




 本文介绍了中文处理中的基础概念,包括马尔科夫链和隐马尔科夫模型(HMM)。马尔科夫链是一种状态仅依赖于前一个状态的随机过程。HMM则用于词性标注,包含观察状态、隐藏状态和两组概率。通过前向-后向算法和维特比算法可以实现评估和解码,但HMM模型存在上下文信息处理的局限性。
本文介绍了中文处理中的基础概念,包括马尔科夫链和隐马尔科夫模型(HMM)。马尔科夫链是一种状态仅依赖于前一个状态的随机过程。HMM则用于词性标注,包含观察状态、隐藏状态和两组概率。通过前向-后向算法和维特比算法可以实现评估和解码,但HMM模型存在上下文信息处理的局限性。
基于统计的语言模型比基于规则的语言模型有着天然的优势,而(中文)分词是自然语言处理的基础,接下来我们将注重介绍基于统计的中文分词及词性标注技术。为此做以下安排:首先介绍一下中文处理涉及到基本概念,接着分析开源的一些基于统计的中文分词原理。
中文分词涉及的基本概念有马尔科夫链,隐马尔科夫模型(HMM),Ngram模型,最大熵马尔科夫模型(MEMM),条件随机场(CRF)等
1、马尔科夫链
通俗讲马尔科夫链是指在某一状态空间序列中,当前的状态只与它前面n(n=1,2,……)个状态相关。
具体定义如下:
马尔科夫链指具有马尔科夫性质的随机变量X1, X2, X3,…序列,即将来的状态只与当前的状态相关,而与过去的状态无关。
用数学公式表示如下
Pr (Xn+1=|X1=x1,X2=x2, …, Xn=xn) = Pr (Xn+1=x|Xn=xn)
Xn(n=1,2,3,…)表示所有可能取值的集合,被称为“状态空间”,而Xn的值则是在时间n的状态
马尔科夫链通常被描述成一个有向图,其中状态表示图的顶点,状态转移概率表示图的边。如图1所示。
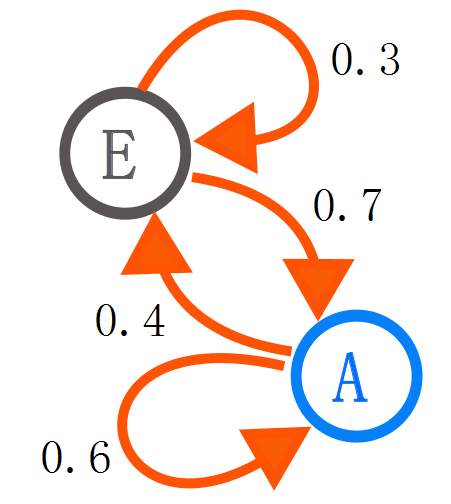
图1-两个状态的马尔科夫链
2、隐马尔科夫模型<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









