






题外补充:deklarativ(declarative)
一直不是很清楚deklarativ是什么意思,所以在这里补充一下:
deklarativ中文是声明的意思。他与process相对应。他关注的问题是was(what)而不是wie(how)。也就是说一个deklarativ过程(Deklarative Vorgehensweise)是对预期结果的属性的一个描述,而不是对为获得预期结果的方法的描述。同样的在一个访问语言中,我们希望存在尽可能多得deklarativ方法,同时尽可能少的operationell方法。
对于访问的要求
简单的OEM示例
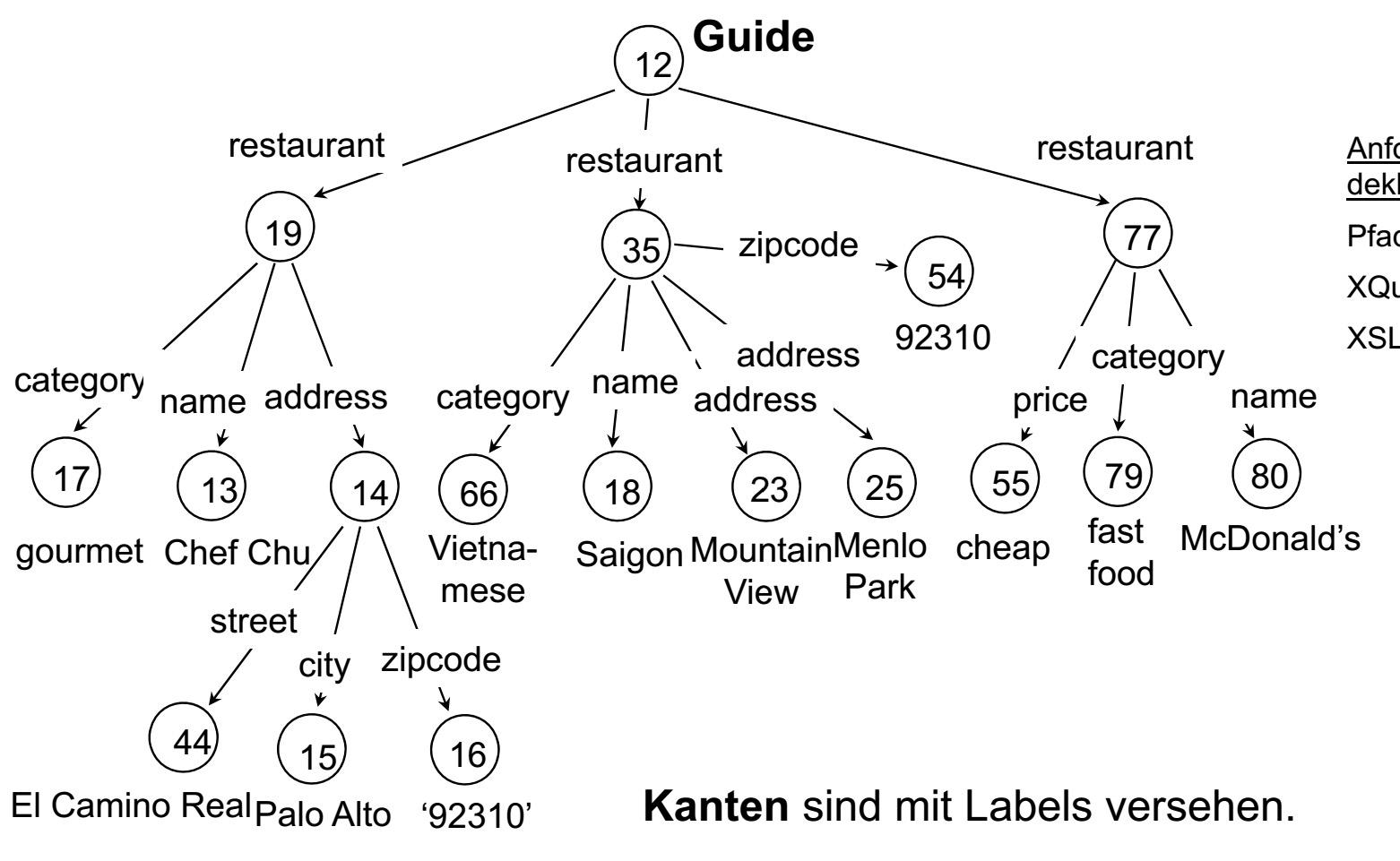
上图是一个一般的半结构化文档。我们可以发现其中有很多不规则的地方,比如:
1. 餐厅可以由任意多个地址
2. 地址即可以处于叶子节点上,也可以处于内部节点上
3. zipcode有时是restaurant的组成成分,有时确实address的组成成分
从这个例子中我们可以看出:
1. 有时我们会要求能够进行模糊一些的搜索,比如我们要获得所有的zipcode,不管他是不是属于restaurant的直接组成成分。而这要求我们的访问方法,具有一定的概括能力。
2. 另外,有时我们会想对上述中的情况进行区分,比如,我就要属于restaurant的直接组成成分的哪个zipcode,其他的我不来电。这又要求我们的访问方法能够进行精确的表达。(当然,这的前提是用户认识这个结构)
访问语言的具体要求
说了那么多,我们对这个声明性的访问的要求,究竟是神马呢??
