






在lease一章我们已经对文件创建流程有了一个大致了解,
文件的创建主要是通过提供给用户前项层工具抽象类FileSystem,针对于HDFS这个类的具体实现为DistributedFileSystem。
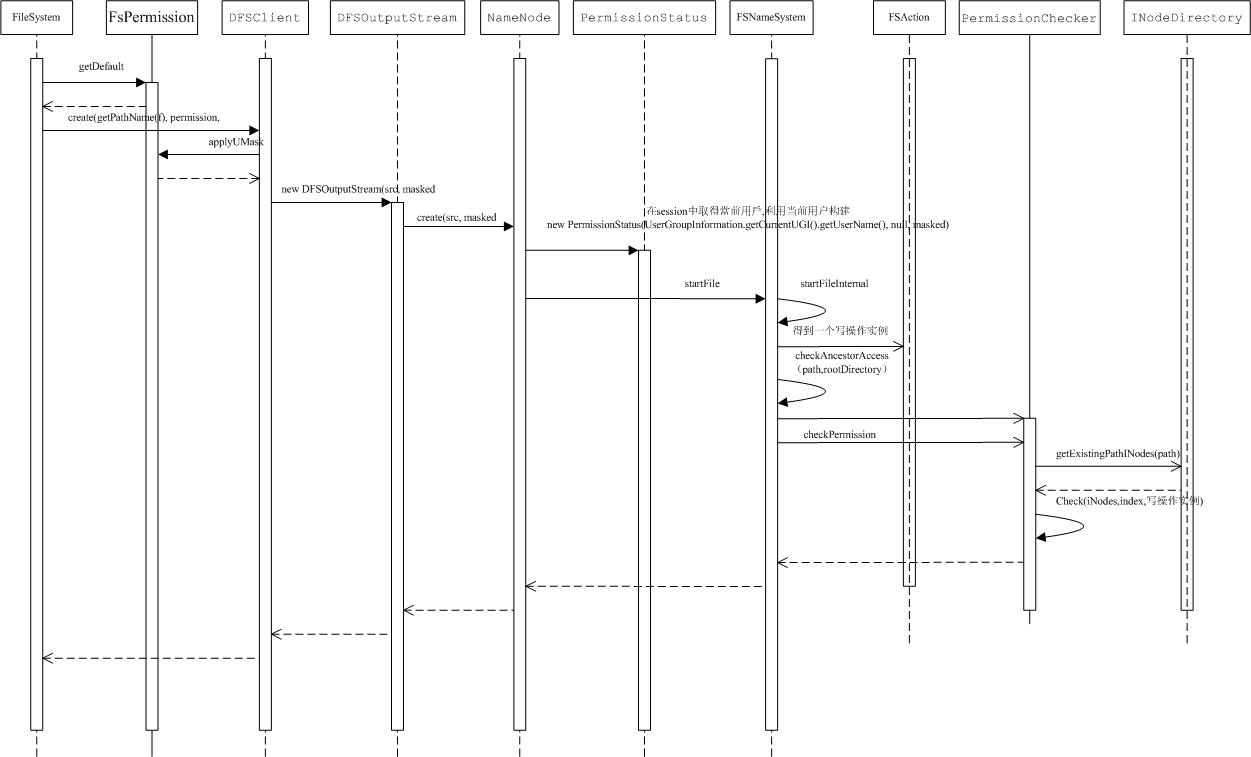
文件夹的创建是一个相对简单的过程,主要是通过FileSystem中的mkdirs()方法,这个方法在DFSClient实例中调用同名方法mkdirs(),通过Hadoop本身的RPC机制调用Namenode的mkdirs()方法,最终这个调用PUSH到FSNameSystem的mkdirsInternal方法,这个方法主要就是检验访问权限,最后通过FSDirectory的unprotectedMkdir()方法,构建一个INodeDirectory实例添加到文件系统的目录树中。
文件节点的创建与添加相对比较麻烦,主要步骤如下:
FileSystem的create方法返回一个很重要的类FSDataOutputStream,这一点也比较好理解,就像java中的文件流一样,创建一个文件写入流对文件内容进行追加,首先我们看文件创建阶段namenode主要做了什么事情(权限验证以及租约验证这些前面都已经有提到,下面的内容就会掠过这一部分)
DfSOutputStream在实例构建时,通过Hadoop本身的RPC机制调用Namenode的create方法,最终这个调用PUSH到FSNameSystem的StartFileInternal方法,需要做权限验证,租约检验等工作,这个方法主要作用就是创建一个INodeFileUnderConstruction实例(上面已经提过,文件写入过程中都会有一个INodeFileUnderConstruction与这个文件对应),这个实例最后通过FSDirectoty的addNode()方法添加到文件系统目录数中,这个时候文件创建操作就算完成了重要的第一步,文件系统中已经有了这个文件的记录。
下面就涉及到文件的写入操作(相当复杂的部分)
这个时候就需要用到返回的DfSOutputStream对象。
这部分太复杂了,我们先分析一些基本模块儿,逐步吃透这部分的实现。
整个分布式文件系统中网络通讯部分分为两类:
1.命令类调用(这部分通过HADOOP的RPC机制进行支持)
2.流式数据传输(这部分通过HADOOP的流式数据传输协议支持)
为了保证数据的正确性,hadoop在多个关键处理单元做了数据检验操作,在流式数据网络传输部分通过校验和保证数据传输正常。
Client在DfSOutputStream对象调用write方法时,系统并不会马上把数据写入SOCKET中,而是逐个构建Package并将这些Package加入一个队列。
在DfSOutputStream对象构建时,系统通过Hadoop本身的RPC机制调用Namenode的create方法后,会启动一个后台线程 streamer.start(); 这个线程的主要目的就是将上述的package队列写入SOCKET中。
我们首先看DfSOutputStream的继承关系

