






上文已经提到,HDFS中存储数据的最小单位是BLOCK,一个文件对应的所有BLOCK全部按照一定的部署策略存在于DataNode上;我们也提到namenode负责存储文件系统的元数据信息(文件目录结构,以及文件包含的所有block). 当client用户请求读取某个文件时,client首先通过RPC的方式调用NameNode上的服务模块,得到一个文件包含的所有BLOCK列表,以及这些Block所在的Datanode信息。 随后client与相应的Datanode建立链接,发送读取BLOCK的请求。
那么Namenode如何知道文件的block部署在哪台datanode上,以及它是如何管理这些信息的?
上文已经提到过几个关键类:
1.Block,BlockInfo,DataNodeID,DataNodeInfo,DataNodeDescriptor,BlockMap(重点)
Block和BlockInfo两个类前面已经有详细的说明,这里不再赘述。不过再次提醒一点,BlockInfo中有个非常关键的属性就是:triplets。
他主要负责两个功能。
1.双向链表
triplets[3*i+1] 和 triplets[3*i+2] 存储BlockInfo类型对象
这两个字段主要存储某一台DataNode机器上所有的Block列表。
2.链表
triplets[3*i] 存储DataNodeDescriptor类型的对象。
这个字段主要存储这个Block都存储在那些DataNode上。
注:这两个功能没有太大的直接联系,不要混淆。
首先了解一下几个重点类:
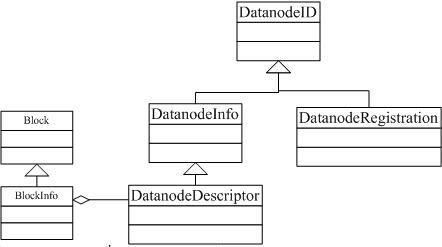
DatanodeID
public class DatanodeID
implements WritableComparable<DatanodeID>
这个类可以完全标识一个DataNode,先看一下这个类的关键字段
public String name; /// hostname:portNumber
public String storageID; //unique per cluster storageID
protected int infoPort;//the port where the infoserver is running
public int ipcPort;// the port where the ipc server is running
name直接由两个关键组成:hostname:portNumber
StorageID:表示datanode的存储ID(这部分的相关功能我们后续进行介绍)
infoPort:InfoServer所监听的端口
ipcPort:IPC服务所监听的端口
这个类包含了一个Server服务的所有网络相关信息。
DatanodeInfo
/**
* DatanodeInfo represents the status of a DataNode.
* This object is used for communication in the
* Datanode Protocol and the Client Protocol.
* 同时这个类也存储DataNode本身在网络环境的节点信息。
*/
public class DatanodeInfo extends DatanodeID implements Node
该类的关键字段:
protected long capacity;
protected long dfsUsed;
protected long remaining;
protected long lastUpdate;
protected int xceiverCount;
protected String location = NetworkTopology.DEFAULT_RACK;
另外该对象还包行两个关键字段
private int level; //which level of the tree the node resides
private Node parent; //its parent
这两个字段表示该datanode节点在网络拓扑架构中的相对位置信息。
这些字段都可以直接从字面上了解其实现的作用。
DatanodeDescriptor
public class DatanodeDescriptor extends DatanodeInfo
这个类相对来说就比较复杂一些,这个类的实例存在于Namenode Server上,保存很多实时信息,该对象包含很重要的几个。
这个类包含三个重要的内部类。
BlockIterator
BlockTargetPair
BlockQueue
BlockIterator:这个类从命名中就可以了解到,他主要的作用是对这个DataNode上所有的Block信息进行遍历,可想而知整个遍历过程借助的就是DatanodeDescriptor的private volatile BlockInfo blockList = null 这个字段, BlockInfo中的triplets[3*i+1] 和 triplets[3*i+2]。
遍历的流程如下:
首先设置迭代器中current对象为DatanodeDescriptor 中的 blockList。利用current.findDatanode(this)方法得到DatanodeDescriptor在blockInfo中 triplets数组的索引位置index,最后利用triplets[index*3+2]得到这个datanode的下一个BlockInfo,并将这个BlockInfo保存为current。
BlockTargetPair:这个类主要保存一个Block和一组DatanodeDescriptor信息。主要为了方便其他模块儿在这组datanode上进行对该Block的操作。
BlockQueue:这个类实质就是一个BlockTargetPair对象的队列。
关于这个类的详细应用我们后续进行讨论,本次主要目的就是了解block如何与datanode节点建立对应关系。
BlockMap
public class BlocksMap
下面介绍我们本节的重头戏:BlockMap,这个类虽然简单但是非常重要,它几乎贯穿于整个HDFS架构,这个类主要是对BlockInfo操作的封装。
我们看到BlockMap有两个内部类,一个就是我们先前介绍过的BlockInfo,另一个就是NodeIterator。
BlockInfo这里不在赘述。
public static class BlockInfo extends Block
NodeIterator
private static class NodeIterator implements Iterator<DatanodeDescriptor>
这个类主要作用是对某个具体block所在的所有DataNode节点信息进行遍历,其主要实现就是通过BlockInfo中的triplets[3*i] 。这部分代码比较简单,这里就不详细进行分析了。
下面看一些重要的方法。
1.
