







学习linux 和 window 的EOF,记录如下。
1. 文件read
在window下创建一个文件,输入如下:
文件名: window.log
123456789
123
在linux下也创建一个文件,输入如下:
文件名: linux.log
123456789
123
在16进制下查看比较两个文件,截图如下:
window.log
linux.log

可见,window.log中换行符为 0D0A(\r\n),linux.log中的换行符为0A(\n).
但这里需要注意到, window.log中没有EOF(文件结束符), linux.log中也没有EOF(文件结束符)。 但是linux.log文件结束时有0A 这个字段, 也没有EOF。
linux 下写代码输出 linux.log内容:
#include <stdio.h>
int main(int argc,char *argv[])
{
int i=0;
FILE *fp;
char ch;
fp=fopen(argv[1],"r");
while((ch=fgetc(fp))!=EOF)
{
printf("i=%d\n",i); //测试时输出i的值,非必要
printf("ch=%c(%d)\n",ch,ch); //测试时输出c的值,非必要
i++;
}
printf("%dBytes\n",i);
return 0;
}结果输出:
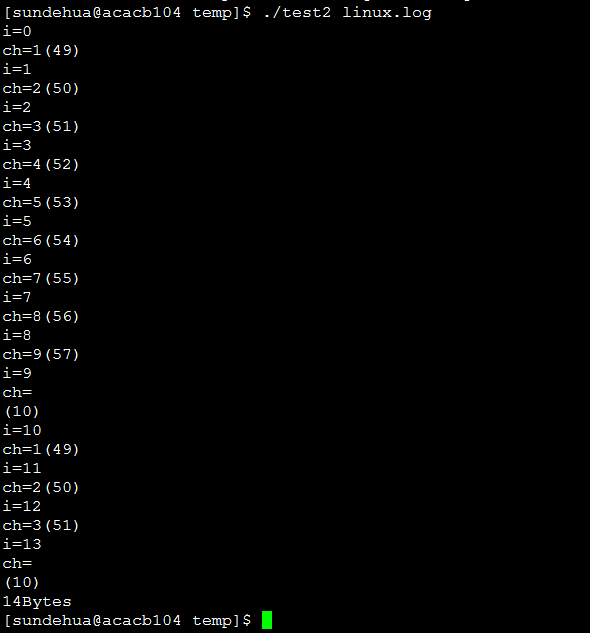
可见,linux.log 文件结束时的 0A 是被打印出来的。
网上搜索了下EOF资料:
http://www.ruanyifeng.com/blog/2011/11/eof.html 写的很好。
我学习C语言的时候,遇到的一个问题就是EOF。
它是end of file的缩写,表示”文字流”(stream)的结尾。这里的”文字流”,可以是文件(file),也可以是标准输入(stdin)。
比如,下面这段代码就表示,如果不是文件结尾,就把文件的内容复制到屏幕上。
int c;
while ((c = fgetc(fp)) != EOF) {
putchar (c);
}
很自然地,我就以为,每个文件的结尾处,有一个叫做EOF的特殊字符,读取到这个字符,操作系统就认为文件结束了。
但是,后来我发现,EOF不是特殊字符,而是一个定义在头文件stdio.h的常量,一般等于-1。
#define EOF (-1)
于是,我就困惑了。
如果EOF是一个特殊字符,那么假定每个文本文件的结尾都有一个EOF(也就是-1),还是可以做到的,因为文本对应的ASCII码都是正值,不可能有负值。但是,二进制文件怎么办呢?怎么处理文件内部包含的-1呢?
这个问题让我想了很久,后来查了资料才知道,在Linux系统之中,EOF根本不是一个字符,而是当系统读取到文件结尾,所返回的一个信号值(也就是-1)。至于系统怎么知道文件的结尾,资料上说是通过比较文件的长度。
所以,处理文件可以写成下面这样:
int c;
while ((c = fgetc(fp)) != EOF) {
do something
}
这样写有一个问题。fgetc()不仅是遇到文件结尾时返回EOF,而且当发生错误时,也会返回EOF。因此,C语言又提供了feof()函数,用来保证确实是到了文件结尾。上面的代码feof()版本的写法就是:
int c;
while (!feof(fp)) {
c = fgetc(fp);
do something;
}
但是,这样写也有问题。fgetc()读取文件的最后一个字符以后,C语言的feof()函数依然返回0,表明没有到达文件结尾;只有当fgetc()向后再读取一个字符(即越过最后一个字符),feof()才会返回一个非零值,表示到达文件结尾。
所以,按照上面这样写法,如果一个文件含有n个字符,那么while循环的内部操作会运行n+1次。所以,最保险的写法是像下面这样:
int c = fgetc(fp);
while (c != EOF) {
do something;
c = fgetc(fp);
}
if (feof(fp)) {
printf(“\n End of file reached.”);
} else {
printf(“\n Something went wrong.”);
}
除了表示文件结尾,EOF还可以表示标准输入的结尾。
int c;
while ((c = getchar()) != EOF) {
putchar(c);
}
但是,标准输入与文件不一样,无法事先知道输入的长度,必须手动输入一个字符,表示到达EOF。
2. getchar()
1.getchar是以行为单位进行存取的。