其中FSOutputSummer这个类其实质是一个decorator设计模式的实现,主要的目的就是在OutputStream的void write(byte b[], int off, int len)方法中增加一些功能,上文已经提过,文件数据传输的同时,系统会在传输的数据中增加检验和数据,系统收到数据后对数据进行校验,保证数据传输的正确性,但是用户在对文件输出流进行操作的时候并不需要关注校验和数据,用户只需要不断的调用write方法在目标文件中追加数据。
我们看一下FSOutputSummer中write(byte b[], int off, int len)的实现
public synchronized void write(byte b[], int off, int len)
throws IOException
{
if (off < 0 || len < 0 || off > b.length - len) {
throw new ArrayIndexOutOfBoundsException();
}
for (int n=0;n<len;n+=write1(b, off+n, len-n))
{ }
}
可以看到不断调用write1方法,保证数据发送的完整性。
那么write1方法又做了什么事情呢,write1将用户需要写入的数据流首先写到自己的BUFFER中,达到一定数量(基本是一个chunk的大小)后进行CheckSum方法调用得到一段数据的校验和按照一定格式要求一并写入Stream
private int write1(byte b[], int off, int len) throws IOException {
if(count==0 && len>=buf.length)
{
// local buffer is empty and user data has one chunk
// checksum and output data
final int length = buf.length;
sum.update(b, off, length);
writeChecksumChunk(b, off, length, false);
return length;
}
// copy user data to local buffer
int bytesToCopy = buf.length-count;
bytesToCopy = (len<bytesToCopy) ? len : bytesToCopy;
sum.update(b, off, bytesToCopy);
System.arraycopy(b, off, buf, count, bytesToCopy);
count += bytesToCopy;
if (count == buf.length)
{
// local buffer is full
flushBuffer();
}
return bytesToCopy;
}
sum是什么咚咚呢? new CRC32(),通过这个对象得到校验和
从代码中可以清楚的看到,用户不断往outputstream中追加数据,这些数据会首先存到一个buffer中,等用户写入的数据达到一定数量(基本是一个chunk的大小)后就会对这段数据取校验和,然后通过writeChecksumChunk这个方法将数据以及该部分数据的校验和,按照一定格式一并写入到SOCKET。
接下来我们一起看一下writeChecksumChunk()这个方法
private void writeChecksumChunk(byte b[], int off, int len, boolean keep) throws IOException
{
int tempChecksum = (int) sum.getValue();
if (!keep)
{
sum.reset();
}
int2byte(tempChecksum, checksum);
writeChunk(b, off, len, checksum);
}
这个方法的主要作用就是将用户写入的数据以及该部分数据的校验和做为参数调用writeChunk()方法,这个方法是一个虚方法,真正的实现在DFSOutputStream这个类中,这也合情合理,本身FSOutputSummer这个类的作用仅仅是在输出流中增加校验和数据,至于数据是如何进行传输的是通过DFSOutputStream来实现的。
那么接下来需要说明的就是DFSOutputStream的writeChunk这个方法了。
HDFS流式数据网络传输的基本单位有哪些呢?
chunk->package->block
我们上文已经提过:等用户写入的数据达到一定数量(基本是一个chunk的大小)后就会对这段数据取校验和。
一定数量的chunk就会组成一个package,这个package就是最终进行网络传输的基本单元,datanode收到package后,将这些package组合起来最终得到一个block。
我们接下来通过实际主要的代码了解这部分功能的实现:
currentPacket这个对象初始化的时候就是null,第一次写入数据时这个判断成立
if (currentPacket == null)
{
currentPacket = new Packet(packetSize, chunksPerPacket,
bytesCurBlock);
...
//下面开始构建package包。
//在package包中增加一个chunk,首先添加这个chunk所包含数据的checksum
currentPacket.writeChecksum(checksum, 0, cklen);
//然后添加这个chunk所包含的数据
currentPacket.writeData(b, offset, len);
//增加这个package所包含的chunk个数
currentPacket.numChunks++;
//当前已经写入的byte个数
bytesCurBlock += len;
// If packet is full, enqueue it for transmission
//如果这个package已经达到一定的chunk数量,准备实际的传输操作
if (currentPacket.numChunks == currentPacket.maxChunks
|| bytesCurBlock == blockSize)
{
......
//如果用户写入的数据,已经达到一个block缺省大小(64M)
if (bytesCurBlock == blockSize)
{
//设置当前的package是某一个block的最后一个package
currentPacket.lastPacketInBlock = true;
//清除一些变量的值
bytesCurBlock = 0;
lastFlushOffset = -1;
}
//这三段代码是关键的一部分代码,将已经构建完成的package写入一个dataQueue队列,由另一个线程(就是我们开始提到的:启动一个后台线程 streamer.start(); 这个线程的主要目的就是将上述的package队列写入SOCKET中)从该队列中不断取出package,进行实际的网络传输
dataQueue.addLast(currentPacket);
//产生event,进而通知并唤醒等待线程
dataQueue.notifyAll();
//这一步也很重要,设置currentPacket 为空,表示这个package已经满了,需要new一个新的package继续接收用户后面进一步需要写入的数据。
currentPacket = null;
// If this was the first write after reopening a file, then
// the above write filled up any partial chunk. Tell the summer to generate full
// crc chunks from now on.
if (appendChunk)
{
appendChunk = false;
resetChecksumChunk(bytesPerChecksum);
}
int psize = Math.min((int) (blockSize - bytesCurBlock),
writePacketSize);
computePacketChunkSize(psize, bytesPerChecksum);
}
computePacketChunkSize这个方法的主要作用是计算两个参数:
1.chunksPerPacket
接下来的package需要承载多少个chunk;因为最后一个package承载的chunk个数与文件大小也有关系。
2.packetSize
接下来的package的大小。
以上两个参数与判断是否需要new一个新的PACKAGE很有关系。
private void computePacketChunkSize(int psize, int csize)
{
int chunkSize = csize + checksum.getChecksumSize();
int n = DataNode.PKT_HEADER_LEN + SIZE_OF_INTEGER;
chunksPerPacket = Math.max((psize - n + chunkSize - 1) /
chunkSize,1);
packetSize = n + chunkSize * chunksPerPacket;
if (LOG.isDebugEnabled())
}
可以看到构建的package不断添加到dataQueue这个队列,streamer.start()这个线程从中弹出package进行实际网络传输操作。
下面就涉及到比较复杂的网络传输协议部分。
我们先看一下这部分的流程:
1.上面已经讲过,开始的一步就是客户端调用create方法,在namenode上的目录树中注册一个INodeFileUnderConstruction节点,并得到一个DfSOutputStream。
2.用户得到这个outputStream后就可以进行写入操作,用户写入的数据就不断构建成package写入dataQueue这个队列。
3.streamer.start()这个线程从dataQueue队列中取出package进行实际网络传输操作。
下面的网络传输流程为关键流程:
4.streamer是一个DataStreamer的实例,这是一个线程实例。大家知道HDFS中的文件数据会分成很多64M大小的block,所以在HDFS中保存文件数据第一步就是在namenode上申请一个特殊的blockID(当然还是通过RPC调用的方式)。