1. 表达能力强(Ausdrucksmächtigkeit)
2. 语义(Semantik)//不知啥意思??
3. 可互相组合的能力(Zusammensetzbarkeit)
4. 样式(Schema)//还是不懂这个???
5. 对于给定的要求容易生成对应的语句(Einfache Erzeugbarkeit von Anfragen aus Programm)
接下来一个一个的探探:
表达能力强:
对于表达能力我们的最低要求是,关系模型访问语言能做到的,这里都能够做到
另外这个语言除了应该有强的表达能力,还应注意这个能力又不能够太强(我去啊,Sprache sollte ausdrucksmächtig sein, aber nicht zu ausdrucksmächtig)
具体的原因有两个:
1. 表达能力太强的话,有时会难以进行优化???
(Regel:Selektion und Join i.Allg. vertauschbar)
2. 他不能保证执行时间。
Semantik:
(Genaue Definition der Semantik ist erforderlich)
估计是指语句不要出现歧义
语句容易生成
要求语言精练简洁
老师的意思是,这并不是针对这个访问语言的属性,而首先是这个开发环境的属性。
“Karg, aber einfach”
MMn keine Eigenschaft der Anfragesprache, sondern in erster Linie der Entwicklungsumgebung.
Schema:
结构意识,同样这个也不是针对访问语言的,而是针对具体实现的。
“Stucutre-Consciousness”
Keine Eigenschaft der Querysprache, sondern der Implementierung.
//既然不是针对语言的干嘛要编排在这里啊??
例子:
假设Schema告诉我们了:
1. 只有直接位于根节点下面的book元素才含有zip元素
2. zip元素总是直接跟在address元素或book元素的后面
那么我们就可以得到,下面的两种说法是等价的:
1.
select X.title
from biblio.book X
where X.address.zip = “12345”
2.
select X.title
from biblio.* X
where X.*.zip = “12345”
上例说明了Schema的重要性(第一种方法比第二种快)。而且在这里确实和访问语言无关啊。
Im Fall von Tiefensuche fokusierte (und damit i.d.R. schnellere) Suche.
Beispiel setzt speziellen Ablauf beim Query Processing voraus, das muss aber i. Allg. nicht so sein.???
Zusammensetzbarkeit:
/*???
Identisch mit “Abgeschlossenheit”
Gegenbeispiel:Querysprache LOREL erzeugt Relationen aus OEM-Instanz,d.h. LOREL genügt der Anforderung nicht.
Konsequenz auf der syntaktischen Ebene:
“Referentielle Transparenz”
Name,Variable für semistrukturierte Daten
↔
Ausdruck
*/
-S20
XPath
先看一下OEM的路径
标签路径(Label Path)
在OEM中可以用标签序列(Folge von Labels:l1..ln)表示一个OEM中的对象o的标签路径。用 Ii 来表示到对象 oi 的边(Label),每个标签之间用“.”区分开。
数据路径(Data Path)
同样的我们也可以用标签和元素对象ID的交替序列对路径来表示数据对象o的数据路径,同样的我们需要“.”来对他们进行区分
我们说一个数据路径是标签路径的一个实例,当他们中间的标签序列是一致的时候。(Ein Data Path d ist Instanz eines Label Paths l, wenn die Folgen der Labels übereinstimmen.)
