







 本文详细介绍如何安装和配置Apache Zeppelin的过程,包括前置条件、源码获取、编译步骤及可能遇到的问题解决方法。此外还提供了配置指南和启动测试流程。
本文详细介绍如何安装和配置Apache Zeppelin的过程,包括前置条件、源码获取、编译步骤及可能遇到的问题解决方法。此外还提供了配置指南和启动测试流程。
1. 前置条件
None root account
Apache Maven
Java 1.7
2. 源码
git clone https://github.com/apache/incubator-zeppelin
3. 编译
本地模式:mvn clean package -DskipTests
集群模式: mvn clean package -Pspark-1.4 -Dspark.version=1.4.1 -Dhadoop.version=2.3.0-cdh5.1.0 -Phadoop-2.3 -DskipTests
在安装过程中 可能会出现各种问题,但是一般都是网络问题导致,但可重新执行下编译命令,如果编译出现oom,增加如下命令:
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m
但是在编译zeppelin-web模块 会遇到各种诡异的问题,web模块使用了node, grunt, bower工具
修改zeppelin-web项目的pom.xml
<plugin>
<groupId>com.github.eirslett</groupId>
<artifactId>frontend-maven-plugin</artifactId>
<version>0.0.23</version>
<executions>
<execution>
<id>install node and npm</id>
<goals>
<goal>install-node-and-npm</goal>
</goals>
<configuration>
<nodeVersion>v0.10.18</nodeVersion>
<npmVersion>1.3.8</npmVersion>
</configuration>
</execution>
<execution>
<id>npm install</id>
<goals>
<goal>npm</goal>
</goals>
</execution>
<execution>
