







作者:travelsea
链接:https://zhuanlan.zhihu.com/p/22045213
来源:知乎
近些年来,深度卷积神经网络(DCNN)在图像分类和识别上取得了很显著的提高。回顾从2014到2016这两年多的时间,先后涌现出了R-CNN,Fast R-CNN, Faster R-CNN, ION, HyperNet, SDP-CRC, YOLO,G-CNN, SSD等越来越快速和准确的目标检测方法。
1, 基于Region Proposal的方法
该类方法的基本思想是:先得到候选区域再对候选区域进行分类和边框回归。
1.1 R-CNN [1]
R-CNN是较早地将DCNN用到目标检测中的方法。其中心思想是对图像中的各个候选区域先用DCNN进行特征提取并使用一个SVM进行分类,分类的结果是一个初略的检测结果,之后再次使用DCNN的特征,结合另一个SVM回归模型得到更精确的边界框。
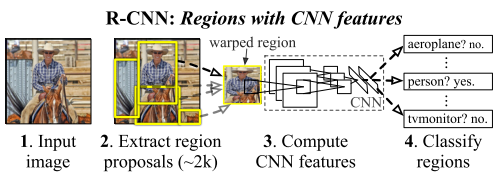
其中获取候选区域的方法是常用的selective search。 一个图形中可以得到大约2000个不同大小、不同类别的候选区域,他们需要被变换到同一个尺寸以适应CNN所处理的图像大小( 227×227 )。
该文章中使用的CNN结构来自AlexNet,已经在ImageNet数据集上的1000个类别的分类任务中训练过,再通过参数微调使该网络结构适应该文章中的21个类别的分类任务。
该方法在VOC 2011 test数据集上取得了71.8%的检测精度。该方法的缺点是:1,训练和测试过程分为好几个阶段:得到候选区域,DCNN 特征提取, SVM分类、SVM边界框回归,训练过程非常耗时。2,训练过程中需要保存DCNN得到的特征,很占内存空间。3, 测试过程中,每一个候选区域都要提取一遍特征,而这些区域有一定重叠度,各个区域的特征提取独立计算,效率不高,使测试一幅图像非常慢。
1.2 Fast R-CNN[2]
在R-CNN的基础上,为了使训练和测试过程更快,Ross Girshick 提出了Fast R-CNN,使用VGG19网络结构比R-CNN在训练和测试时分别快了9倍和213倍。其主要想法是: 1, 对整个图像进行卷积得到特征图像而不是对每个候选区域分别算卷积;2,把候选区域分类和边框拟合的两个步骤结合起来而不是分开做。原理图如下:
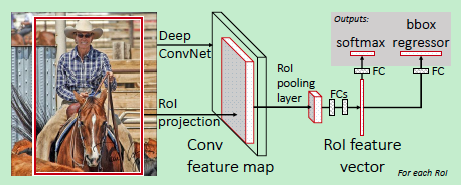
该文章中使用ROI Pooling Layer 将不同大小的候选区域的特征转化为固定大小的特征图像,其做法是:假设候选区域ROI的大小为 h×w , 要输出的大小为 H×W ,那么就将该ROI分成 H×W 个格子,每一个格子的大小为 (h/H)×(w/W)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 6392
6392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









