




 本文详细梳理了增强学习中的TD(时间差分)方法,包括TD与MC的不同,TD算法的原理,如SARSA和Q-Learning,以及Double Q-Learning。TD方法优势在于在线学习和广泛的应用范围,尽管存在估计偏差,但通过迭代可收敛。此外,文章探讨了这些算法如何基于Bellman方程进行优化。
本文详细梳理了增强学习中的TD(时间差分)方法,包括TD与MC的不同,TD算法的原理,如SARSA和Q-Learning,以及Double Q-Learning。TD方法优势在于在线学习和广泛的应用范围,尽管存在估计偏差,但通过迭代可收敛。此外,文章探讨了这些算法如何基于Bellman方程进行优化。
1 前言
在上一篇blog中,我们分析了蒙特卡洛方法,这个方法的一个特点就是需要运行完整个episode从而获得准确的result。但是往往很多场景下要运行完整个episode是很费时间的,因此,能不能还是沿着bellman方程的路子,估计一下result呢?并且,注意这里,依然model free。那么什么方法可以做到呢?就是TD(temporal-difference时间差分)方法。
有个名词注意一下:boostraping。所谓boostraping就是有没有通过估计的方法来引导计算。那么蒙特卡洛不使用boostraping,而TD使用boostraping。
接下来具体分析一下TD方法
2 TD与MC的不同

MC使用准确的return来更新value,而TD则使用Bellman方程中对value的估计方法来估计value,然后将估计值作为value的目标值进行更新。
也因此,估计的目标值的设定将衍生出各种TD下的算法。
那么TD方法的优势有什么呢?
- 每一步都可以更新,这是显然,也就是online learning,学习快
- 可以面对没有结果的场景,应用范围广
不足之处也是显而易见的,就是因为TD target是估计值,估计是有误差的,这就会导致更新得到value是有偏差的。很难做到无偏估计。但是以此同时,TD target是每一个step进行估计的,仅最近的动作对其有影响,而MC的result则受到整个时间片中动作的影响,因此TD target的方差variance会比较低,也就是波动性小。