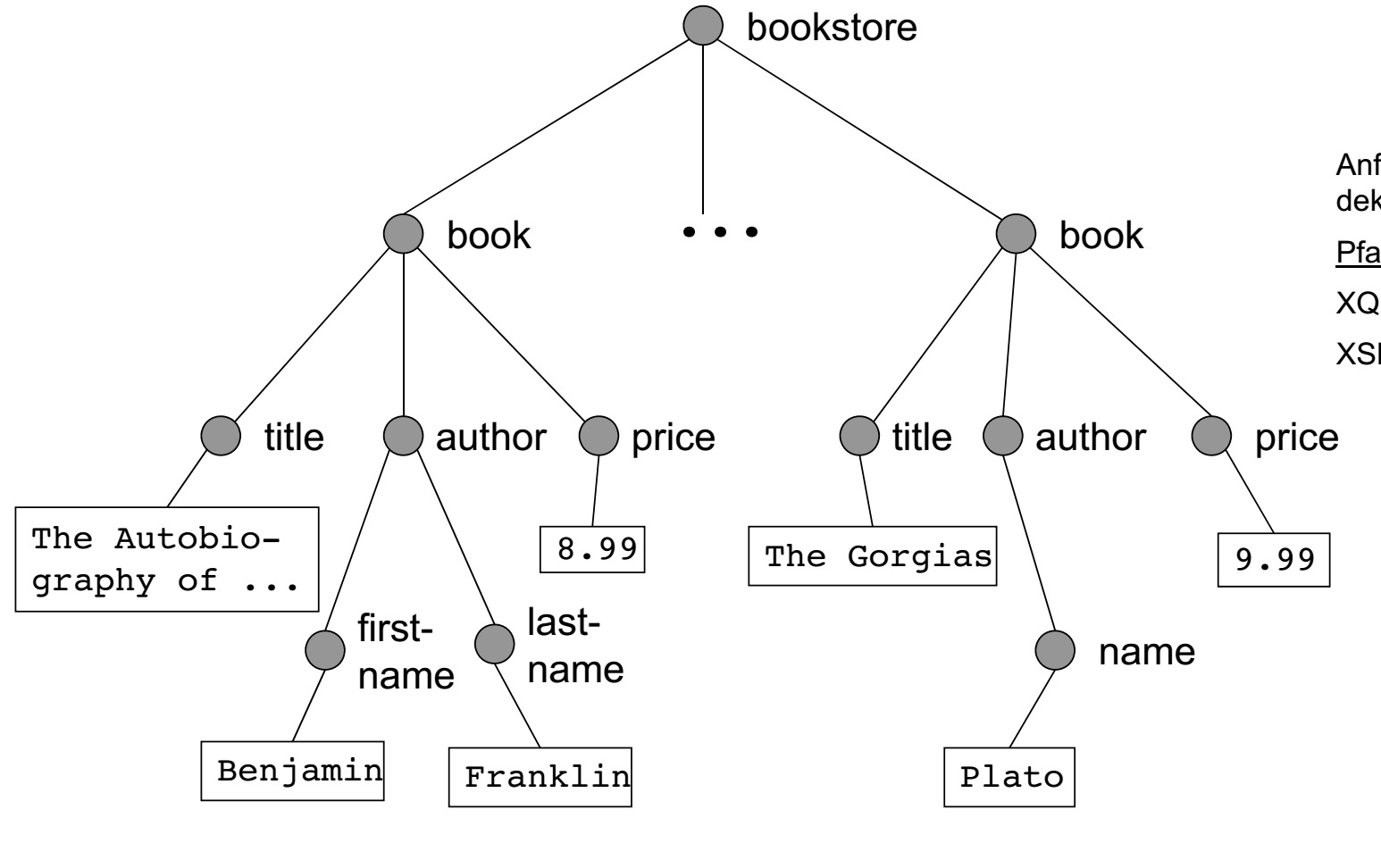
//这个图中有哪些是’bookstore.book.title’的实例呢???