文件写入流程

形成的数据传输链路

链路中某一节点的前后链路
DataStreamer线程实现类最重要的方法:
public void run()
{
....//以上代码略
Packet one = null;
synchronized (dataQueue)
{
// process IO errors if any
boolean doSleep = processDatanodeError(hasError, false);
// wait for a packet to be sent.
while ((!closed && !hasError && clientRunning && dataQueue
.size() == 0) || doSleep)
{
try
{
dataQueue.wait(1000);
}
catch (InterruptedException e)
{}
doSleep = false;
}
if (closed || hasError || dataQueue.size() == 0
|| !clientRunning)
{
continue;
}
try
{
// get packet to be sent.
//从dataQueue取出package准备进行发送
one = dataQueue.getFirst();
long offsetInBlock = one.offsetInBlock;
// get new block from namenode.
if (blockStream == null)
{
LOG.debug("Allocating new block");
//这个方法很重要,后面需要详细讲述,主要的操作包含,通过RPC调用在namenode中申请新的block,以及这个block的所有副本需要保存在哪些datanode上(主要就是一个LocatedBlock对象),并建立数据传输链路。
nodes = nextBlockOutputStream(src);
this.setName("DataStreamer for file " + src
+ " block " + block);
response = new ResponseProcessor(nodes);
response.start();
}
//将用户写入的数据包括校验和信息数据通过建立的网络传输链路传输出去
blockStream.write(buf.array(), buf.position(), buf
.remaining());
//...以下代码省略
}
}
}
这里面我们首先看一下LocatedBlock这个类实现
public class LocatedBlock implements Writable
{
//...以上代码省略
//在namenode上申请的新的block
private Block b;
//这个block针对于文件的偏移量
private long offset;
//这个block的副本都存在那些datanode节点上
private DatanodeInfo[] locs;
//...以下代码省略
}
有了LocatedBlock对象的实例,client就可以与datanode节点建立传输数据的链路,上传这个block对应的真正文件数据。
关于文件上传协议细节我们会在3.2.1章节进行讨论















 1649
1649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









