







 深度对抗学习(adversarial learning)为解决深度学习模型的过度拟合和特征学习问题提供了新思路。在图像分割中,对抗网络改善了像素级别的连续性和对象的一致性;在半监督学习中,对抗学习通过未标记数据进行规则化,提升性能;在域适应中,通过特征提取网络与判别器对抗,减少域间差异;在高分辨率图像重建中,SRGAN结合对抗学习避免过度平滑,增强细节真实性。
深度对抗学习(adversarial learning)为解决深度学习模型的过度拟合和特征学习问题提供了新思路。在图像分割中,对抗网络改善了像素级别的连续性和对象的一致性;在半监督学习中,对抗学习通过未标记数据进行规则化,提升性能;在域适应中,通过特征提取网络与判别器对抗,减少域间差异;在高分辨率图像重建中,SRGAN结合对抗学习避免过度平滑,增强细节真实性。
深度学习已经在图像分类、检测、分割、高分辨率图像生成等诸多领域取得了突破性的成绩。但是它也存在一些问题。首先,它与传统的机器学习方法一样,通常假设训练数据与测试数据服从同样的分布,或者是在训练数据上的预测结果与在测试数据上的预测结果服从同样的分布。而实际上这两者存在一定的偏差,比如在测试数据上的预测准确率就通常比在训练数据上的要低,这就是过度拟合的问题。
另一个问题是深度学习的模型(比如卷积神经网络)有时候并不能很好地学到训练数据中的一些特征。比如,在图像分割中,现有的模型通常对每个像素的类别进行预测,像素级别的准确率可能会很高,但是像素与像素之间的相互关系就容易被忽略,使得分割结果不够连续或者明显地使某一个物体在分割结果中的尺寸、形状与在金标准中的尺寸、形状差别较大。
对抗学习
对抗学习(adversarial learning)就是为了解决上述问题而被提出的一种方法。学习的过程可以看做是我们要得到一个模型(例如CNN),使得它在一个输入数据X上得到的输出结果 Yp 尽可能与真实的结果Y(金标准)一致。在这个过程中使用一个鉴别器(discriminator),它可以识别出一个结果y到底是来自模型的预测值还是来自真实的结果。如果这个鉴别器的水平很高,而它又把 Yp 和Y搞混了,无法分清它们之间的区别,那么就说明我们需要的模型具有很好的表达或者预测能力。本文通过最近的几篇文章来介绍它在图像分割和高分辨率图像生成中的应用。
用于图像分割
Semantic Segmentation using Adversarial Networks (arxiv, 25Nov 2016)这篇文章第一个将对抗网络(adversarial network)应用到图像分割中,该文章中的方法如下图。
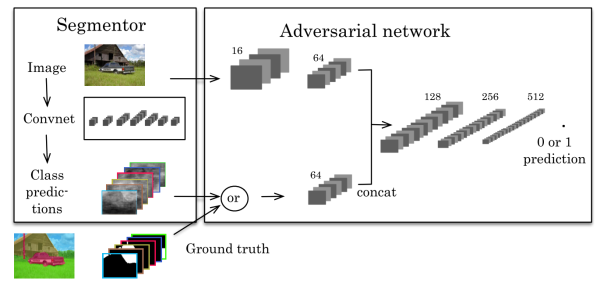
左边是一个CNN的分割模型,右边是一个对抗网络。对抗网络的输入有两种情况,一是原始图像+金标准,二是原始图像+分割结果。它的输出是一个分类值(1代表它判断输入是第一种情况,0代表它判断输入是第二种情况)。代价函数定义为:
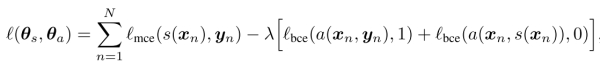
其中 θs 和 θa 分别是分割模型和对抗模型的参数。 yn 是金标准, s(xn) 是分割结果。上式第一项是经典的分割模型的代价函数,例如交叉熵(cross entropy)即概率值的负对数。第二项和第三项是对抗模型的代价函数,由于希望对抗模型尽可能难以判别 yn 和 s(xn) , 第二项的权重是 −λ 。
训练过程中,交替训练对抗模型( θa )和分割模型( θs )。训练对抗模型的代价函数为:
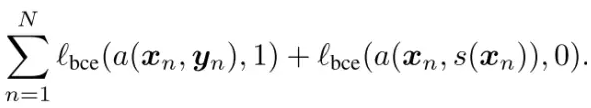
使该函数最小化,得到性能尽可能好的判别器,即对抗模型。训练分割模型的代价函数为:
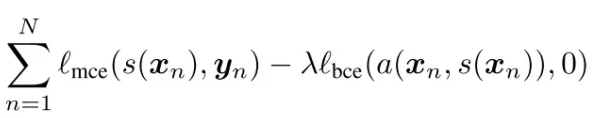
一方面使
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 125
125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









