









 本文详细介绍了Hadoop-2.4.1中的InputFormat,包括其作用、逻辑InputSplit和RecordReader的职责。重点讨论了FileInputFormat及其子类,如TextInputFormat、SequenceFileInputFormat等,并解释了如何处理记录跨InputSplit的情况。InputFormat的子类如DBInputFormat、ComposableInputFormat和CompositeInputFormat也进行了简要描述。
本文详细介绍了Hadoop-2.4.1中的InputFormat,包括其作用、逻辑InputSplit和RecordReader的职责。重点讨论了FileInputFormat及其子类,如TextInputFormat、SequenceFileInputFormat等,并解释了如何处理记录跨InputSplit的情况。InputFormat的子类如DBInputFormat、ComposableInputFormat和CompositeInputFormat也进行了简要描述。
向Hadoop集群提交作业时,需要指定作业输入的格式(未指定时默认的输入格式为TextInputFormat)。在Hadoop中使用InputFormat类或InputFormat接口描述MapReduce作业输入的规范或者格式,之所以说InputFormat类或InputFormat接口是因为在旧的API(hadoop-0.x)中InputFormat被定义为接口,而在新的API(hadoop-1.x及hadoop-2.x)中,InputFormat是做为抽象类存在的,在本篇文章中主要讲述InputFormat抽象类及其子类。InputFormat主要用于验证作业的输入是否符合规范,将输入文件分割为逻辑InputSplit,每个InputSplit被分配给一个Mapper任务,提供RecordReader的实现,该实现负责从InputSplit中收集记录交由Mapper任务处理。不同的InputFormat子类提供了不同的InputSplit和RecordReader,比如用于文件的FileSplit和用于数据库的DBInputSplit,用于文本文件的LineRecordReader和Sequence文件的SequenceFileRecordReader等。下图为InputFormat及其子类关系图:
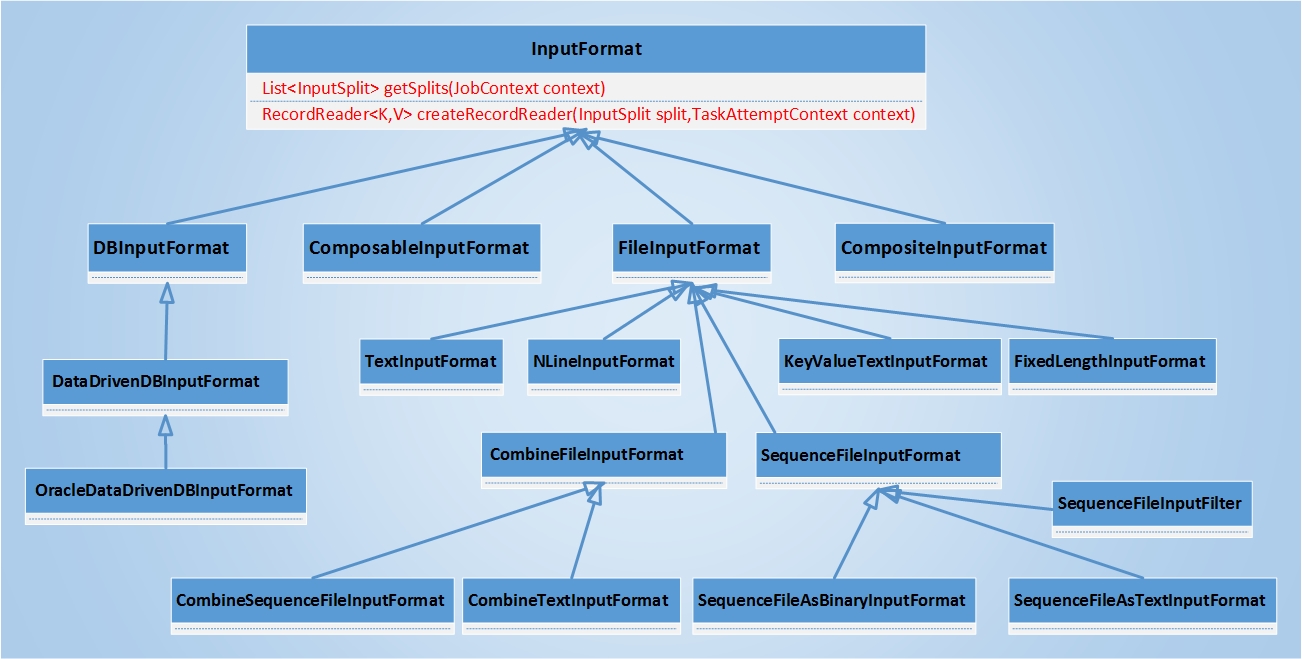
InputFormat抽象类只提

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 3248
3248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











