









案例要实现的目标
在Kafka的shell 客户端中输入内容,通过Storm实时去kafka中取数据并进行计算单词出现的次数,并且实时把这些数据信息存储到redis中。
代码编写
编写Pom文件,代码如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.toto.storm.kafkastormredis</groupId>
<artifactId>kafkastormredis</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<!--<scope>provided</scope>-->
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.8.2</artifactId>
<version>0.8.1</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!--告诉运行的主类是哪个,注意根据自己的情况,下面的包名做相应的修改-->
<mainClass>cn.toto.strom.wordcount.StormTopologyDriver</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
</project>在strom案例中需要有spout接收数据。在一些常规学习用的案例中通常从一个文件中获取数据。通常的代码如下:
package cn.toto.storm.kafkastormredis;/**
* Created by toto on 2017/6/20.
*/
import org.apache.commons.lang.StringUtils;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* 这个类是模拟从文件中读取数据的代码。在本案例的strom + kafka + redis的案例中将用不到。
*
* @author tuzq
* @create 2017-06-20 23:41
*/
public class MyLocalFileSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private BufferedReader bufferedReader;
/**
* 初始化方法
* @param map
* @param context
* @param collector
*/
@Override
public void open(Map map, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
try {
this.bufferedReader = new BufferedReader(new FileReader(new File("E:/wordcount/input/1.txt")));
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* Strom实时计算的特性就是对数据一条一条的处理
* while(true) {
* this.nextTuple();
* }
*/
@Override
public void nextTuple() {
//每被调用一次就会发送一条数据出去
try {
String line = bufferedReader.readLine();
if (StringUtils.isNotBlank(line)) {
List<Object> arrayList = new ArrayList<Object>();
arrayList.add(line);
collector.emit(arrayList);
}
} catch(Exception e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("juzi"));
}
}
在spout编写完成之后,通常通过Bolt来进行文本的切割。在下面的切割代码中,模拟的是从kafka中获取数据,并进行切割。代码如下:
package cn.toto.storm.kafkastormredis;/**
* Created by toto on 2017/6/21.
*/
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* 这个Bolt模拟从kafkaSpout接收数据,并把数据信息发送给MyWordCountAndPrintBolt的过程。
*
* @author tuzq
* @create 2017-06-21 9:14
*/
public class MySplitBolt extends BaseBasicBolt {
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
//1、数据如何获取
//如果StormTopologyDriver中的spout配置的是MyLocalFileSpout,则用的是declareOutputFields中的juzi这个key
//byte[] juzi = (byte[]) input.getValueByField("juzi");
//2、这里用这个是因为StormTopologyDriver这个里面的spout用的是KafkaSpout,而KafkaSpout中的declareOutputFields返回的是bytes,所以下面用bytes,这个地方主要模拟的是从kafka中获取数据
byte[] juzi = (byte[]) input.getValueByField("bytes");
//2、进行切割
String[] strings = new String(juzi).split(" ");
//3、发送数据
for (String word : strings) {
//Values对象帮我们生成一个list
collector.emit(new Values(word,1));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word","num"));
}
}
对文本信息进行切割之后,需要对数据进行统计,这里使用另外一个Bolt来完成,代码如下:
package cn.toto.storm.kafkastormredis;/**
* Created by toto on 2017/6/21.
*/
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple;
import redis.clients.jedis.Jedis;
import java.util.HashMap;
import java.util.Map;
/**
* 用于统计分析,并且把统计分析的结果存储到redis中。
*
* @author tuzq
* @create 2017-06-21 9:22
*/
public class MyWordCountAndPrintBolt extends BaseBasicBolt {
private Jedis jedis;
private Map<String,String> wordCountMap = new HashMap<String,String>();
@Override
public void prepare(Map stormConf, TopologyContext context) {
//连接redis---代表可以连接任何事物
jedis = new Jedis("hadoop11",6379);
super.prepare(stormConf,context);
}
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String word = (String) input.getValueByField("word");
Integer num = (Integer) input.getValueByField("num");
//1、查看单词对应的value是否存在
Integer integer = wordCountMap.get(word) == null ? 0 : Integer.parseInt(wordCountMap.get(word));
if (integer == null || integer.intValue() == 0) {
wordCountMap.put(word,num + "");
} else {
wordCountMap.put(word,(integer.intValue() + num) + "");
}
//2、保存到redis
System.out.println(wordCountMap);
//redis key wordcount:-->Map
jedis.hmset("wordcount",wordCountMap);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
//todo 不需要定义输出的字段
}
}
接下来通过一个Driver串联起Spout、Bolt实现实时计算,代码如下:
package cn.toto.storm.kafkastormredis;/**
* Created by toto on 2017/6/21.
