






任何技术点在你未曾接触过的时候,都是觉得雾里看花,水中望月,既遥远又神秘,但是当你尝试学习并通过实践对其脉络掌握清楚以后,就会觉得原来这么简单,技术就是那么一回事儿。
mapreduce分布式编程模型是google在2004年提出来的,目的是为了解决海量数据的处理,我们通过一段时间的应用,对mapreduce编程的实现机理有了一定了解,现总结如下,希望能为应用开发者提供帮助,我尽量阐述的简单易懂。
海量数据的处理,无非就是首先将海量文件进行打散,然后对打散后的每一份数据块儿分别处理,最终将数据结果归并,所谓分而治之也。你一定会问数据之间有关联怎么办,将数据打散到多台机器上,那有关联的数据是不是就没办法进行分析了?后面会详细介绍。
我们先看一下hadoop的处理流程。
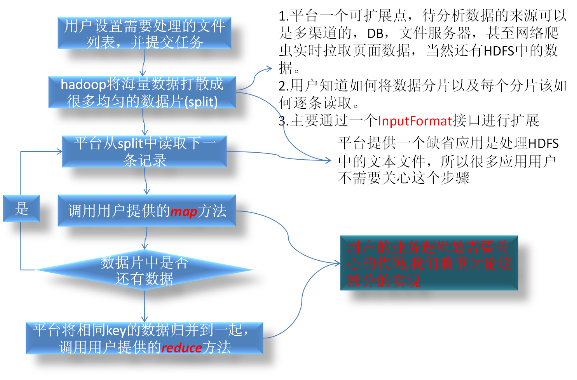
map方法的主要目的是进行数据进行分拣,分析出自己关心的数据,并为与同一类指标相关联的数据都打上一个标记:KEY, 平台会将打上同一个标记KEY的数据从各台机器上收集起来集中到一台机器,然后调用用户的reduce方法进行数据的统计分析。
我们通过一个具体实例学习mapreudce代码的编写。
1.数据统计分析
需求:
假如我有一整天用户访问页面流水日志,日志格式如下:
用户访问的页面 用户QQ号码 用户访问IP .....
www.qq.com/sub/.. 21201421 202.201.22.23
qzone.qq.com/21201421/.. 2222222 10.201.22.23
我需要统计出每个域名一天的用户数(需要去重),访问量,各地区访问人数(假如通过IP可以分析出地区信息)。
那用户的map方法做什么操作呢?
我们看一下map方法的参数
以下的例子都是通过java接入方式实现,当然还支持很多语言(这一点也不重要,呵呵!)
void map(K1 key, V1 value, OutputCollector<K2, V2> output, Reporter reporter);
我们使用系统缺省提供的处理文本文件的InputFormat: TextInputFormat,它是基本按照64M大小进行数据切片的,它提供的RecordReader读出的Key是文件行数,value是一行的内容。Key和value的类型用户也可以自定义(当然这些与我们这次分析主题无关,大家只要知道有这么回事儿就行了)
我们需要分析每个域名一天的用户数,办法很简单,就要找到每次访问是由哪个用户触发的,将所有用户归总起来,再去重后就可以得到用户数,但是数据量多的时候就不好处理了,(*^__^*)...嘻嘻,没关系,有分布式计算平台。
1.Map要做的事情,仅仅是分析出每项记录中的域名,以及用户QQ号码。
OK! 下面是伪代码
map(K1 key, Text value, OutputCollector<K2, V2> output, Reporter reporter)
{
String lineValue = value.toString();
String[] values = lineValue.split("/t");
//处理values[0]得到域名前缀: 比如 www.qq.com
domain = process(values[0]);
//核心在这里,同一个域名下的数据需要归并到一起,找到与一个域名相关的用户信息(QQ号码),只需要将这个信息打上一个标记反馈给框架。
//标记在这里生成,不要和其他指标冲突哦
key = domain+"_UV";
//得到QQ号码
value = values[1];
//将找到的key->value对反馈给框架
Output.emit(Key ,Value);
}
2.Reduce方法需要做什么
void reduce(Text key, Iterator<Text> values,
OutputCollector<Text, Text> output, Reporter reporter)
{
if( postFix( key ) == "_UV" ) //判断是否是用户数这个指标相关的数据
{
//values中的数据就是从各台机器上归总过来的QQ号码
String uv = distinctCount( values );
//push出最终结果
Output.emit(key,uv );
}
}
是不是很简单? 用户并不需要关系分布式平台如何分解任务,如何归并结果,只需要关心自己的业务逻辑,这样的设计也就是所谓的关注点分离。
用户在map方法中从原始数据中分析出与自己关心的某个数据指标有关联的数据,给这个数据打个标签(这个标签是关键,不要和其他指标有重复哦!!,将来平台自动将与这个标签相关连的数据汇总到一起,再提供给用户,调用用户的reduce方法),在reduce方法中只需要都聚集到一起的数据进行统计或其他操作,随便你...
