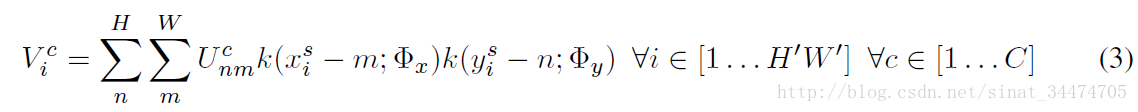
上式中,
Vci
V
i
c
为输出特征图上第
c
c
个通道某一点的灰度值,为输入特征图上第
c
c
个通道点的灰度值,该点的灰度是由某种插值方法确定,
k()
k
(
)
为具体的采样核,它定义了输入和输出特征图的重要关系。可以这样理解:(1)输出特征图上某一点
Vci
V
i
c
的灰度对应于输入特征图上某一点
(xsi,ysi)
(
x
i
s
,
y
i
s
)
的灰度值,而这点的灰度值由周围的若干点的灰度值
Ucnm
U
n
m
c
共同确定并且距离
(xsi,ysi)
(
x
i
s
,
y
i
s
)
越近(距离关系由
xsi−m
x
i
s
−
m
和
ysi−m
y
i
s
−
m
确定),影响越大(权重越大);(2)具体的灰度插值方法由
k()
k
(
)
中
Φx
Φ
x
和
Phiy
P
h
i
y
确定。当采用双线性插值方法时,公式如下:
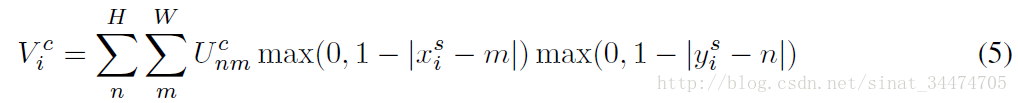
与公式(3)不同的是,(5)中定义的双线性插值使得目标灰度值只与
(xsi,ysi)
(
x
i
s
,
y
i
s
)
周围4个点的灰度有关。具体来说,当
|xsi−m|
|
x
i
s
−
m
|
或者
|ysi−m|
|
y
i
s
−
m
|
大于1时,对应的
max()
m
a
x
(
)
项将取0,也就是说,只有
(xsi,ysi)
(
x
i
s
,
y
i
s
)
周围4个点的灰度值决定目标像素点的灰度并且当
1−|xsi−m|
1
−
|
x
i
s
−
m
|
和
1−|ysi−m|
1
−
|
y
i
s
−
m
|
越小,影响越大(即离点
(xsi,ysi)
(
x
i
s
,
y
i
s
)
)越近,权重越大,这和我们上一篇博客介绍双线性插值的结论是一致的。
另外很重要的一点是,公式(5)对
Ucnm
U
n
m
c
和
(xsi,ysi)
(
x
i
s
,
y
i
s
)
是可导的,也就是说,ST的变换过程是可以在网络中不断训练来修正参数的。具体的求导结果论文中都有,就不再赘述了。
总结
本文主要是简单记录了STN的基本结构和原理,论文中还有很多细节(比如关于空间不变性的一些其他研究和具体的实验),这里就不再细说了,有兴趣的同学可以看论文。还有,在查阅这一块的资料时,看到贴吧里有一些关于STN的讨论,有兴趣的戳这里百度贴吧关于STN的讨论














 1626
1626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