*/
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.kafka.KafkaSpout;
import org.apache.storm.kafka.SpoutConfig;
import org.apache.storm.kafka.ZkHosts;
import org.apache.storm.topology.TopologyBuilder;
/**
* 这个Driver使Kafka、strom、redis进行串联起来。
*
* 这个代码执行前需要创建kafka的topic,创建代码如下:
* [root@hadoop1 kafka]# bin/kafka-topics.sh --create --zookeeper hadoop11:2181 --replication-factor 1 -partitions 3 --topic wordCount
*
* 接着还要向kafka中传递数据,打开一个shell的producer来模拟生产数据
* [root@hadoop1 kafka]# bin/kafka-console-producer.sh --broker-list hadoop1:9092 --topic wordCount
* 接着输入数据
*
* @author tuzq
* @create 2017-06-21 9:39
*/
public class StormTopologyDriver {
public static void main(String[] args) throws Exception {
//1、准备任务信息
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout("KafkaSpout",new KafkaSpout(new SpoutConfig(new ZkHosts("hadoop11:2181"),"wordCount","/wordCount","wordCount")),2);
topologyBuilder.setBolt("bolt1",new MySplitBolt(),4).shuffleGrouping("KafkaSpout");
topologyBuilder.setBolt("bolt2",new MyWordCountAndPrintBolt(),2).shuffleGrouping("bolt1");
//2、任务提交
//提交给谁?提交内容
Config config = new Config();
config.setNumWorkers(2);
StormTopology stormTopology = topologyBuilder.createTopology();
//本地模式
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("wordcount",config,stormTopology);
//集群模式