<id>bower install</id>
<goals>
<goal>bower</goal>
</goals>
<configuration>
<arguments>--allow-root install</arguments>
</configuration>
</execution>
<execution>
<id>grunt build</id>
<goals>
<goal>grunt</goal>
</goals>
<configuration>
<arguments>--no-color --force</arguments>
</configuration>
</execution>
</executions>
</plugin>
有网友推荐我这样做,但感觉没啥效果
nodeVersion & npmVersion 版本分别改成v0.12.4,2.10.1,但我感觉用处不大
<configuration>
<nodeVersion>v0.12.4</nodeVersion>
<npmVersion>2.10.1</npmVersion>
</configuration>
安装顺序:
1. 首先需要提前安装好npm和node。 sudo apt-get install npm和npm install -g node。
2. 进入zeppelin-web目录下,执行 npm install。它会根据package.json的描述安装一些grunt的组件,安装bower,然后再目录下生产一个node_modules目录。
3. 执行 bower -–alow-root install,会根据bower.json安装前段库依赖,有点类似于java的mvn。见http://bower.io/
4. 执行 grunt –force,会根据Gruntfile.js整理web文件。
5. 最好执行 mvn install -DskipTests,把web项目打包,在target目录下会生成war。
mvn可能会出错,因为web.xml不在默认路径下,需要在pom.xml里添加:
1. 首先需要提前安装好npm和node。 sudo apt-get install npm和npm install -g node。
2. 进入zeppelin-web目录下,执行 npm install。它会根据package.json的描述安装一些grunt的组件,安装bower,然后再目录下生产一个node_modules目录。