目标集(Target Set)
我们用下面的式子定义元素s对应标签路径I的目标集(Das Target Set in einem Element s von einem label path l von s ist die Menge):
XPath产生的动机
目的是可以定位数据库中任意位置的数据
(Motivation:Adressierung beliebiger logischer Dokumentbestandteile)
XPath并不是XML的语法
(XPath-Standardisieung im XML-Kontext???d.h. Knoten sind markiert)
XPath的两种路径
区分两种不同的路径:
相对路径(Relativer Pfadausdruck):
与当前位置相关
(Auswertung beginnt an aktueller Position im Dokument; Ergebnis also kontextabhängig)
绝对路劲(Absoluter Pfadausdruck):
与绝对地址相关,与上下文无关
(Auswertung beginnt an absoluter Position im Dokument. Ergebnis also stets dasselbe, unabhängig vom Kontext.)
XPath的一些常用的表示
title或./title:当前元素下的所有的Title(注不限一个)
author/name/firstname:(这里的author要求是当前元素下的吗???)
//title:文档中的所有title(不限位置)
buch/*: buch元素的所有孩子
buch/@*: buch的所有属性(包括属性名和属性值)
preis/@waehrung: preis的所有waehrung属性
buch[Zusammenfassung]:得到所有包含有Zusammenfassung的buch(如buch[title])??
buch[Zusammenfassung]/title:得到上面得到的buch的title
autor[firstname = “Hans”],autor[string(firstname)=”Hans”]:
autor[(titel $or$ auszeichnung)]:关注的是中间的or,表示或的意思,另外前面的$符号和括号的可以省略的
my_namespace:*: 元素my_namespace下的所有元素(注与前面的区别,前面那个只有孩子)??
book[@genre=./author/@pipapo]/title等价于book[@genre=author/@pipapo]/title:
//book[.//firstname]: 输出所有含有firstname元素的book元素
//book[//firstname]:当文件中含有firstname的时候,输出所有的book元素
//buch[./buchladen/@spezialität=@gattung]:
book[price<10]//title:
book[price<10]/*/name:
book[title <= “The B”]/title:
book/author[first-name and last-name]:
后面几个会输出什么呢???
book[author/first-name and author/last-name]/title:
中括号是可以嵌套的,括号直接指代括号邻近的那个元素//不十分肯定?
(Schachtelung der eckigen Klammern ist möglich, Klammern beziehen sich auf das unmittelbar vorangegangene Element.)
book[author[first-name and last-name]]/title:
book[.//name=”Plato”]/title:
book/@genre:
book[@genre=”novel”]/title:
book[@genre=./author/@pipapo]/title:
最后一个会输出什么呢??
Location Paths
Location Paths由Location Steps组成
而Location Steps由下面三个部分组成:
1.轴axis(Achse)//这翻译??