可上面的分析需求我们只满足了一个,其他两个怎么实现呢,我认为到这里大家应该知道该如何写mapreudce程序了,我会利用更简单的伪代码进行描述,ok 开始了。
map(K1 key, Text value, OutputCollector<K2, V2> output, Reporter reporter)
{
1.域名一天的用户数
从value中分析出域名和QQ号码
output.emit(“$(域名)_UV",$(QQ号码));
2.域名一天的访问量,
output.emit(“$(域名)_PV",1);
看到了没有??这个指标的后缀我改成_PV了,有人会问为什么emit最后一个参数是常数"1"而不是QQ号码呢?这个功能只是做个计数,又不需要去重,我拿QQ号码作甚?还浪费网络带宽,将来我只要将这些个"1"加起来就得到访问次数了。
3.各地区总访问人数
从value中分析出IP,从IP映射出地区
Output.emit( func_IP_to_district(ip)+"_DIS" , 1 );
因为我也只是计数地区访问次数,所以不需要emit出QQ号码
}
void reduce(Text key, Iterator<Text> values,
OutputCollector<Text, Text> output, Reporter reporter)
{
if( key的后缀是"_UV" )
{
去重values中的QQ号码,计数count
//最终找到各域名的用户数,交给框架输出
output.emit(key,count);
}
if(key的后缀是"_PV")
{
pvCount=0;
for 循环遍历values
{
pvCount++;
}
//最终找到各域名的访问量,交给框架输出
output.emit(key,pvCount);
}
if(key的后缀是"_DIS")
{
disCount=0;
for 循环遍历values
{
disCount++;
}
//最终找到各域名的访问量,交给框架输出
output.emit(key,disCount);
}
}
以上两个简单的方法,其实也变相实现了单表的grouyby统计。
Select( count(*) , count(distinct(QQ)) ) from table grouy by $取域名(网页url)
Select count(*) from table groupby $取地区(IP);
当然mapreudce不仅仅实现数据的统计操作,各类数据分析都可以进行支持,我在这里只是举个例子。
我们再结合一张数据流向图,进一步说清楚这个问题:
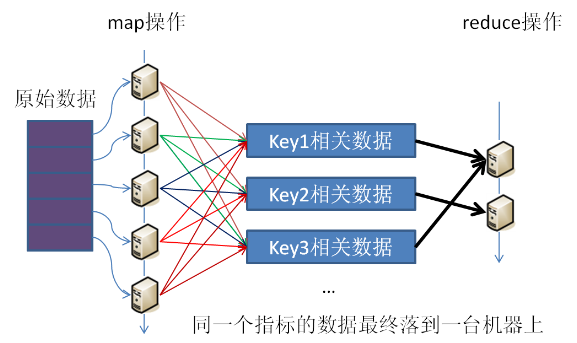
每台机器处理的数据片都不一样,与同某一指标有关联的数据很可能分配到多台机器上,但最终通过key这个纽带,与一个指标相关联的数据被汇总到一起,交给用户进行处理。
2.多数据关联分析
下面我们看一个稍复杂的需求,类似于
select sum(A.price),sum(B.count) form A B where A.id=B.id group by id;
数据A的格式
| id | price | 其他字段1 | 其他字段2 |
| 1 | 2.4 | XXX | XXX |
| 2 | 3.6 | XXX | XXX |
| 1 | 4.8 | XXX | XXX |
| ... |
|
|
|
1,2.4,XXX,XXX
2,3.6,XXX,XXX
1,4.8,XXX,XXX
...
数据B的格式
| id | count | 其他字段1 | 其他字段2 |
| 2 | 8 | XXX | XXX |
| 2 | 4 | XXX | XXX |
| 1 | 3 | XXX | XXX |
| ... |
|
|
|
2,8,XXX,XXX
2,4,XXX,XXX
1,3,XXX,XXX
经过上面case的讲解大家应该比较清楚如何做了,在这里我就不罗嗦了,直接上代码:
map(K1 key, Text value, OutputCollector<K2, V2> output, Reporter reporter)
{
首先从配置的上下文中判断目前正在对哪一个文件的数据集进行处理
If( 是A文件的数据 )
{
Split(",")得到 自己关心的id和price两个字段。
//这里有些小技巧,我们通过id这个字段做key,那将来两个文件中同一个key的数据就会由平台帮你归并到一起,加上“PRICE:”前缀是为了更方便,准确的区分数据。
Output.emit(id,"PRICE:"+price);
}
If( 是B文件的数据 )
{
Split(",")得到 自己关心的id和count两个字段。
Output.emit(id,"COUNT:"+count);
}
}
//平台将每个key的数据归并到一起时,就会有很多形似如下格式的信息。
比如 id=1的KEY对应的数据序列为:
PRICE:2.4
PRICE:4.8
COUNT:3
...
void reduce(Text key, Iterator<Text> values,
OutputCollector<Text, Text> output, Reporter reporter)
{
float priceSum = 0.0;
long countSum = 0;
for( Text value :values)
{
根据“PRICE:”和“COUNT:”前缀区分数据代表什么值
if( 是price)
priceSum + = price;
else if( 是count)
countSum += count;
}
output.collect(key,"PRICESUM:"+priceSum +"/t"+"COUNTSUM:"+countSum );
}
是不是很简单,SO EASY!
打个广告,分布式计算平台发布以来已经承接了公司WSD,ISD,SOSO,点击流等BU以及系统的数据分析任务,长期以来系统保持稳定,并通过机器平行扩展的方式维持着一定的数据分析性能,如果哪位同事有海量数据的分析需求,请联系数据平台部-分布式计算平台项目组:tedxu,jakegong,joeyli,stevenshi...
mapreudce代码方式目前只是我们的一种数据分析任务接入方式,java,C++,SQL脚本,shell,python..等脚本都可以实现分析任务的编写
希望分布式计算平台可以帮助大家解决海量数据处理问题,谢谢!!

















 2454
2454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