还是放一下David Silver的总结吧:

那么David Silver的ppt中有三张图,很清楚的对比了MC,TD以及DP的不同:
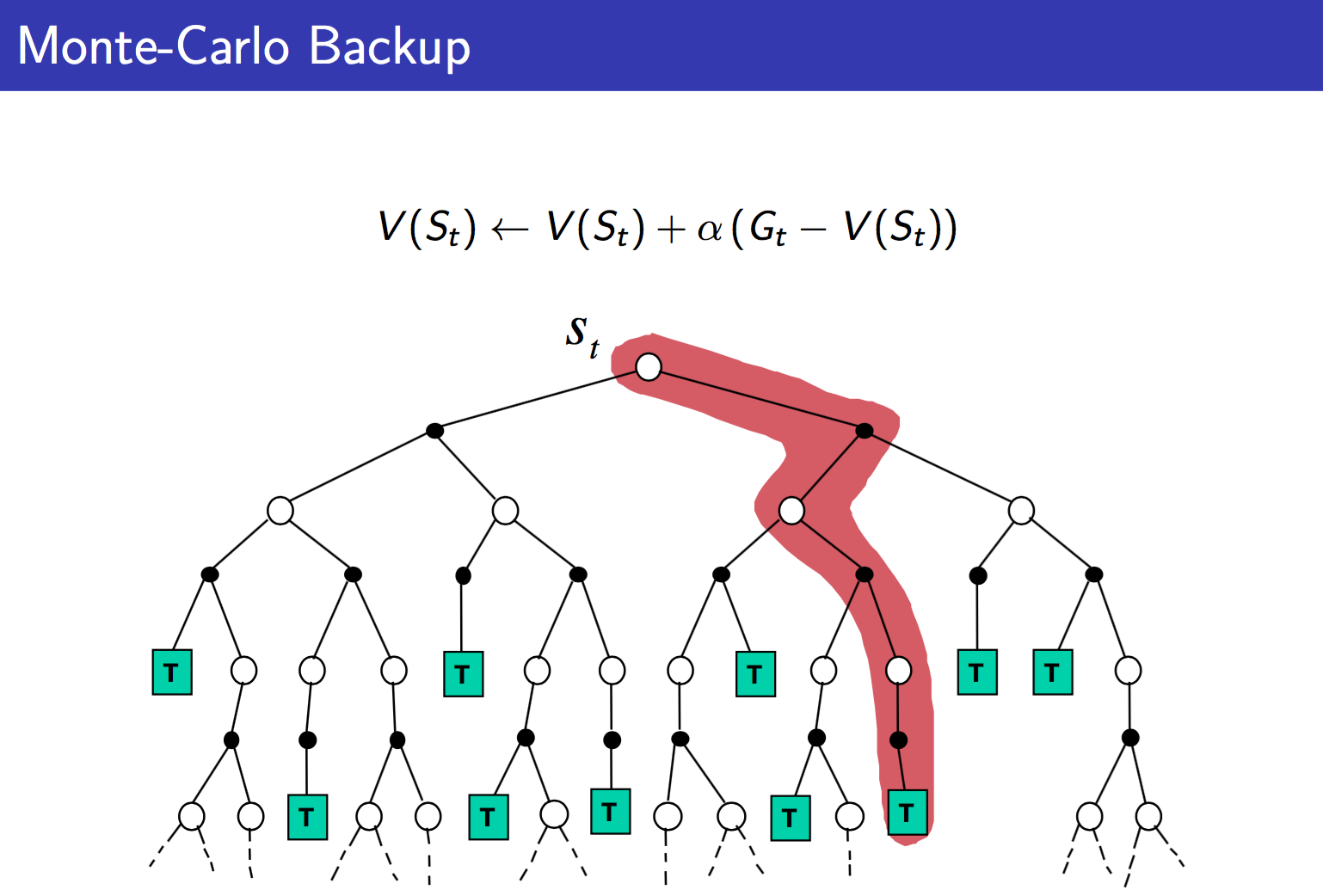
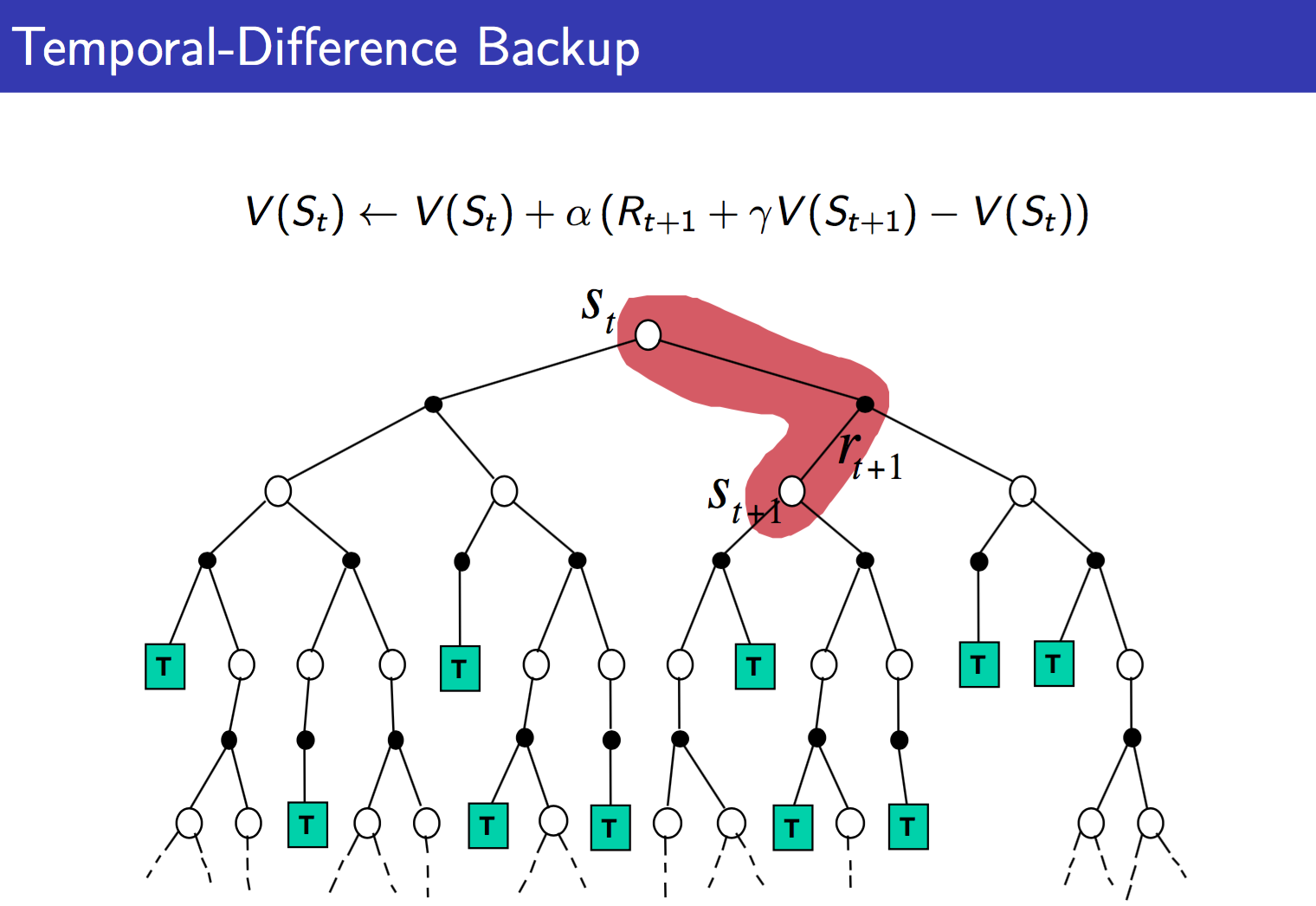
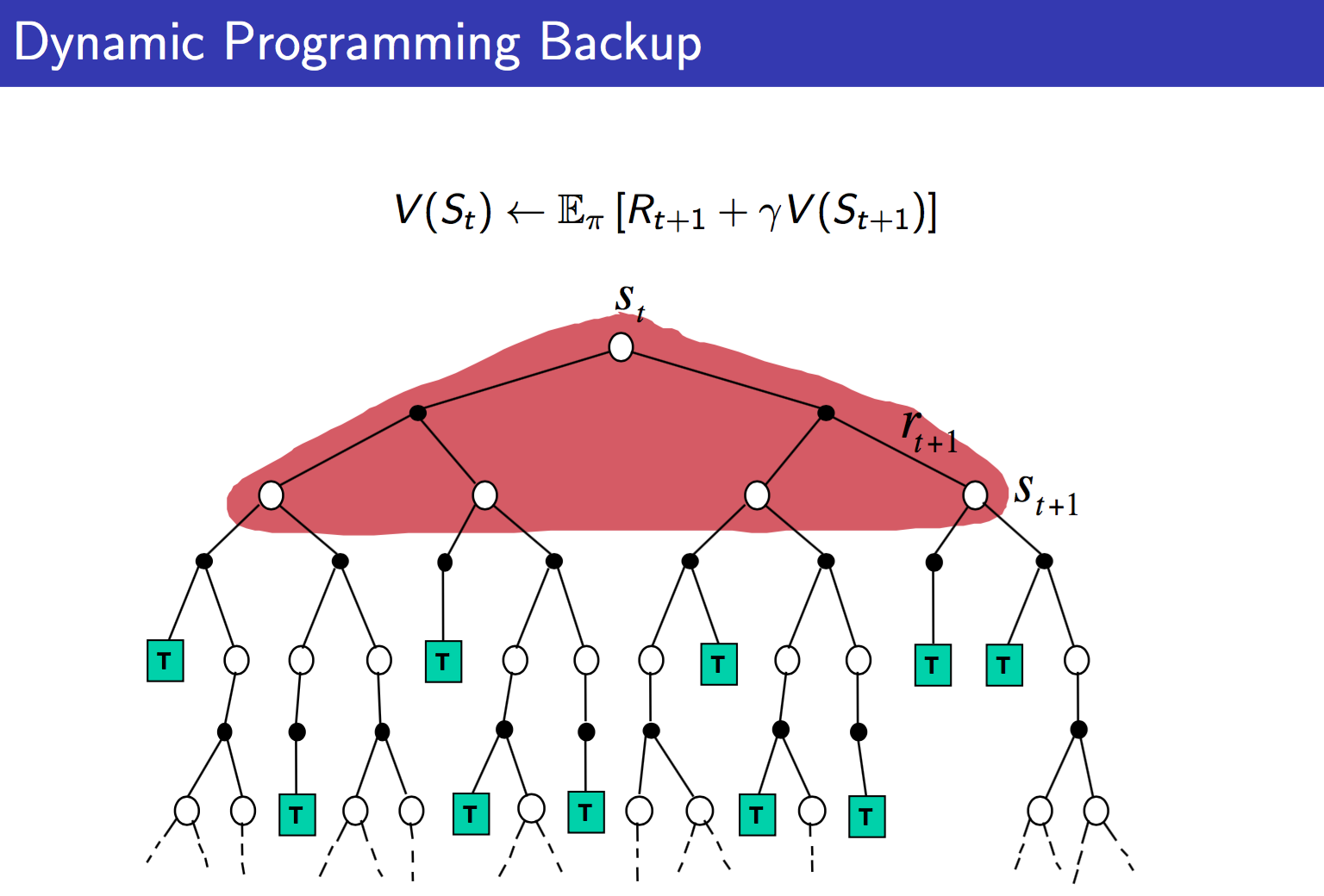
从上面可以很清楚的看到三者的不同。DP就是理想化的情况,遍历所有。MC现实一点,TD最现实,但是TD也最不准确。但是没关系,反复迭代之下,还是可以收敛的。
整个增强学习算法也都在上面的范畴里:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 928
928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