2.Node Test
3.谓词(Prädikaten)
比如:/descendant::figure[position()=42]
其中/descendant::为轴
figure为Node Test
[position()=42]为谓词
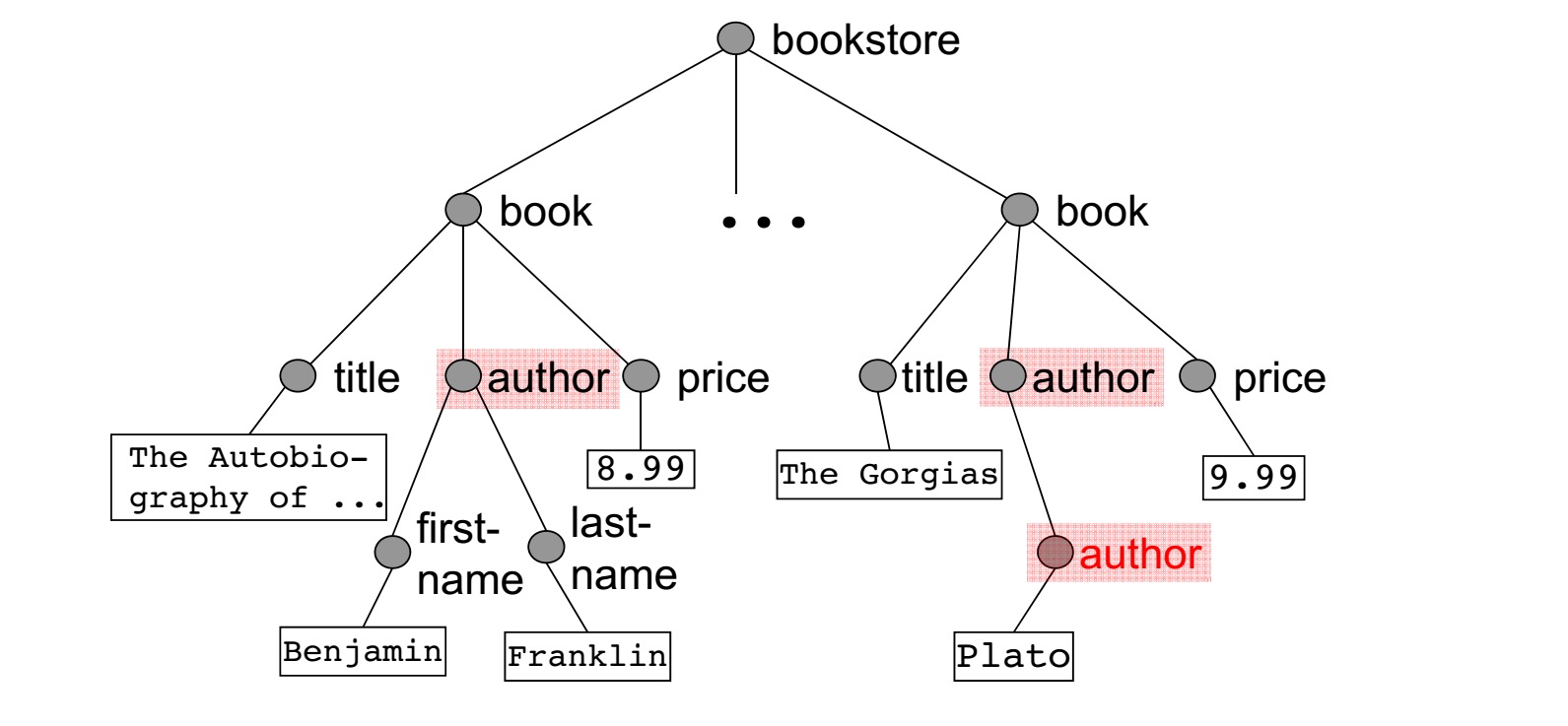
路径表达的每一步的结果都是按文档序排序的元素的列表。那么
(doucument(“report1.xml”)//action)[price<10][position()<=2]
对应输出的结果是神马呢??
//position和sequence of Items有关???这个不懂??
(Kontext-Position bezieht sich auf sequence of items.)
把两个中括号的内容给对换过来,结构还一样吗??
另一个例子:
文档:
<A:T>bla</A:T><B:T>blubb</B:T>
<script id="MathJax-Element-175" type="math/tex">
bla
blubb
</script>
表示不同namespace中的T元素
那么问题来了,我们应该如何获得所有的叫做T的元素呢??
