







 本文介绍了MapReduce的基础概念及其在大规模数据处理中的应用。通过对比函数式编程中的Map和Reduce操作,阐述了MapReduce如何解决分布式计算中的数据划分、调度、故障恢复及通信同步等问题。
本文介绍了MapReduce的基础概念及其在大规模数据处理中的应用。通过对比函数式编程中的Map和Reduce操作,阐述了MapReduce如何解决分布式计算中的数据划分、调度、故障恢复及通信同步等问题。
本文将随着研究的深入,不断更新。
说起MapReduce,自然会想到从google弄到奠基性的那篇论文,英文版链接 以及中文版链接 ,不过光看论文也够吃力,一些科普性的介绍应该首先关注关注。如孟岩的一篇MapReduce-the free lunch is not over 。还有wiki的翻译
我们从Jimmy Lin的角度去理解MapReduce。
首先,说起MapReduce不得不提及Functional Programming。Jimmy Lin认为MapReduce=functional programming meets distributed processing。首先一个概念是Higher-order Functions,即是吧其他函数作为参数的函数。如Schema中:
那么这和MapReduce有什么关系呢。首先函数式编程都是基于list的操作,那么在函数式编程中有两个重要的概念:
Map: do something to everything in a list
Fold/Reduce: combine results of a list in some way
其中Map是一个 Higher-order Function,该操作将应用于list中的每一个元素,如下图:
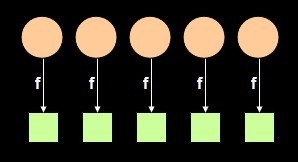
Map
举例如下:
Fold/Reduce也是一个Higher-order Function,通过某种方式将map后新的list合并在一起,如下图:
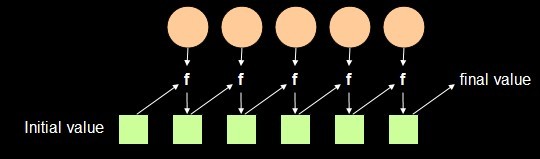
Fold/Reduce
举例如下:
如果我们假设有一条很长很长的list,我们希望将map操作并行化,我们希望将map操作的结果合并起来,那么我们就引入了MapReduce。
在umd云计算之简述 一文中,我们将所有计算归结为Divide and conquer,这一思想在MapReduce中体现的很清楚,如图:
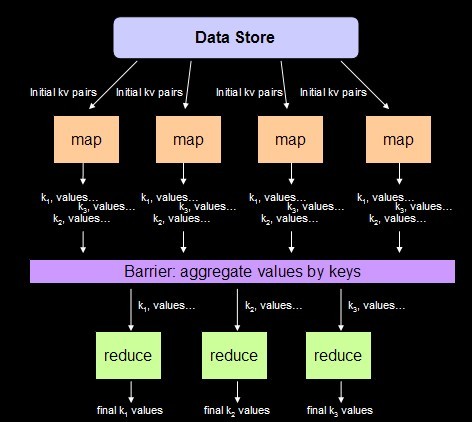
MapReduce
现在我们进入MapReduce: Simplified Data Processing on Large Clusters这篇论文。
