







 本文介绍了如何利用scipy数值优化包解决参数估计问题,包括非线性最优化、有约束的多元函数问题、全局优化和最小二乘法。详细探讨了最小二乘法的leastsq方法以及lmfit库的使用,lmfit提供了更方便的参数管理和优化方法选择。
本文介绍了如何利用scipy数值优化包解决参数估计问题,包括非线性最优化、有约束的多元函数问题、全局优化和最小二乘法。详细探讨了最小二乘法的leastsq方法以及lmfit库的使用,lmfit提供了更方便的参数管理和优化方法选择。
引言
优化是一门大学问,这里不讲数学原理,我假设你还记得一点高数的知识,并且看得懂python代码。
关于求解方程的参数,这个在数据挖掘或问题研究中经常碰到,比如下面的回归方程式,是挖掘算法中最简单最常用的了,那么怎么求解方程中的各个参数呢?
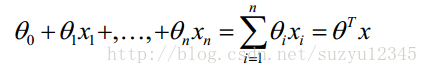
当然,对于常见的挖掘算法,甚至是复杂的深度学习,在sklearn和tensorflow等工具已经很好解决怎么求解参数的问题,只需要调接口就好了。
那么我们再看下面的bass方程式,同样很简单,但是没有现成可用的程序可用,怎么求解最优的参数呢?

图片不是很清晰,只是为了说明问题。就是如果你有了明确的数学表达式,也有了一些测量数据,怎么求解里面的参数,才是这批文章要说的。
关于求导
其实关于参数求解的方法,是有很标准的方法的,比如最大似然估计,最小二乘法等。这些需要你还记得高数的知识。求导,梯度,然后梯度下降,多么标准的方法啊,这种思想和方法在大部分的数据挖掘算法里面都是这么干的,而且经过精巧而优美的变化,大部分问题总能将目标函数最小化转成凸优化问题。
但是在学习中总不是那么顺利的,除了一些常见的算法可以调程序外,很多研究公式还是要自己想办法求解方程参数,特别是很多论文中,作者为了显示自己研究的独到之处,总是对标准方程加以改造,加入正则项,修正项等等,比如上面的bass方程式,这就尴尬了。
当然,这也可以通过极大似然估计,或者最小二乘的方法,但是不是我们想要的,为什么,因为我们不是搞研究的啊,在工作中,基本就是拿来就用,不行就扔。
scipy数值优化
其实使用scipy进行数值优化,就是黑盒优化, 我们不依赖于我们优化的函数的算术表达式。注意这个表达式通常可以用于高效的、非黑盒优化。
scipy中的optimize子包中提供了常用的最优化算法函数实现。我们可以直接调用这些函数完成我们的优化问题。optimize中函数最典型的特点就是能够从函数名称上看出是使用了什么算法。
下面optimize包中函数的概览:
1.非线性最优化
fmin– 简单Nelder-Mead算法fmin_powell– 改进型Powell法fmin_bfgs– 拟Newton法fmin_cg– 非线性共轭梯度法fmin_ncg– 线性搜索Newton共轭梯度法leastsq– 最小二乘
2.有约束的多元函数问题
fmin_l_bfgs_b—使用L-BFGS-B算法fmin_tnc—梯度信息fmin_cobyla—线性逼近fmin_slsqp—序列最小二乘法nnls—解|| Ax - b ||_2 for x>=0
3.全局优化
anneal—模拟退火算法brute–强力法
4.标量函数
fminboundbrentgoldenbracket
5.拟合
curve_fit– 使用非线性最小二乘法拟合
6.标量函数求根
brentq—classic Brent (1973)brenth—A variation on the classic Brent(1980)ridder—Ridder是提出这个算法的人名bisect—二分法newton—牛顿法fixed_point
7.多维函数求根
fsolve—通用broyden1—Broyden’s first Jacobian approximation.broyden2—Broyden’s second Jacobian approximationnewton_krylov—Krylov approximation for inverse Jacobiananderson—extended Anderson mixingexcitingmixing—tuned diagonal Jacobian approximationlinearmixing—scalar Jacobian approximationdiagbroyden—diagonal Broyden Jacobian approximation
8.实用函数
line_search—找到满足强Wolfe的alpha值check_grad—通过和前向有限差分逼近比较检查梯度函数的正确性
参考网上资料,以及从scipy的文档找到的,还有一些没有放上去,这么多,我也没完全搞明白,这里主要讲leastsq和fmin_l_bfgs_b,但是它们的用法基本是一样的。
注意:
1.需要特别说明一点的是,上面的方法,既可以用来求函数的极值,也可以反过来看问题,将参数当做输入变量X,从而在观测样本上计算极值,就是我们要求的参数值。
2.我们下面只讲怎么求解参数,关于用scipy.optimize 求极值的例子很多,官网文档的例子也很好理解,而求解参数的反而没多少,这促使我要把最近的一些学习成果好好整理一下,算是做笔记吧。
3.要时刻记住,当你使用scipy.optimize 的时候,你是使用黑盒优化,你不知道你的目标函数是不是凸函数,也不知道它计算的数值梯度和解析梯度相差有多大,甚至,当你猜的初值不合理,结果也是有问题的。
4.无论如何,你都需要给出误差计算方法,也就是说,你需要知道 y=f(x) 的具体公式是上面,这样才能通过x计算
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4663
4663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