BlockInfo addINode(Block b, INodeFile iNode)
{
BlockInfo info = checkBlockInfo(b, iNode.getReplication());
info.inode = iNode;
return info;
}
这个函数主要应用在用户对新建的文件进行写操作时,Namenode需要新创建一个block来标识用户写入的数据(对应于Datanode上一个具体的block文件),一个block写满时(一般为64M),又会新建一个block标识后续用户写入的数据。这些新建的block需要添加到INodeFile中的BlockInfo数组。
loadFSImage(),这个方法同样需要进行这个函数的调用,将文件系统的元数据信息从文件镜像恢复到内存镜像。
2.
/**
* Add BlockInfo if mapping does not exist.
*/
private BlockInfo checkBlockInfo(Block b, int replication)
{
BlockInfo info = map.get(b);
if (info == null)
{
info = new BlockInfo(b, replication);
map.put(info, info);
}
return info;
}
这个方法的只要目的就是建立block到blockinfo的映射关系,往往通过网络进行RPC调用时一些参数是Block类型的。例如datanode启动时上报所有的block给namenode。因为blockinfo这个对象只是存在于Namenode Server上的。
3.
/** Returns the block object it it exists in the map. */
BlockInfo getStoredBlock(Block b)
{
return map.get(b);
}
通过一个block对象,返回Namenode上与之对应的blockinfo对象。
4.
Iterator<DatanodeDescriptor> nodeIterator(Block b)
{
return new NodeIterator(map.get(b));
}
返回上述提到的一个DatanodeDescriptor迭代器,遍历存储同一个block的所有datanode信息。
这个函数主要是应用于用户通过client对HDFS中的文件进行读取的过程,Namenode会返回一系列包含block以及datanodeinfo[] 的对象。 其中的datanodeinfo数组就是通过这个迭代器获取的所有datanode列表。
5.
/**
* Remove the block from the block map; remove it from all data-node lists
* it belongs to; and remove all data-node locations associated with the
* block.
*/
void removeBlock(BlockInfo blockInfo)
{
if (blockInfo == null)
return;
blockInfo.inode = null;
for (int idx = blockInfo.numNodes() - 1; idx >= 0; idx--)
{
DatanodeDescriptor dn = blockInfo.getDatanode(idx);
dn.removeBlock(blockInfo); // remove from the list and wipe the
// location
}
map.remove(blockInfo); // remove block from the map
}
应用于namesystem.commitBlockSynchronization函数中,调用这个函数的主要原因是系统主动调用recoverBlock方法。
6.
void removeINode(Block b)
{
BlockInfo info = map.get(b);
if (info != null)
{
info.inode = null;
if (info.getDatanode(0) == null)
{ // no datanodes left
map.remove(b); // remove block from the map
}
}
}
该方法主要应用于:用户创建文件后,准备对文件进行写操作,首先需要在namenode添加注册新的block,并添加到INodeFile对象的block数组中,然后与多个datanode尝试创建写block的管道,如果创建失败,就调用该方法将上一步,目的就是删除第一步新注册的block。
同时,该方法还应用于用户删除文件操作。
7.
boolean removeNode(Block b, DatanodeDescriptor node)
{
BlockInfo info = map.get(b);
if (info == null)
return false;
// remove block from the data-node list and the node from the block info
boolean removed = node.removeBlock(info);
if (info.getDatanode(0) == null // no datanodes left
&& info.inode == null)
{ // does not belong to a file
map.remove(b); // remove block from the map
}
return removed;
}
该方法从参数就可以看出,被调用的主要原因就是某一个DataNode节点失效,或者某个DataNode节点的某个具体block失效。















 8751
8751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