3. 执行 bower -–alow-root install,会根据bower.json安装前段库依赖,有点类似于java的mvn。见http://bower.io/
4. 执行 grunt –force,会根据Gruntfile.js整理web文件。
5. 最好执行 mvn install -DskipTests,把web项目打包,在target目录下会生成war。
mvn可能会出错,因为web.xml不在默认路径下,需要在pom.xml里添加:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<configuration>
<webXml>app\WEB-INF\web.xml</webXml>
</configuration>
</plugin>
4. 配置
进入zeppelin_home/conf/
将 zeppelin-env.sh.template 修改为 zeppelin-env.sh
将 zeppelin-site.xml.template 修改为 zeppelin-site.xml
编译zeppelin-site.xml文件,
zeppelin.server.port 端口改成8089
我现在使用伪分布式模式,所以就不修改 zeppelin-env.sh文件中 MASTER,使用默认配置,即为local模式
如果要是使用spark standalone 分布式模式,那就改成如下
export MASTER=spark://master:7077
进入zeppelin_home/conf/
将 zeppelin-env.sh.template 修改为 zeppelin-env.sh
将 zeppelin-site.xml.template 修改为 zeppelin-site.xml
编译zeppelin-site.xml文件,
zeppelin.server.port 端口改成8089
<property>
<name>zeppelin.server.port</name>
<value>8089</value>
<description>Server port. port+1 is used for web socket.</description>
</property>我现在使用伪分布式模式,所以就不修改 zeppelin-env.sh文件中 MASTER,使用默认配置,即为local模式