//StormSubmitter.submitTopology("wordcount1",config,stormTopology);
}
}运行程序
1、启动Kafka集群,启动方式参考博文:
http://blog.csdn.net/tototuzuoquan/article/details/73430874
2、启动redis,启动和安装方式参考博文:
http://blog.csdn.net/tototuzuoquan/article/details/43611535
3、在kafka上创建topic,参考博文:
http://blog.csdn.net/tototuzuoquan/article/details/73432256
这里我们使用:
//创建kafka的topic
[root@hadoop1 ~]# cd $KAFKA_HOME
[root@hadoop1 kafka]# bin/kafka-topics.sh --create --zookeeper hadoop11:2181 --replication-factor 1 -partitions 3 --topic wordCount接下来创建producer,来发送数据到kafka:
[root@hadoop1 kafka]# bin/kafka-console-producer.sh --broker-list hadoop1:9092 --topic wordCount在上面输入数据。
4、运行程序,进入StormTopologyDriver,右键run.最后的效果如下:
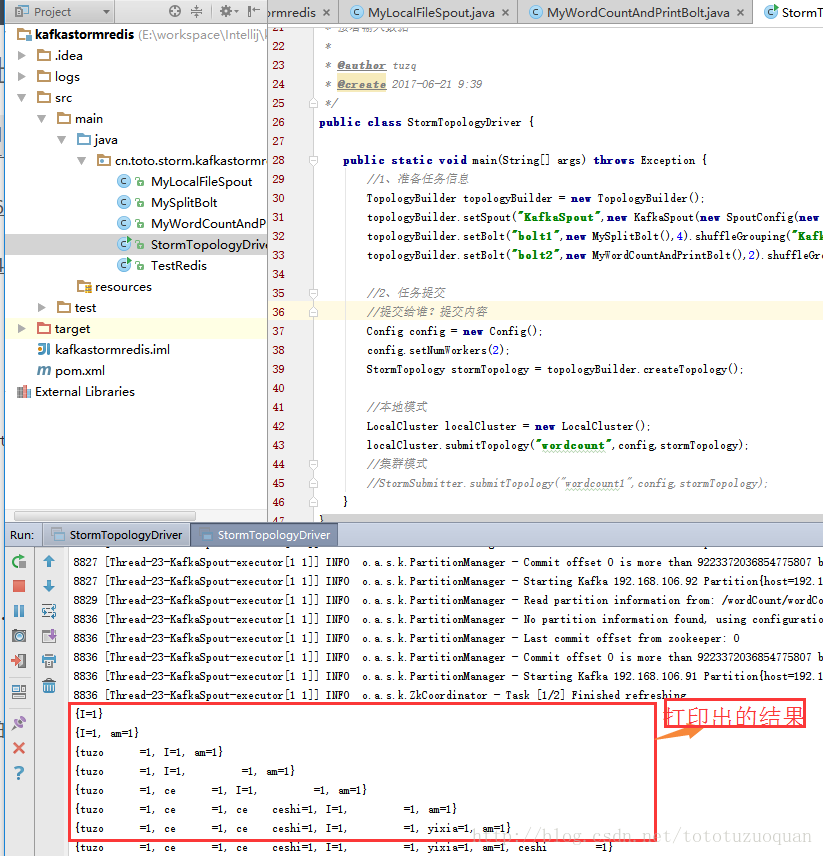
5、最后如果想看MyWordCountAndPrintBolt中记录到redis的wordcount内容,可以编写如下代码案例:
package cn.toto.storm.kafkastormredis;/**
* Created by toto on 2017/6/21.
*/
import redis.clients.jedis.Jedis;
import java.util.Map;
/**
* 代码说明
*
* @author tuzq
* @create 2017-06-21 10:13
*/
public class TestRedis {
public static void main(String[] args) {
Jedis jedis = new Jedis("hadoop11",6379);
Map<String,String> wordcount = jedis.hgetAll("wordcount");
System.out.println(wordcount);
}
}
运行后的结果如下:
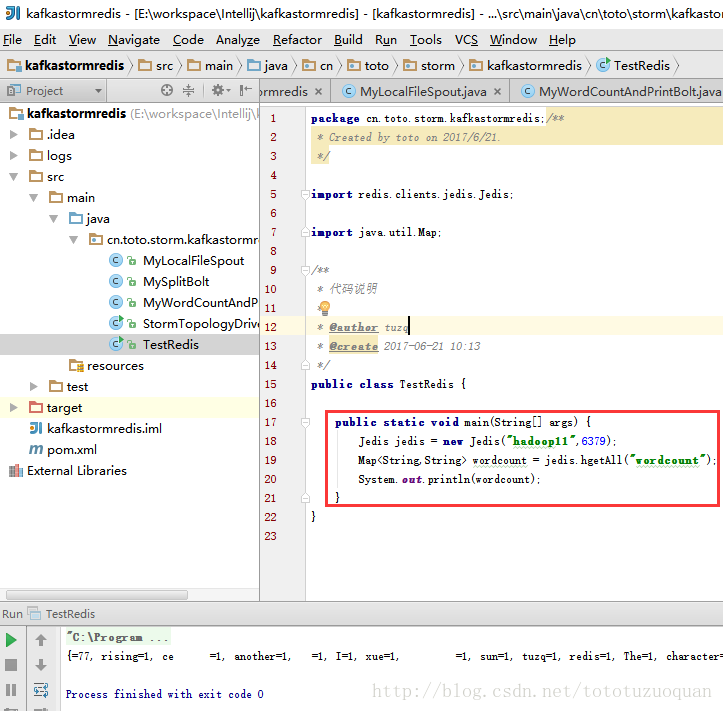















 586
586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