首先,MapReduce runtime处理了一下几个方面的问题:
1. partitioning the input data
2. scheduling
3. handling machine failures
4. managing inter-machine communication to handle the synchronization
这四个问题基本涵盖了分布式系统基本内容。
其次,google的MapReduce实现的基本原理如下:
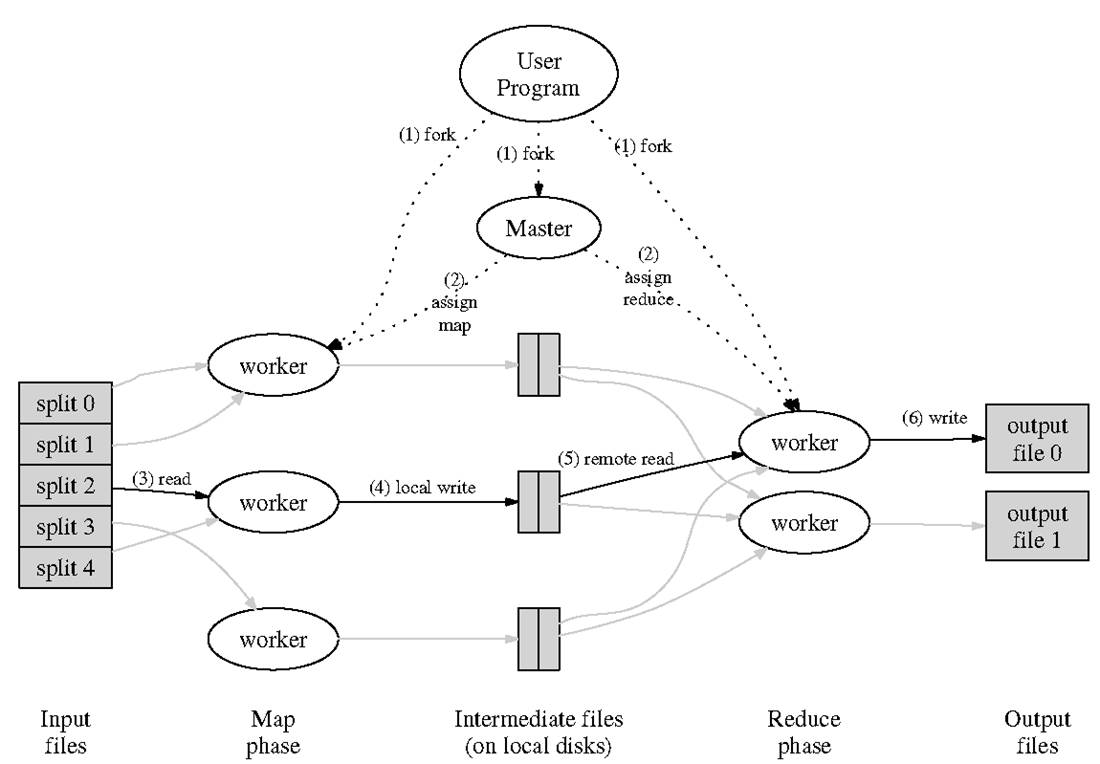
Implementation
我们一步步的分析上图中的步骤(摘自paper):
1. 用户程序中的MapReduce函数库首先把输入文件分成M块,每块大概16M到64M(可以通过参数决定)。接着在cluster的机器上执行处理程序。
2. 这些分排的执行程序中有一个程序比较特别,它是主控程序master。剩下的执行程序都是作为master分排工作的worker。总共有M个map任务和R个reduce任务需要分排。master选择空闲的worker并且分配这些map任务或者reduce任务
3. 一个分配了map任务的worker读取并处理相关的输入小块。他处理输入的数据,并且将分析出的key/value对传递给用户定义的map函数。map函数产生的中间结果key/value对暂时缓冲到内存。
4. 这些缓冲到内存的中间结果将被定时刷写到本地硬盘,这些数据通过分区函数分成R个区。这些中间结果在本地硬盘的位置信息将被发送回master,然后这个master负责把这些位置信息传送给reduce的worker。
5. 当master通知reduce的worker关于中间key/value对的位置时,他调用remote procedure来从map worker的本地硬盘上读取缓冲的中间数据。当reduce的worker读到了所有的中间数据,他就使用中间key进行排序,这样可以使得相同key的值都在一起。因为有许多不同key的map都对应相同的reduce任务,所以,排序是必须的。如果中间结果集太大了,那么就需要使用外排序。
6. reduce worker根据每一个唯一中间key来遍历所有的排序后的中间数据,并且把key和相关的中间结果值集合传递给用户定义的reduce函数。reduce函数的对于本reduce区块的输出到一个最终的输出文件。
7. 当所有的map任务和reduce任务都已经完成了的时候,master激活用户程序。在这时候MapReduce返回用户程序的调用点。















 5622
5622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