如果要是使用spark standalone 分布式模式,那就改成如下
export MASTER=spark://master:7077
5. 启动
在zeppelin_home目录下执行如下命令:
bin/zeppelin-daemon.sh start
bin/zeppelin-daemon.sh start
Pid dir doesn't exist, create /home/cluster/apps/incubator-zeppelin-0.5.0/run
Zeppelin start [ OK ]
Zeppelin start [ OK ]
启动成功~
可以在localhost:8089 访问到zepplin主页了。如果没有出主页,可以看浏览器console,是缺少了什么文件,八成是web项目打包的时候漏了,很可能是bower和grunt命令执行的时候缺少依赖出错的。
主界面:
zeppelin home目录下会看到一个notebook文件夹,按notebook的名字命名区分了多个子目录。目录下是一个note.json文件,记录了每个notebook里输入的代码和执行结果,启动的时候会加载起来。
6.测试
zeppelin为spark做了更好的支持,比如默认是scala环境,默认sc已经创建好,即spark local可跑,默认spark sql有可视化效果。
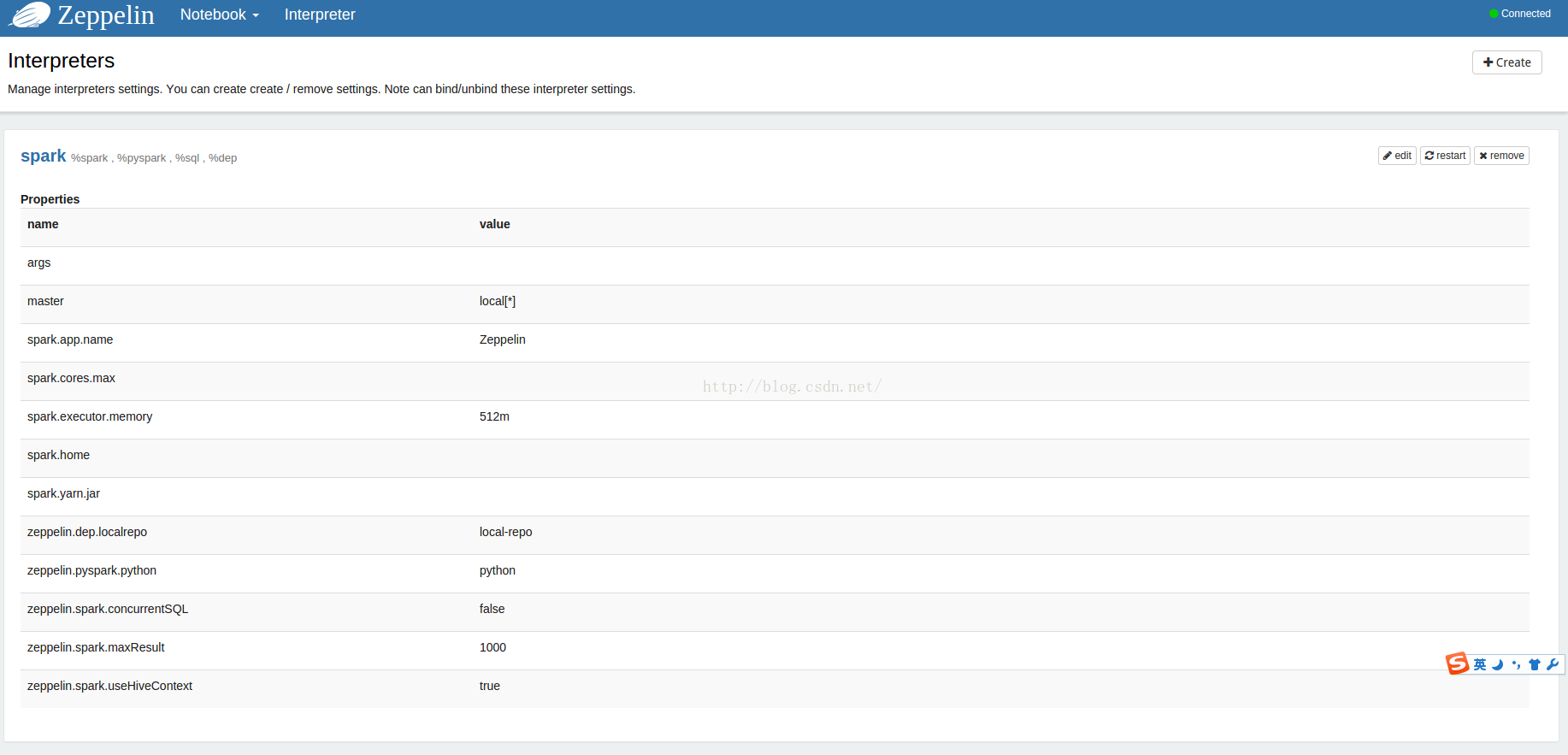
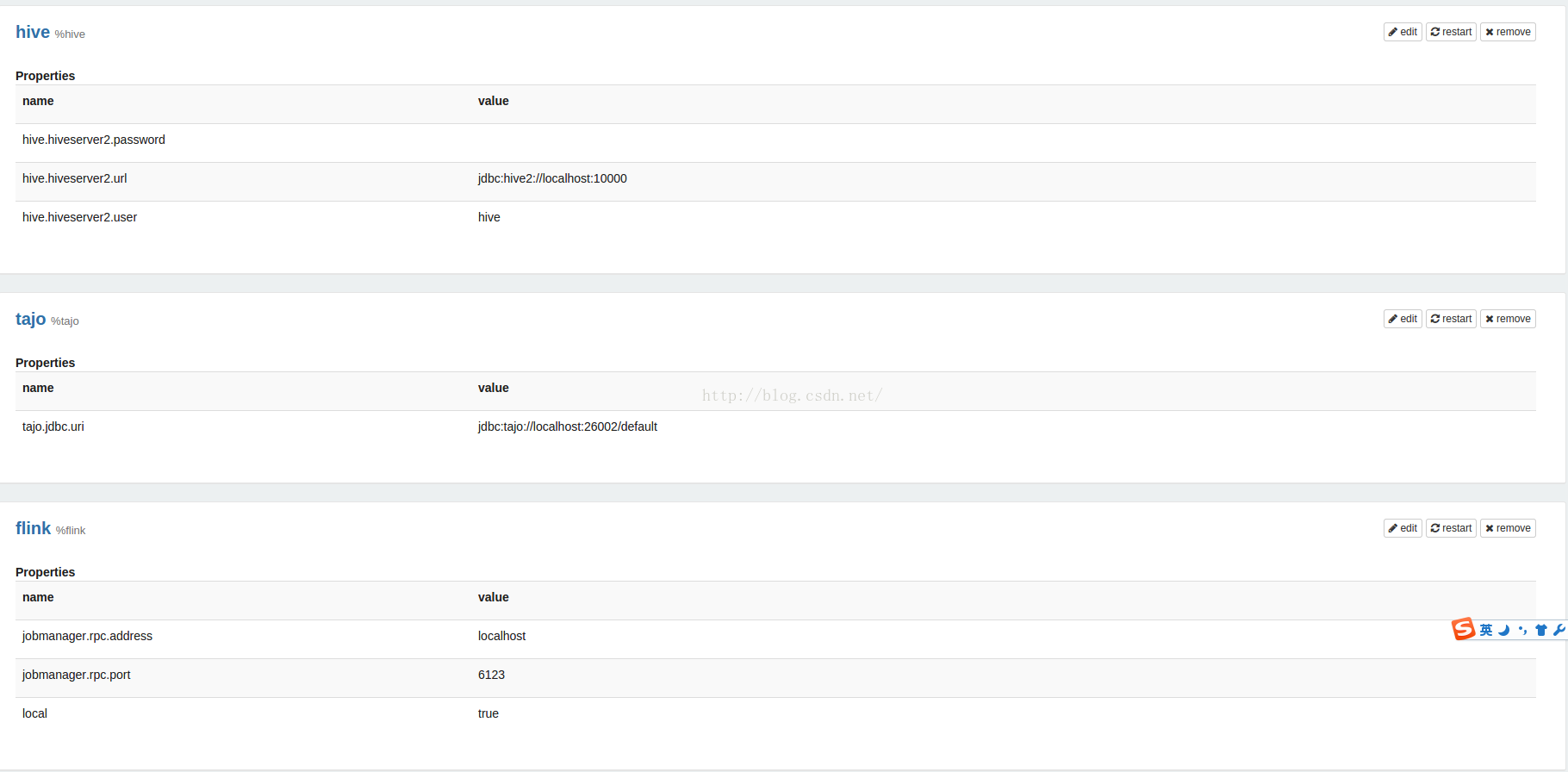
通过标识%md, %sh, %sql, %spark, %hive, %tajo来区分要执行的是什么,默认不写的话,执行环境是scala。在 http://127.0.0.1:8089/#/interpreter 页面里有详细的参数说明。
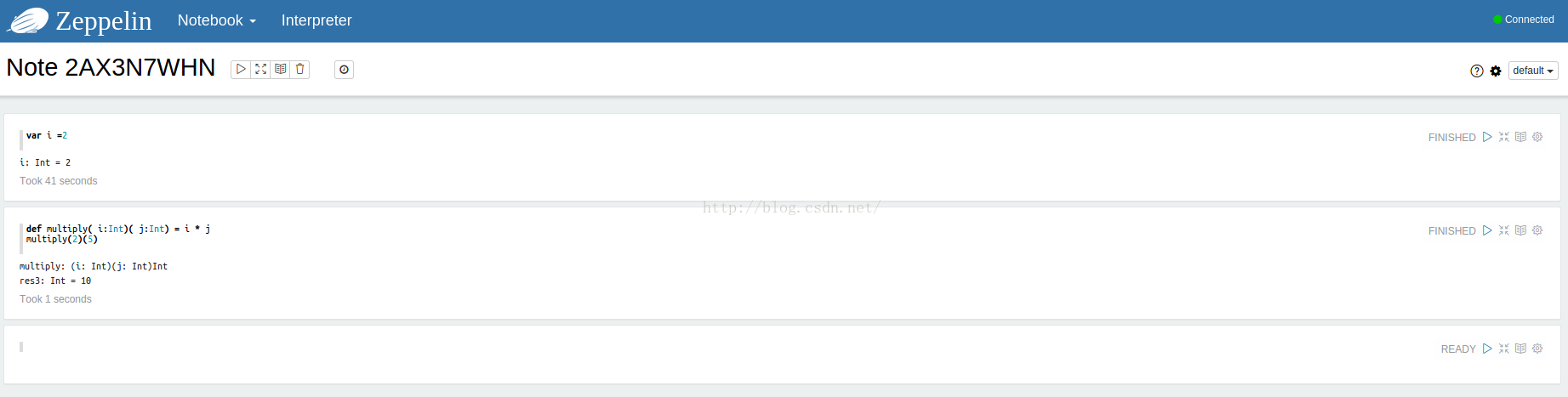
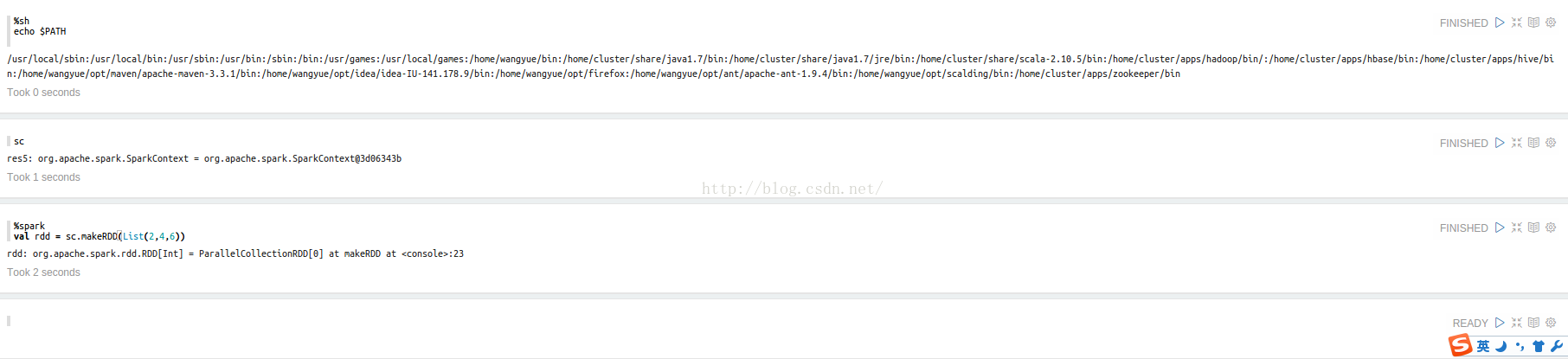
简单测试下 %sh,scala,%spark
好吧 ,先搞到这吧,稍后会有一篇 关于详细使用zeppelin 以及 zeppelin on yarn方式编译
尊重原创,拒绝转载

















 221
221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