当用getchar进行输入时,如果输入的第一个字符为有效字符(即输入是文件结束符EOF,Windows下为组合键Ctrl+Z,Unix/Linux下为组合键Ctrl+D),那么只有当最后一个输入字符为换行符’\n’(也可以是文件结束符EOF,EOF将在后面讨论)时,getchar才会停止执行,整个程序将会往下执行。譬如下面程序段:
while((c =getchar())!=EOF){
putchar(c);
}
执行程序,输入:abc,然后回车。则程序就会去执行puchar(c),然后输出abc,这个地方不要忘了,系统输出的还有一个回车。然后可以继续输入,再次遇到换行符的时候,程序又会把那一行的输入的字符输出在终端上。
对于getchar,肯定很多初学的朋友会问,getchar不是以字符为单位读取的吗?那么,既然我输入了第一个字符a,肯定满足while循环(c = getchar()) != EOF的条件阿,那么应该执行putchar(c)在终端输出一个字符a。不错,我在用getchar的时候也是一直这么想的,但是程序就偏偏不着样执行,而是必需读到一个换行符或者文件结束符EOF才进行一次输出。
对这个问题的一个解释是,在大师编写C的时候,当时并没有所谓终端输入的概念,所有的输入实际上都是按照文件进行读取的,文件中一般都是以行为单位的。因此,只有遇到换行符,那么程序会认为输入结束,然后采取执行程序的其他部分。同时,输入是按照文件的方式存取的,那么要结束一个文件的输入就需用到EOF(Enf Of File). 这也就是为什么getchar结束输入退出时要用EOF的原因。
2.getchar()的返回值一般情况下是字符,但也可能是负值,即返回EOF。
这里要强调的一点就是,getchar函数通常返回终端所输入的字符,这些字符系统中对应的ASCII值都是非负的。因此,很多时候,我们会写这样的两行代码:
char c;
c =getchar();
这样就很有可能出现问题。因为getchar函数除了返回终端输入的字符外,在遇到Ctrl+D(Linux下)即文件结束符EOF时,getchar()的返回EOF,这个EOF在函数库里一般定义为-1。因此,在这种情况下,getchar函数返回一个负值,把一个负值赋给一个char型的变量是不正确的。为了能够让所定义的变量能够包含getchar函数返回的所有可能的值,正确的定义方法如下(K&R C中特别提到了这个问题):
int c;
c =getchar();
3.EOF的两点总结(主要指普通终端中的EOF)
3.1.EOF作为文件结束符时的情况:
EOF虽然是文件结束符,但并不是在任何情况下输入Ctrl+D(Windows下Ctrl+Z)都能够实现文件结束的功能,只有在下列的条件下,才作为文件结束符。
(1)遇到getcahr函数执行时,要输入第一个字符时就直接输入Ctrl+D,就可以跳出getchar(),去执行程序的其他部分;
(2)在前面输入的字符为换行符时,接着输入Ctrl+D;
(3)在前面有字符输入且不为换行符时,要连着输入两次Ctrl+D,这时第二次输入的Ctrl+D起到文件结束符的功能,至于第一次的Ctrl+D的作用将在下面介绍。
其实,这三种情况都可以总结为只有在getchar()提示新的一次输入时,直接输入Ctrl+D才相当于文件结束符。
3.2.EOF作为行结束符时的情况,这时候输入Ctrl+D并不能结束getchar(),而只能引发getchar()提示下一轮的输入。
这种情况主要是在进行getchar()新的一行输入时,当输入了若干字符(不能包含换行符)之后,直接输入Ctrl+D,此时的Ctrl+D并不是文件结束符,而只是相当于换行符的功能,即结束当前的输入。以上面的代码段为例,如果执行时输入abc,然后Ctrl+D,程序输出结果为:
abcabc
注意:第一组abc为从终端输入的,然后输入Ctrl+D,就输出第二组abc,同时光标停在第二组字符的c后面,然后可以进行新一次的输入。这时如果再次输入Ctrl+D,则起到了文件结束符的作用,结束getchar()。
如果输入abc之后,然后回车,输入换行符的话,则终端显示为:
abc //第一行,带回车
abc //第二行
//第三行
其中第一行为终端输入,第二行为终端输出,光标停在了第三行处,等待新一次的终端输入。
从这里也可以看出Ctrl+D和换行符分别作为行结束符时,输出的不同结果。
EOF的作用也可以总结为:当终端有字符输入时,Ctrl+D产生的EOF相当于结束本行的输入,将引起getchar()新一轮的输入;当终端没有字符输入或者可以说当getchar()读取新的一次输入时,输入Ctrl+D,此时产生的EOF相当于文件结束符,程序将结束getchar()的执行。















 794
794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