//.[local-name(.)=”T”]
还是例子:
1. 请输出所有的书元素,并且要求这个元素直接或间接的包含有firstname这个元素
2. 作者Plato的所有书的价格
//book[.//firstname]
//book[author/name=”Plato”]/price
XPath中的绝对的和相对的定位符(absolute und relative Lokator-Terme)
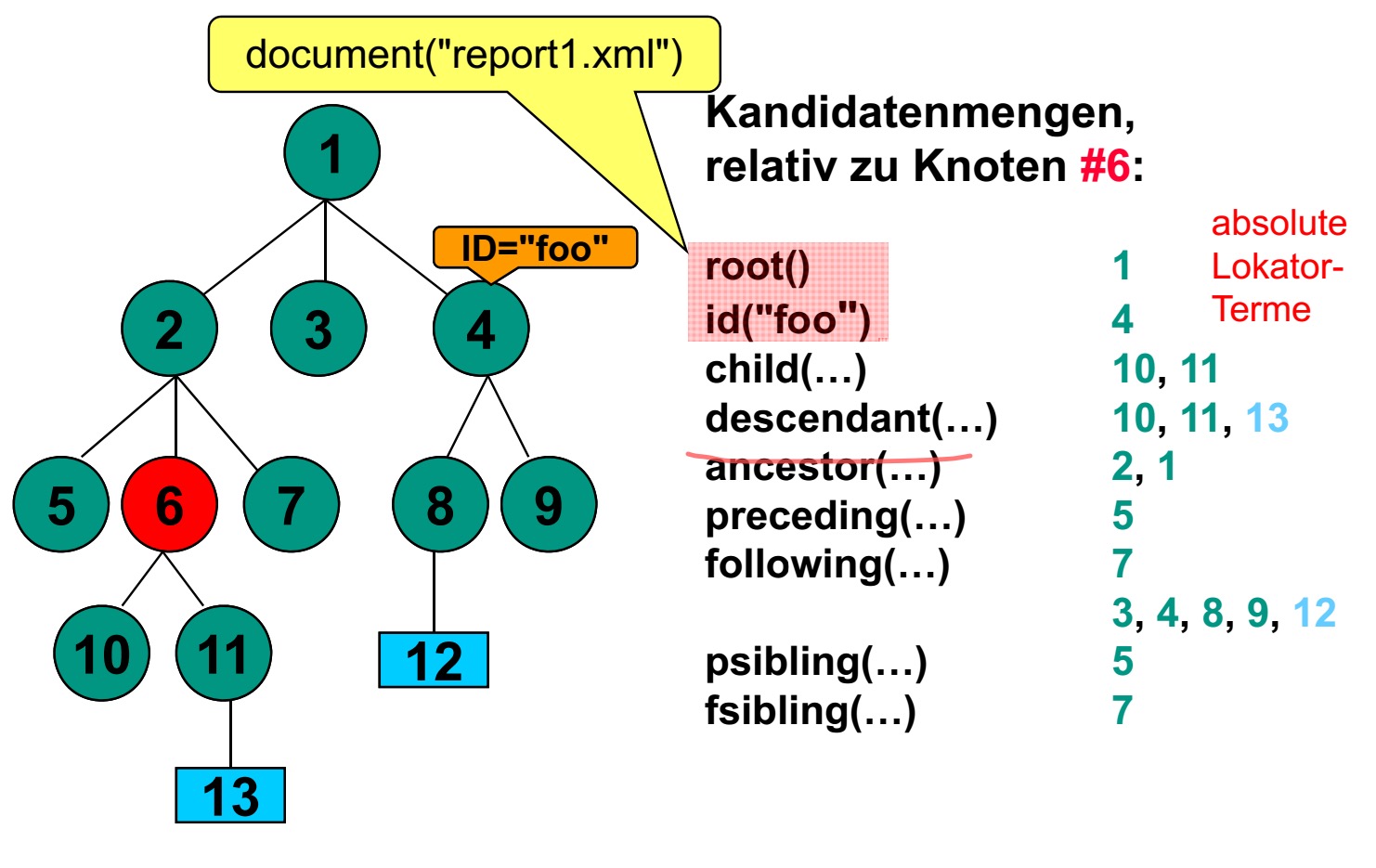
//本来想只截树图的,结果果然还是这样省事啊
用XPath实现Join
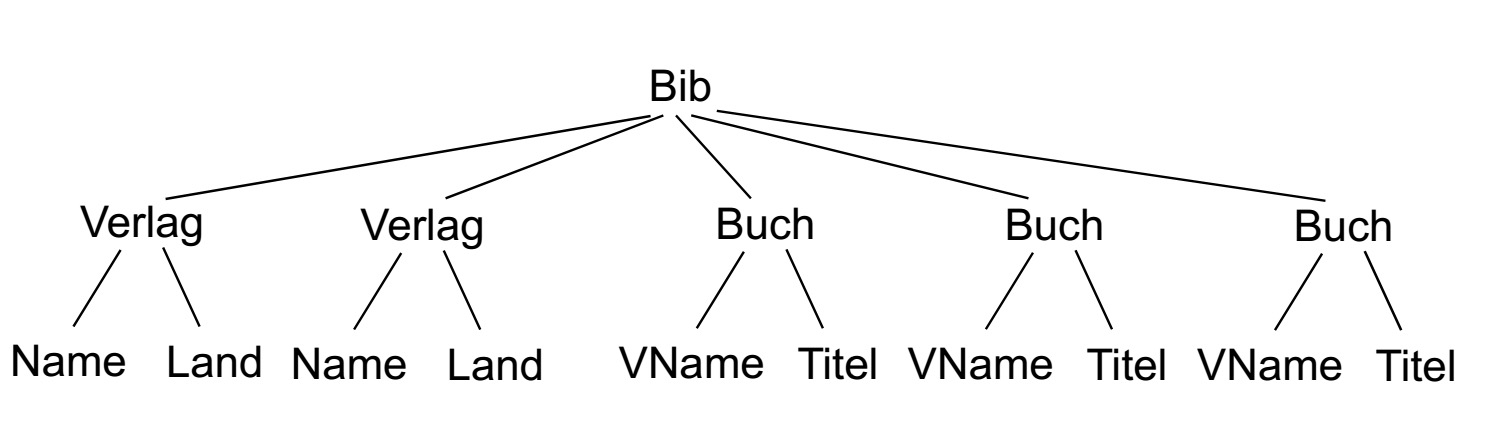
输出有德国verlag出版的所有的书的书名:
/Bib/Book[Verlag_name=/Bib/Verlag[Land=”Germany“]/Name]/title
在上面这个问题中,book和verlag也可以分别存储在不同的文档中。
仅仅用XPath的话没办法实现输出所有的(Land,Titel)对
(Es funktioniert-nur mit XPath-jedoch nicht:Ausgabe aller(Land,Titel)-Paare)
XML Schema:一致性的条件(Polymorphe Konsistenzbedingungen)
目的:特定的值(或不同值之间的组合)应该是唯一的//不确定啊???
(Ziel:Bestimmte Werte(bzw. Kombinatinen von Werten sollen eindeutig sein(Uniqueness Constraint.)))
步骤:
1.标识有唯一性要求的元素
2.标识这些元素对应的属性值,如果他们也有唯一性的要求的话
3.确定在那些上下文环境(context)中,这些元素是需要保持其唯一性
(Elemente,für die Attributwert(e) eindeutig sein sollen, sind stets Tupel.??)
举个例子:
Personen的Vorname和Nachname元素的组合在xxx中必须是唯一的
其中:
Personen是Selector-Element。也就是上面说得context(在Relation中没有对应的元素,感觉有点对应关系的名字??)
