







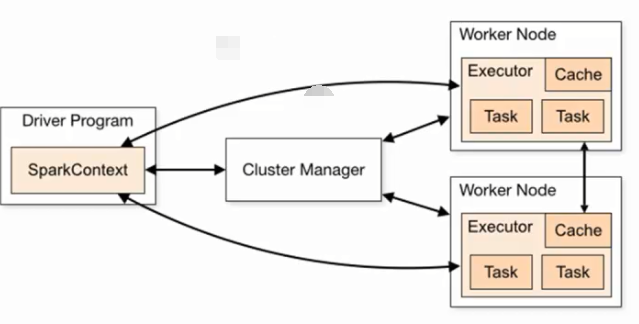
基本概念介绍:
Driver : 是用户编写的数据处理逻辑,这个逻辑包含用户创建的SparkContext
SparkContext:是用户逻辑与Spark集群主要的交互接口,它会和Cluster Manager进行交互,负责计算资源的申请等。
Cluster Manager:资源管理器,负责集群资源的管理和调度,支持的有:Standalone,Mesos和YARN。也可以不需要它
比如运行在本地模式(local)主要是做调试工作。
Work Node:是集群中具体每台计算机中的计算资源和存储资源的一种代表。
Executor:是在一个Worker Node上为某应用启动的一个进程,该进程里面会通过线程池的方式负责运行任务,并负责将数据存在内存或者磁盘上。
Spark会将Driver中的任务提交给Executor中,具体的计算是发生在Executor上,调用线程,在线程池用运行计算,每个任务都会有独立的Executor计算。
上述图是spark架构设计,今天来分析用户程序从最开始的提交到最终的计算执行所需要的几个阶段:
1)用户程序会创建一个SparkContext,新创建的SparkContext会根据用户在编程的时候设置的参数,或者是系统默认的配置连接到Cluster Manager上,
Cluster Manager会根据用户提交时设置的CPU和内存等信息,来为本次程序分配计算资源,启动Executor.
2)Driver会将用户提交来的程序进行Stage级别的划分(其实也就是高层调度器),高层
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