(Selector-Element hat keine Entsprechung im Relationalen)
Vorname和Nachname的组合是Field-Element
Selector-Element和Field-Element总是成对出现的)
(Elemente, f[r die Attributwert(e) eindeutig sein sollen, sind stets Tupel. Dto. Kontext-Relationen)

除了上面这种方法之外,我们还可以使用key condition(Schlüsselbedingung)来实现
<key name="papierSchlüssel">
<script id="MathJax-Element-176" type="math/tex">
</script>
<field xpath="bib/paper/@id"/>
</key>
<script id="MathJax-Element-178" type="math/tex"></script>
把paper中的id属性作为key。key是必须唯一的,且是可以被引用的
<keyref name="papierFremdschlüssel" refer="papierSchlüssel">
<script id="MathJax-Element-179" type="math/tex">
</script>
<field xpath="bib/paper/@references"/>
</keyref>
<script id="MathJax-Element-181" type="math/tex"></script>
值的注意一下的是refer是和name这个属性相关联的。(Beachte:Mit refer bezieht man sich auf das name-Attribut einer Schlüsselbedingung, nicht auf das Schlüsselfeld)
references对应的值,应该可以在key中找到(Die Werte in references müssen also immer unter den Schlüsseln zu den Papieren zu finden sein.)















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









